









单机存储引擎就是哈希表、B树等数据结构在机械磁盘和SSD等持久化介质上的实现。
单机存储系统是单机存储引擎的一种封装,对外提供文件、键值、表格或者关系模型,单机存储系统的理论来源于关系数据库。
哈希存储引擎是哈希表的持久化实现。
B树存储引擎是B树的持久化实现。
LSM树(Log structure merge tree)存储引擎采用批量转储技术来避免磁盘随机写人。
一、CPU架构
CPU架构有两种:SMP和NUMA
1、SMP:
经典的多CPU架构为对称多处理结构(symmetric Multiprocessing,SMP)
在一个云计算机上汇集了一组处理器,它们之间对称工作,无主次无从属关系,共享相同的物理内存及总线。
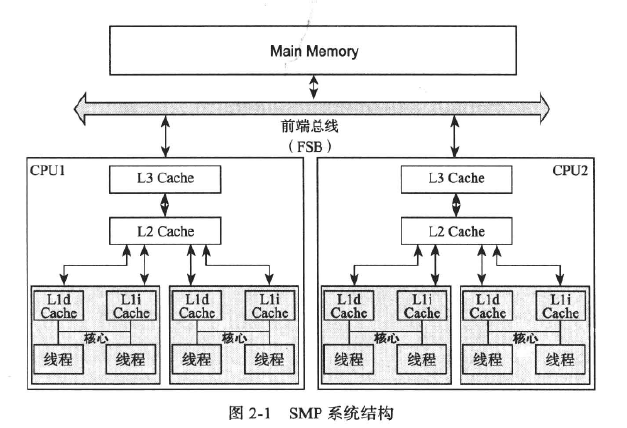
主要特征:共享。
系统中所有资源(CPU、内存、IO)都是共享的,由于多CPU对前端总线的竞争,SMP的扩展能力非常有限。
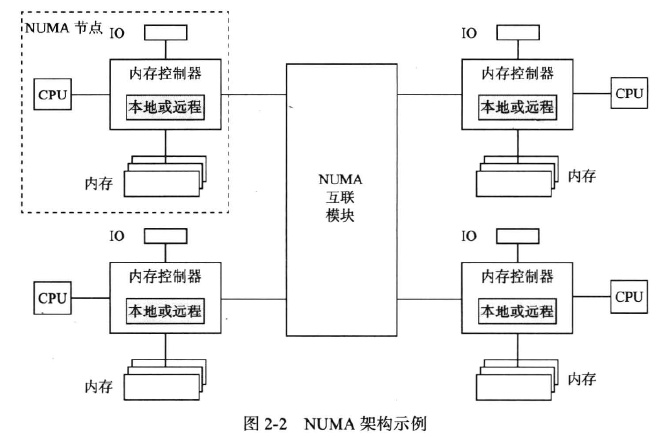
2、NUMA
主流服务器架构一般为NUMA(非一致存储访问)架构。
具有多个NUMA节点,每个NUMA节点是一个SMP结构。
二、单机存储系统瓶颈
存储系统的性能瓶颈一般在于IO性能。
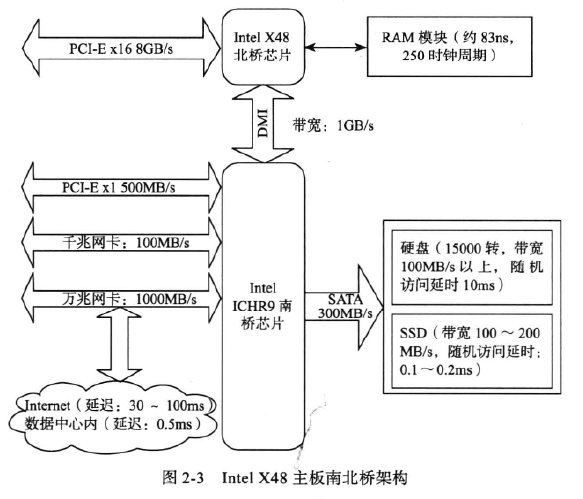
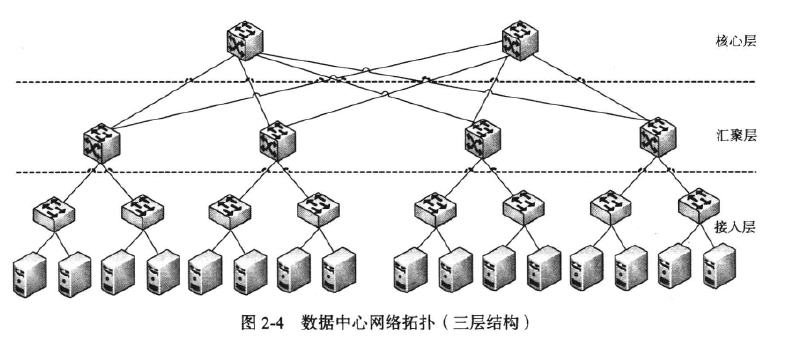
同一个数据中心内部的传输延时是比较小的,网络一次来回的时间在1毫秒之内。
数据中心之间的传输延迟是很大的,取决于光在光纤中的传输时间。
