







什么是数据挖掘
并非所有的信息发现任务都被视为数据挖掘。例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的Web页面,则是信息检索( information retrieval) 领域的任务。虽然这些任务非常重要,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。尽管如此,人们也在利用数据挖掘技术增强信息检索系统的能力。
数据 挖掘是数据库中知识发现(KDD)的一部分。而KDD是将未加工的数据转换成有用的数据的整个过程。
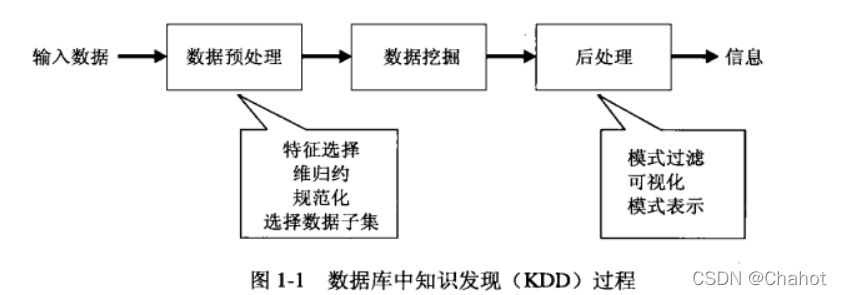
输入数据可以以各种形式存储(平展文件、电子数据表或关系表),并且可以驻留在集中的数据存储库中,或分布在多个站点上。数据预处理(preprocessing) 的目的是将未加工的输入数据转换成适合分析的形式。数据预处理涉及的步骤包括融合来自多个数据源的数据,清洗数据以消除噪声和重复的观测值,选择与当前数据挖掘任务相关的记录和特征。由于收集和存储数据的方式多种多样,数据预处理可能是整个知识发现过程中最费力、最耗时的步骤。“结束循环”(closing the loop) 通常指将数据挖掘结果集成到决策支持系统的过程。例如,在商业应用中,数据挖掘的结果所揭示的规律可以结合商业活动管理工具,从而开展或测试有效的商品促销活动。这样的结合需要后处理( post-processing)步骤,确保只将那些有效的和有用的结果集成到决策支持系统中。后处理使得数据分析者可以从各种不同的视角探查数据和数据挖掘结果。在后处理阶段,还能使用统计度量或假设检验,删除虚假的数据挖掘结果。
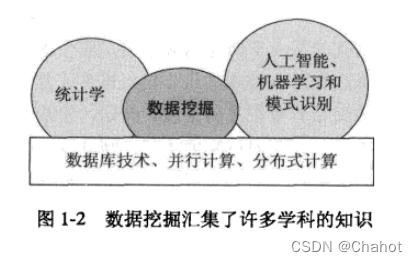
数据挖掘来自于统计学的抽样、估计和假设检验。人工智能,模式识别和机器学习的搜索算法和建模技术,学习理论也在数据挖掘中被广泛应用。数据挖掘也包含了最优化、信号处理、可视化和信息检索等其他计算机领域的知识。特别是数据库系统提供的有效的检索存储和查询处理等技术支持,源于高性能计算的技术在处理海量数据集方面是重要的,分布式技术也能帮助处理海量数据,而且当数据不能集中到一处处理时更加重要。
数据挖掘要解决的问题是什么?
主要是五个大的挑战:
可伸缩: 由于数据产生和收集技术的进步,数吉字节、数太字节甚至数拍字节”的数据集越来越普遍。如果数据挖掘算法要处理这些海量数据集,则算法必须是可伸缩的(scalble)。 许多数据挖掘算法使用特殊的搜索策略处理指数级搜索问题。为实现可伸缩可能还需要实现新的数据结构,才能以有效的方式访问每个记录。例如,当要处理的数据不能放进内存时,可能需要非内存算法。使用抽样技术或开发并行和分布算法也可以提高可伸缩程度。
高维性现在, 常常遇到具有成百上千属性的数据集,而不是几十年前常见的只具有少量属性的数据集。在生物信息学领域,微阵列技术的进步已经产生了涉及数千特征的基因表达数据。具有时间或空间分量的数据集也经常具有很高的维度。例如,考虑包含不同地区的温度测量结果的数据集,如果在-一个相当长的时间周期内反复地测量,则维度(特征数)的增长正比于测量的次数。为低维数据开发的传统的数据分析技术通常不能很好地处理这样的高维数据。此外,对于某些数据分析算法,随着维度(特征数)的增加,计算复杂性迅速增加。
异种数据和复杂数据: 通常, 传统的数据分析方法只处理包含相同类型属性的数据集,或者是连续的,或者是分类的。随着数据挖掘在商务、科学、医学和其他领域的作用越来越大,越来越需要能够处理异种属性的技术。近年来,已经出现了更复杂的数据对象。这些非传统的数据类型的例子有:含有半结构化文本和超链接的Web页面集、具有序列和三维结构的DNA数据、包含地球表面不同位置上的时间序列测量值(温度、气压等)的气象数据。为挖掘这种复杂对象而开发的技术应当考虑数据中的联系,如时间和空间的自相关性、图的连通性、半结构化文本和XML文档中元素之间的父子联系。
