









一、概念
Q-Learning是一种基于值的强化学习方法,用于解决有限马尔可夫决策过程(Markov Decision Process,MDP)。它使模型能够通过采取正确的操作来迭代学习和改进,通过强化学习的状态-动作-奖励-状态-动作形式,训练方案遵循一个模型来采取正确的动作。
二、原理
Q-Learning的核心是Q值(Q-function),用于估计在给定状态下采取特定行动后可以获得的未来总回报。Q值可以表示为Q(s, a),其中s表示状态,a表示行动。通过学习和更新这些Q值,智能体(agent)可以选择在给定状态下执行最佳行动。Q-Learning的原理公式基于贝尔曼等式(Bellman equation),它描述了当前状态和行动的Q值与下一状态的Q值之间的关系:
其中,s表示当前状态;a表示当前行动;r表示从状态s采取行动a获得的即时奖励;是折扣因子,取值范围为[0, 1],用于平衡即时奖励和未来奖励;s'是采取行动a后进入的下一个状态;max_a'则表示在下一个状态s'下,对所有可能行动a'的Q值取最大值。Q值的更新公式为:
其中,是学习率,控制更新的步长。Q-Learning的实现流程通常包括以下几个步骤:
- 初始化Q表:创建一个Q表,用于跟踪每个状态下的每个动作和相关进度。Q值表通常是一个二维数组(或更高维度的数组,取决于状态和动作的数量),其中行表示不同的状态,列表示不同的动作,每个元素(或称为Q值)表示在特定状态下采取特定动作所能获得的预期回报(这个回报是长期的,考虑了未来的折扣奖励)。通常将所有Q值初始化为0。
- 选择动作:根据当前状态s,选择一个动作a。这通常通过ε-greedy策略实现,即以ε的概率随机选择一个动作,或者以1-ε的概率选择具有最高Q值的动作。通过这种方式,智能体能够在探索新行为和利用已知最佳行为之间做出平衡。随着训练的进行,探索率通常会逐渐减小,以便智能体更多地依赖于其已学习的策略(即利用),而不是继续随机探索。
- 执行动作:执行选定的动作a,观察即时奖励r和下一个状态s'。
- 更新Q值:使用贝尔曼等式更新Q值。
- 更新状态:将状态更新为下一个状态s'。
- 重复步骤:重复前四个步骤,直到达到终止条件(例如达到最大迭代次数或达到目标状态)。
三、python实现
这里,我们创建一个5x5的格子世界,其中左上角是起点(0,0),右下角是终点(4,4)。智能体可以从起点出发,通过上、下、左、右四个方向移动,目标是到达终点。在移动过程中,智能体可能会遇到墙壁(不可移动的位置),此时会获得-1的奖励。到达终点时,智能体会获得1的奖励。通过Q-Learning算法,智能体可以学习到从起点到达终点的最优路径。
import random
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 定义网格世界的参数
grid_size = 5 # 网格的大小
num_episodes = 1000 # 训练回合数
max_steps_per_episode = 100 # 每个回合的最大步数
learning_rate = 0.1 # 学习率
