









1. 核心概念
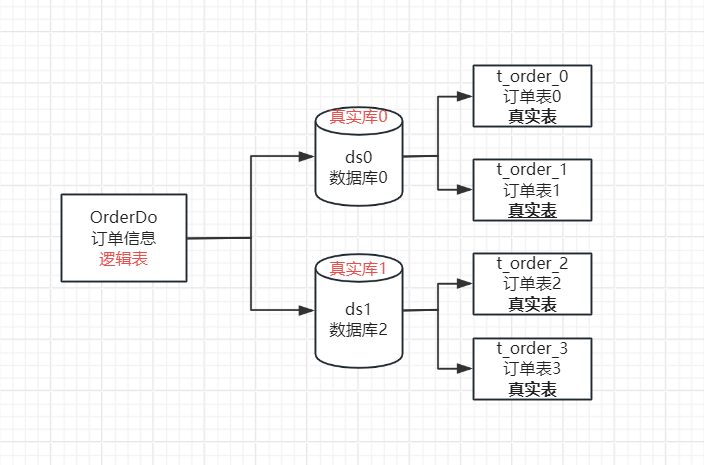
- 虚拟库: ShardingSphere的核⼼就是提供⼀个具备分库分表功能的虚拟库,他是⼀个ShardingSphereDatasource实例。应⽤程序只需要像操作单数据源⼀样访问这个ShardingSphereDatasource即可。示例中,MyBatis框架并没有特殊指定DataSource,就是使⽤的ShardingSphere的DataSource数据源。
- 真实库: 实际保存数据的数据库。这些数据库都被包含在ShardingSphereDatasource实例当中,由ShardingSphere决定未来需要使⽤哪个真实库。示例中,m0和m1就是两个真实库。
- 逻辑表: 应⽤程序直接操作的逻辑表。
- 真实表: 实际保存数据的表。这些真实表与逻辑表表名不需要⼀致,但是需要有相同的表结构,可以分布在不同的真实库中。应⽤可以维护⼀个逻辑表与真实表的对应关系,所有的真实表默认也会映射成为ShardingSphere的虚拟表。
- 分布式主键⽣成算法: 给逻辑表⽣成唯⼀主键。由于逻辑表的数据是分布在多个真实表当中的,所有,单表的索引就⽆法保证逻辑表的ID唯⼀性。因此,在做分库分表时,通常都会独⽴出⼀个⽣成分布式ID的主键⽣成算法。示例中使⽤的SNOWFLAKE雪花算法就是⼀种很常⻅的主键⽣成算法。
- 分⽚策略: 表示逻辑表要如何分配到真实库和真实表当中,分为分库策略和分表策略两个部分。分⽚策略由分⽚键和分⽚算法组成。分⽚键是进⾏数据⽔平拆分的关键字段。分⽚算法则表示根据分⽚键如何寻找对应的真实库和真实表。对id字段取模,就是⼀种简单的分⽚算法。 如果ShardingSphere匹配不到合适的分⽚策略,那就只能进⾏全分⽚路由,这是效率最差的⼀种实现⽅式。
建议先仔细总结⼀下这些概念。虽然这些概念在未来进⾏分库分表时不需要都实现,但是, 通过这些抽象的概念才能构建出⼀个完整的分库分表策略。
2. 垂直分片和水平分片
分库分表通常有两种拆分数据的维度,
⼀是按照业务划分的维度,将不同的表拆分到不同的库当中。这样可以减少每个数据库的数据量以及客户端的
连接数,提⾼查询效率,这种⽅案称为垂直分库。⼆是按照数据分布的维度,将原本存在同⼀张表当中的数据,拆分到多
张⼦表当中。每个⼦表只存储⼀部分数据。这样可以减少每⼀张表的数据量,提升查询效率,这种⽅案称为⽔平分表。
对于部分场景来说,水平分表就能解决数据量过大的问题,但是这并不意味着分库不重要,当用户连接数很大,单库无法维持的时候,分库就显得比较重要了。
3. 入门样例
本来想在此编写ShardingSphere的单字段inline求模取余分片样例,但是发现之前为编写多字段的复合分片,本地编写的基础样例已经被修改得不成样子了,看网上对这类单字段的inline分片已经有很多介绍了,感兴趣的可以搜搜,我在此就不再赘述,下一篇直接介绍ShardingSphere复合分片。

















 5105
5105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