数据的所有权与分布: 有时, 需要分析的数据并非存放在-一个站点,或归属-一个机构,而是地理上分布在属于多个机构的资源中。这就需要开发分布式数据挖掘技术。分布式数据挖掘算法面临的主要挑战包括: (1) 如何降低执行分布式计算所需的通信量? (2)如何有效地统- -从多个资源得到的数据挖掘结果? (3)如何处理数据安全性问题?
非传统的分析: 传统的统计 方法基于一种假设——检验模式,即提出一种假设,设计实验来收集数据,然后针对假设分析数据。但是,这一过程劳力费神。当前的数据分析任务常常需要产生和评估数千种假设,因此需要自动地产生和评估假设,这促使人们开发了一些数据挖掘技术。此外,数据挖掘所分析的数据集通常不是精心设计的实验的结果,并且它们通常代表数据的时机性样本(opportunistic sample),而不是随机样本(random sample)。而且,这些数据集常常涉及非传统的数据类型和数据分布。
数据挖掘的任务
任务分为两大类,分别是预测类和描述类任务。
预测任务:这些任务的目标都是根据其他属性的值进而预测特定属性的值,被预测的属性一般称为目标变量或因变量,而用来做预测的属性一般称为说明变量或者自变量。
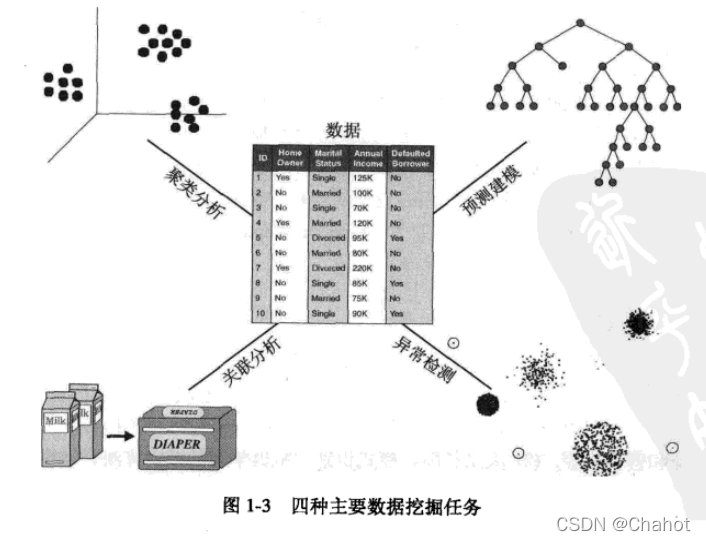
四种数据挖掘的主要任务如图所示,由于本章是导论不会他们进行展开讲解,会在后续更新中完善。
预测建模(predictive modeling)涉及以说明变量函数的方式为目标变量建立模型。有两类预测建模任务:分类(classification), 用于预测离散的目标变量;回归(regression), 用于预测连续的目标变量。例如,预测-一个Web用户是否会在网上书店买书是分类任务,因为该目标变量是二值的,而预测某股票的未来价格则是回归任务,因为价格具有连续值属性。两项任务目标都是训练-一个模型, 使目标变量预测值与实际值之间的误差达到最小。预测建模可以用来确定顾客对产品促销活动的反应,预测地球生态系统的扰动,或根据检查结果判断病人是否患有某种疾病。
下面通过例题对这四类进行简略的说明
预测建模
如图所示,聚类就是把数据按照他们的属性进行分类归纳,当归纳结果出现后,总会有一种趋势,这种趋势可以用于区分因为相同变量的不同属性值而导致我们可以区分拥有类似特性的属性产物。而且这里的聚类是离散的,不连续的,也就说这里本质是分类。
关联分析
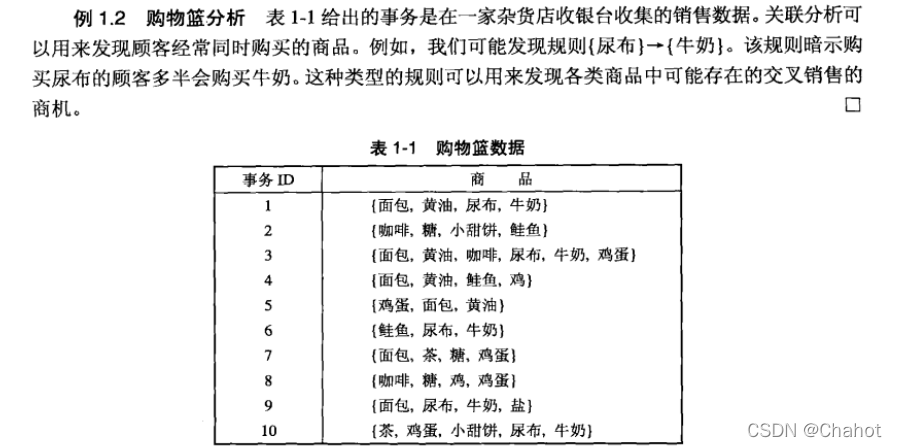
用来描述数据中强关联特征的模式,所发现的模式通常用蕴含规则或特征子集的形式表示。
聚类分析

发现密切相关的观测值族群,使得能够区分它们的特征明显化。找出最具影响力的特征值是这里的一个步骤。
异常检测
异常检测(anomaly detection)的任务是识别其特征显著不同于其他数据的观测值。这样的观测值称为异常点(anomaly) 或离群点(outlier)。 异常检测算法的目标是发现真正的异常点,而避免错误地将正常的对象标注为异常点。换言之,- -个好的异常检测器必须具有高检测率和低误报率。主要用于应用的检测网络攻击、欺诈、不勋章模式,生态系统扰动等。

如图所示,这个例子应该很好理解,当我们使用网上支付时,当你的转账目标是你之前从未转账过的目标且转账额度比较大时,此时会除法异常机制,此时会中断交易,银行或者APP管理员会主动联系你,确认并提醒网络诈骗。
















 2395
2395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