discount_factor = 0.9 # 折扣因子
exploration_rate = 1.0 # 初始探索率
exploration_decay = 0.995 # 探索率衰减
exploration_min = 0.01 # 最小探索率
# 定义动作(上、下、左、右)
actions = ['up', 'down', 'left', 'right']
# 初始化Q表
Q = np.zeros((grid_size, grid_size, 4))
# 定义状态转换函数
def get_next_state(state, action):
x, y = state
if action == 'up':
x = max(x - 1, 0)
elif action == 'down':
x = min(x + 1, grid_size - 1)
elif action == 'left':
y = max(y - 1, 0)
elif action == 'right':
y = min(y + 1, grid_size - 1)
return (x, y)
# 定义网格世界
grid = np.array([
[0, 0, 0, 0, 0],
[-1, -1, 0, -1, 1],
[0, 0, 0, 0, 0],
[1, -1, 0, -1, 1],
[0, 0, 0, 0, 0]
])
# 定义奖励函数
def get_reward(state):
x, y = state
if grid[x, y] == -1: # 墙壁
return -1
if x == grid_size - 1 and y == grid_size - 1: # 终点
return 1
return 0
# Q-learning算法
for episode in range(num_episodes):
state = (0, 0) # 起点
for step in range(max_steps_per_episode):
# ε-贪婪策略选择动作
# 首先,生成一个0到1之间的随机浮点数,并将其与探索率(exploration_rate)进行比较。
# 探索率是一个介于0和1之间的参数,用于控制智能体进行探索的概率。
if random.uniform(0, 1) < exploration_rate:
# 如果上述条件为真(即生成的随机数小于探索率),则执行探索
# 从可用的动作集合中随机选择一个动作。
action = random.choice(actions) # 随机选择动作
else:
# 如果上述条件为假(即生成的随机数大于或等于探索率),则执行利用
# 根据当前状态(state)下的Q值表(Q),选择具有最高Q值的动作。
# Q值表记录了在不同状态下采取不同动作所预期的回报。
# 选择最高Q值的动作意味着智能体根据当前知识选择最佳行为。
action = actions[np.argmax(Q[state])] # 选择具有最高Q值的动作
# 执行动作并获取下一个状态和奖励
next_state = get_next_state(state, action)
