









Layer-Wise Relevance Propagation for Neural Networks with Local Renormalization Layers主要介绍了一种将LRP扩展到非线性神经网络的方法。LRP是从模型输出开始,反向传播,直到模型输入开始为止,对由输入特征导致其预测结果的解释,文章中主要探究图片像素点与最终结果的相关性。
- 神经网络中的LRP(Layer-Wise Relevance Propagation)
式中 是神经元
的输出,
是神经元
的激活函数,
是神经元
到神经元
的连接权重,
为连接偏差;
式中(pixel-wise relevance score) 用于衡量像素点对预测结果的影响,
表示某类在图片中存在的证据,
表示某类在图片中不存在的证据,
表示对图片
的预测结果,预测结果可视为每个像素点对应
的总和。找出图片
中所有像素点的
可将图片
可视化为热图,如下:

(图片1)
假设已知第层神经元
的相关性
,可将该相关性
分解到第
层的所有神经元上,公式如下:
第层神经元
的相关性
可理解为,第
层中所有神经元的相关性分解后再进行求和,公式如下:
LRP传播机制示例如如下,有助于理解上述两个公式。
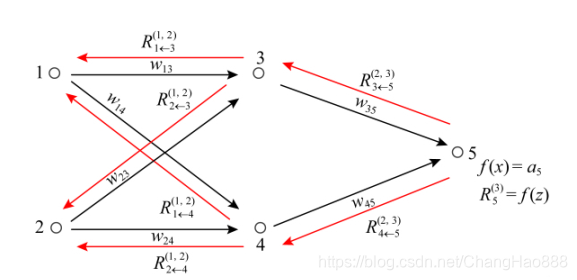
(图片2)LRP传播机制示例图
计算方式有两种:
与
如下:
式中,
,笔者认为文章中给出的
不是很好理解,稍作修改后如下:
为第
层神经元
对第
层神经元
的加权激活,
为第
层所有神经元对第
层神经元
的加权激活。
如下:
式中“+”与“-”分别表示正值部分与负值部分,即上述公式将正负加权激活分开进行处理。
含义如下:
若第层某个神经元
对第
层神经元的一个神经元
做出了主要贡献,那么第
层神经元
应该占第
层神经元
的相关性
的较大份额,即神经元
收集它对后一层所连接的神经元
的贡献。
的两种计算方法
与
实际上都是将第
层神经元
的相关性
按照比例分配给第
层神经元
从而求得相关系数
,因此在LRP中,存在以下的结构:
with
式中或
,对于
,笔者认为应该是
,因为式中的
是一个较小的实数。
- 将LRP运用到非线性神经网络
先考虑一种情况:神经元的输出无法用等式
表示,设神经元
的输出为
,式中
表示神经元
前一层神经元对神经元
的输入,现将
在参考点
处进行一阶泰勒展开得如下式子:
前一层神经元对后一层神经元
的加权激活如下:
上式可理解为,将泰勒分解中的零阶项平均分配后,再加上前一层对应神经元
输入的偏导值,即为前一层神经元
对后一层神经元
的加权激活。按照泰勒分解求得
后,可利用本文上述所介绍的
或者
进行逐层相关性的求解,最终可计算出
(pixel-wise relevance score)。
- 将LRP运用到Local Renormalization Layers
因Local Renormalization Layers在深度神经网络中表现出了良好的性能,所以在这里介绍将LRP运用到Local Renormalization Layers中,使其具有可解释性。
将神经网络中某一层设置为Local Renormalization Layers,该层中神经元定义如下:
显然,Local Renormalization Layers为非线性,可将LRP运用到非线性神经网络的方法应用到此处。
将在参考点
处进行泰勒展开可得如下式子:
对求偏导,如下:
,此处
,此处
将上面两个式中,稍作整理可得,
对于输出为的神经元来说,其输入应该是
,若只有输出为
的神经元触发输出为
的神经元时,其输入应该是
,即对于输出为
的神经元,我们选择在只有输出为
的神经元触发输出为
的神经元时候展开,即在点
展开,如下:
上式则意味着的泰勒一阶展开式中一阶项对于
的近似没有贡献值,这是我们不希望看到的,故稍作修改,如下:
然后根据求得的可通过如下式子计算前一层神经元
对后一层神经元
的加权激活
,
最后可利用本文在最前面所介绍的或者
进行逐层相关性的求解,最终可计算出
(pixel-wise relevance score)。
笔者水平有限,难免存在理解不当之处,欢迎批评指正,联系邮箱:changhao1997@foxmail.com
- 参考文献
- Layer-Wise Relevance Propagation for Neural Networks with Local Renormalization Layers
- 赵新杰. 深度神经网络的可视化理解方法研究[D].哈尔滨工程大学,2018.
- 陈珂锐,孟小峰.机器学习的可解释性[J].计算机研究与发展,2020,57(09):1971-1986.

















 8165
8165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









