







Q:bert分词步骤
1:构建N * N 的相关性矩阵,计算相邻两个字的相关性,低的话(<阈值)就切割。

2:将A词进行mask计算出A的embedding,然后将AB两个词一起mask,计算出A的embedding,算两个embedding的距离。
3:距离“远” 表示临词的影响比较大。
例子:
1:比如['我是中国人]
2:第一次先mask’我’,然后mask’我是’,计算距离得到“我”的影响D1。
3:然后mask’是’,根据mask’我是’,计算距离得到“是”的影响D2。
4:根据这三个判断‘是’ 是否需要切开。用D1D2的平均距离代表切割前后对两个字影响的大小,小于阈值则切开。


Q:bert分词代码(bert4keras)
1:下载BERT模型 及 配置,bert_config.json / bert_model.ckpt / vocab.txt
2:建立分词器 + 建立模型,加载权重
3:文本编码,生成 token_ids, segment_ids
4:根据文本长度,将token_id复制【2 * length - 1】份,以为token首位为‘/’
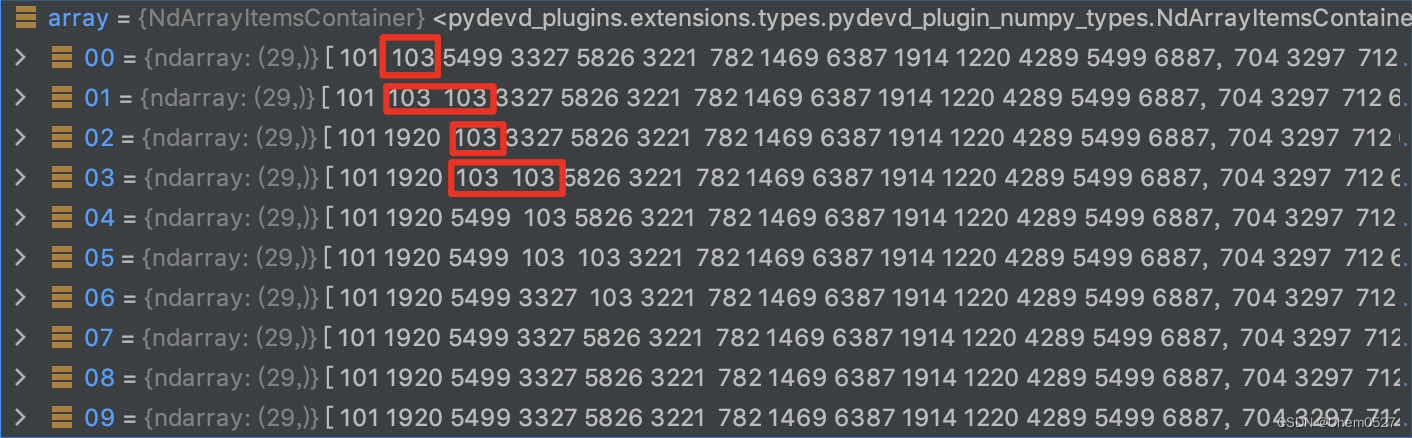
5:将mask符号位103进行填补
注意技巧:第一行1个103,第二行2个103,第三行1个103…,按列看,基本都是3个103连着。
6:输入batch_token_ids,batch_segment_ids进行预测
7:用欧式距离去计算两个embedding的距离,
先将token_ids 复制 (2 * length - 1) 份。
#! -*- coding: utf-8 -*-
# BERT做无监督分词
# 介绍:https://kexue.fm/archives/7476
import numpy as np
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.snippets import uniout
# 1:下载BERT模型 及 配置
config_path = '/root/kg/bert/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/root/kg/bert/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/root/kg/bert/chinese_L-12_H-768_A-12/vocab.txt'
# 2: 建立分词器 + 建立模型,加载权重
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
# 3: 文本编码,生成 token_ids, segment_ids
text = u'大肠杆菌是人和许多动物肠道中最主要且数量最多的一种细菌'
token_ids, segment_ids = tokenizer.encode(text)
length = len(token_ids) - 2
# 4: 根据文本长度,将token_id复制【2 * length - 1】份,以为token首位为‘/’
batch_token_ids = np.array([token_ids] * (2 * length - 1))
batch_segment_ids = np.zeros_like(batch_token_ids)
# 5: 将mask符号位103进行填补
for i in range(length):
if i > 0:
batch_token_ids[2 * i - 1, i] = tokenizer._token_mask_id
batch_token_ids[2 * i - 1, i + 1] = tokenizer._token_mask_id
batch_token_ids[2 * i, i + 1] = tokenizer._token_mask_id
# 6: 输入batch_token_ids,batch_segment_ids进行预测
vectors = model.predict([batch_token_ids, batch_segment_ids])
# 7: 用欧式距离去计算两个embedding的距离,
def dist(x, y):
"""距离函数(默认用欧氏距离)
可以尝试换用内积或者cos距离,结果差不多。
"""
return np.sqrt(((x - y)**2).sum())
threshold = 8
word_token_ids = [[token_ids[1]]]
for i in range(1, length):
# “大肠杆菌是人和许多”
# 比如i=2
# d1 = vectors[4, 3]与vectors[3, 3]的距离,[4,3]是单独mask“菌”字emb,[3, 3]是mask"杆菌"后菌的emb
d1 = dist(vectors[2 * i, i + 1], vectors[2 * i - 1, i + 1])
# d2 = vectors[2, 2]与vectors[3, 2]的距离,[2,2]是单独mask“杆”字emb,[3, 2]是mask"杆菌"后杆的emb
d2 = dist(vectors[2 * i - 2, i], vectors[2 * i - 1, i])
# “杆”与“菌”之间平均距离
d = (d1 + d2) / 2
if d >= threshold:
# 如果距离大,则表明不能分开
word_token_ids[-1].append(token_ids[i + 1])
else:
word_token_ids.append([token_ids[i + 1]])
words = [tokenizer.decode(ids) for ids in word_token_ids]
print(words)
# 结果:[u'大肠杆菌', u'是', u'人和', u'许多', u'动物', u'肠道', u'中最', u'主要', u'且数量', u'最多', u'的', u'一种', u'细菌']

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