reward = get_reward(next_state)
# 更新Q表
best_next_action = np.argmax(Q[next_state[0], next_state[1]])
td_target = reward + discount_factor * Q[next_state[0], next_state[1], best_next_action]
td_error = td_target - Q[state[0], state[1], actions.index(action)]
Q[state[0], state[1], actions.index(action)] += learning_rate * td_error
# 更新状态
state = next_state
# 检查是否到达终点
if state == (4, 4):
break
# 更新探索率
exploration_rate = max(exploration_min, exploration_rate * exploration_decay)
# 打印最终的Q表
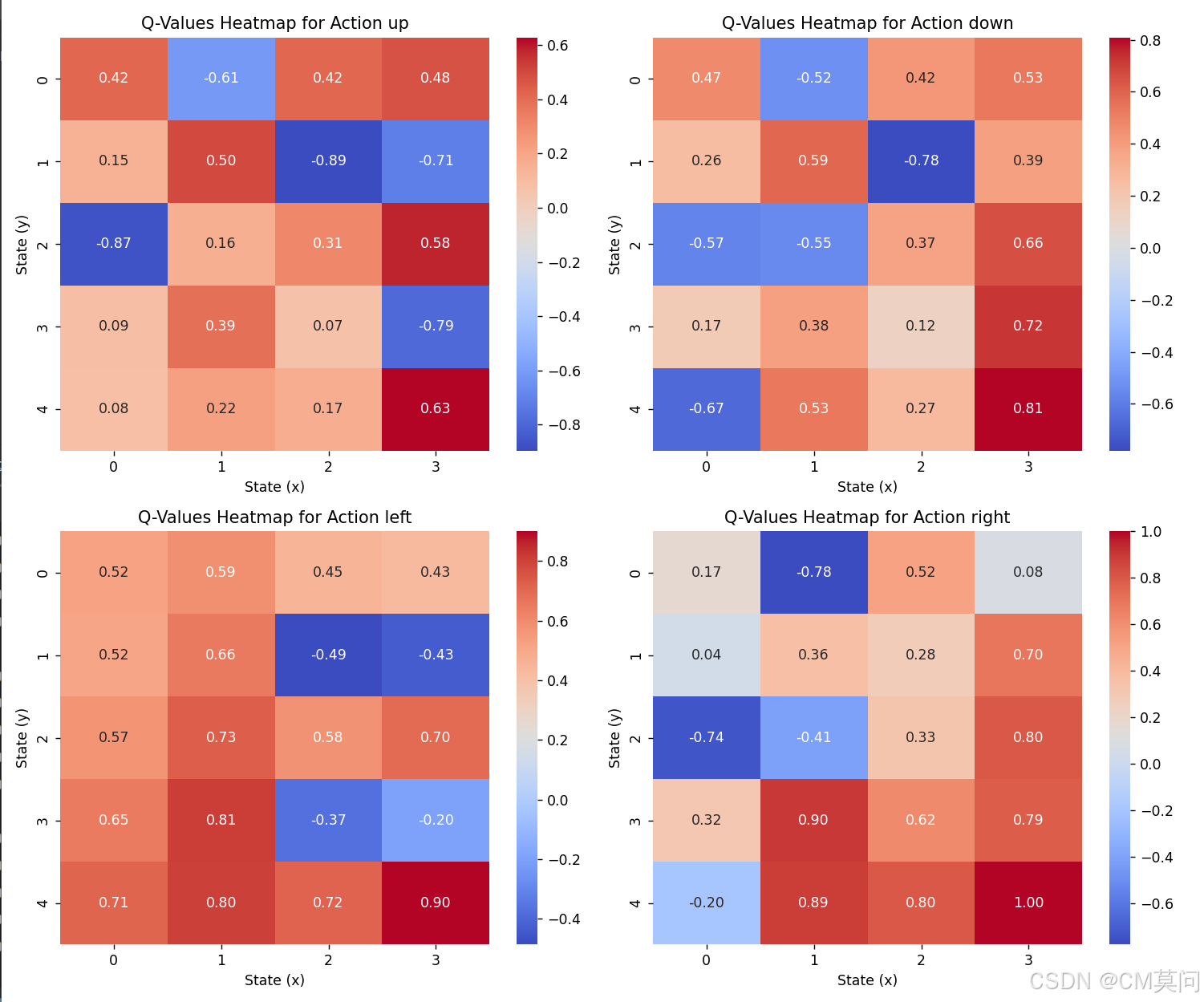
# Q值表中的数字:
## 每个子数组(5x4的二维数组)代表智能体在特定行(即y坐标)中特定列(即x坐标)的状态,Q值表的维度(5,5,4)即表示(5行,5列,当前动作)。
## 每个子数组中的数字代表在该状态下采取不同动作(这里是四个可能的动作,因为通常假设在网格中有四个方向可以移动:上、下、左、右)的Q值。
## Q值越高,表示采取该动作后获得的累积奖励越高(或预期的未来回报越高)。
print("Q表:")
print(Q)
# 绘制每个动作的热力图
actions_cnt = 4 # 4个动作
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
for i, ax in enumerate(axes.flat):
if i < actions_cnt:
sns.heatmap(Q[:, i, :], annot=True, cmap='coolwarm', fmt='.2f', ax=ax)
ax.set_title('Q-Values Heatmap for Action {}'.format(actions[i]))
ax.set_xlabel('State (x)')
ax.set_ylabel('State (y)')
else:
# 隐藏多余的轴(如果有的话)
fig.delaxes(ax)
# 调整布局以防止重叠
plt.tight_layout()
plt.show()
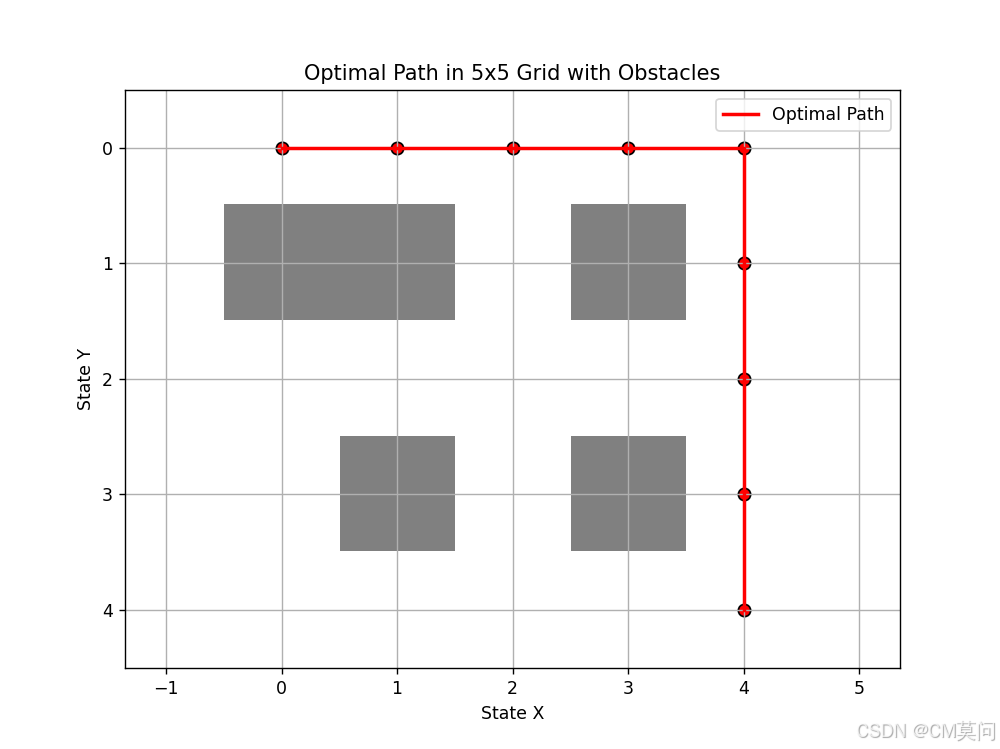
# 测试智能体是否学会到达终点
state = (0, 0)
path = [state]
while state != (4, 4):
action = np.argmax(Q[state[0], state[1]])
state = get_next_state(state, actions[action])
path.append(state)
print("找到的路径:")
print(path)
path = np.array(path)
# True表示障碍物,False表示可通过的路径
obstacles = np.array([
[True, True, True, True, True],
[False, False, True, False, True],
[True, True, True, True, True],
[True, False, True, False, True],
[True, True, True, True, True]
])
# 绘制环境
plt.figure(figsize=(8, 6))
plt.imshow(obstacles, cmap='gray', interpolation='none', alpha=0.5) # 使用灰色表示障碍物,并设置透明度
plt.plot(path[:, 1], path[:, 0], 'r-', linewidth=2, label='Optimal Path') # 红色线条表示最优路径
plt.scatter(path[:, 1], path[:, 0], c='r', s=50, edgecolors='k') # 在路径点上添加红色圆点,边缘为黑色
plt.title('Optimal Path in 5x5 Grid with Obstacles')
plt.xlabel('State X') # 注意:这里Y轴和X轴是反转的,因为imshow默认以(row, col)为坐标
plt.ylabel('State Y')
plt.grid(True)
plt.legend()
plt.axis('equal') # 确保网格单元是正方形的
plt.show()可视化Q值表中每个动作对应的Q值,可以清晰地得出最优的动作路径(Q值回报最高)。
下图是当前模型学习到的最佳路径,不同的训练参数可能会得到不同的最优路径,但是最终模型都能够避开障碍物并选择最合适的路径,且不会绕远路,这就是Q-Learning的魅力!
四、总结
在强化学习中,智能体(agent)在选择动作时不仅考虑当前立即获得的奖励(即时奖励),还考虑这些动作对未来状态的影响以及未来从这些状态中获得的奖励。这是强化学习与传统监督学习的一个关键区别,因为在监督学习中,通常只关注当前输入对应的正确输出或标签。
为了处理这种长期回报,强化学习引入了折扣因子(discount factor,通常用γ表示)来决定未来奖励的当前价值。未来的奖励会被乘以折扣因子的某个幂次(幂次取决于奖励发生的时间步),从而降低其当前价值。这样做既可以应对未来的不确定性(比如智能体可能无法到达预期的未来状态),同时也能避免智能体即时满足的偏好(即智能体倾向于获得当前的奖励而不是等待未来的奖励)。

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