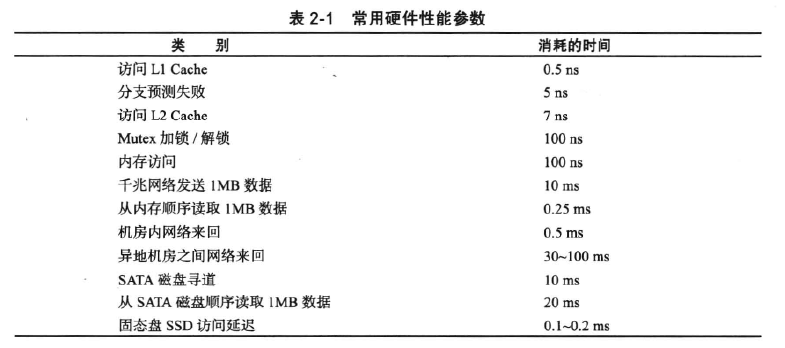
存储系统的性能瓶颈主要在于磁盘随机读写。
设计存储引擎的时候会针对磁盘的特性做很多的处理,比如将随机写操作转化为顺序写,通过缓存减少磁盘随机读操作。
固态磁盘用来做缓存或者性能要求较高的关键业务。
三、单机存储引擎
存储引擎是存储系统的发动机,直接决定了存储系统能够提供的性能和功能。
常见的存储引擎:哈希、B树、LSM树
1、哈希
Bitcask 是一个基于哈希表结构的键值存储系统,它仅支持追加操作。
每个文件有一定的大小限制,当文件增加到相应的大小时,就会产生一个新的文件,老的文件只读不写。
在任意时刻,只有一个文件是可写的,用于数据追加,称为活跃数据文件。
其他已经达到大小限制的文件,称为老数据文件。
每个写操作总共需要进行一次顺序的磁盘写人和一次内存操作。
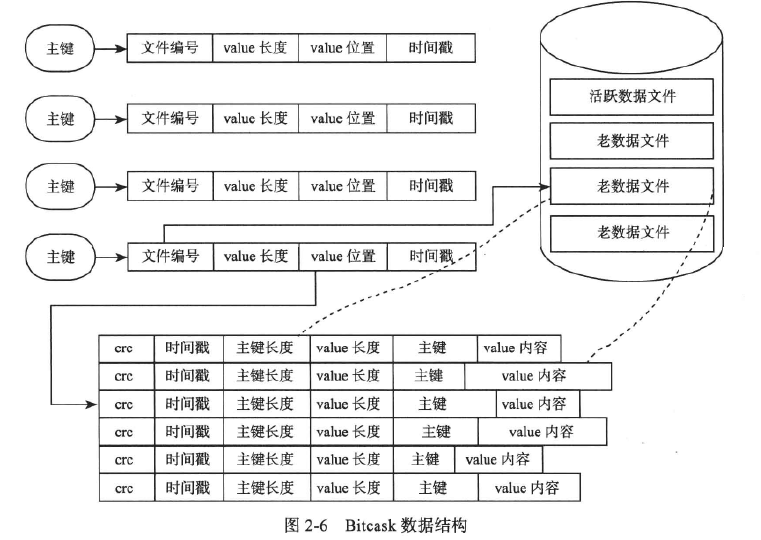
内存中存储了主键和value的索引信息。
磁盘文件中存储了主键和value的实际内容。
定期执行合并操作以实现垃圾回收。
合并操作:将所有老数据文件中的数据扫描一遍并生成新的数据文件。
对同一个key的多个操作以只保留最新一个的原则进行删除,合并后,新生成的数据文件就不再有冗余数据了。
Bitcask通过索引文件来提高重建哈希表的速度。
索引文件:将内存中的哈希索引表转储到磁盘生成的结果文件。
Bitcask对老数据文件进行合并操作时,会产生新的数据文件和产生一个索引文件,索引文件记录每一条记录的哈希索引信息。
2、B树存储引擎
B树存储引擎支持随机读取和支持范围扫描。
叶子节点保存每行的完整数据,非叶子节点保存索引信息。
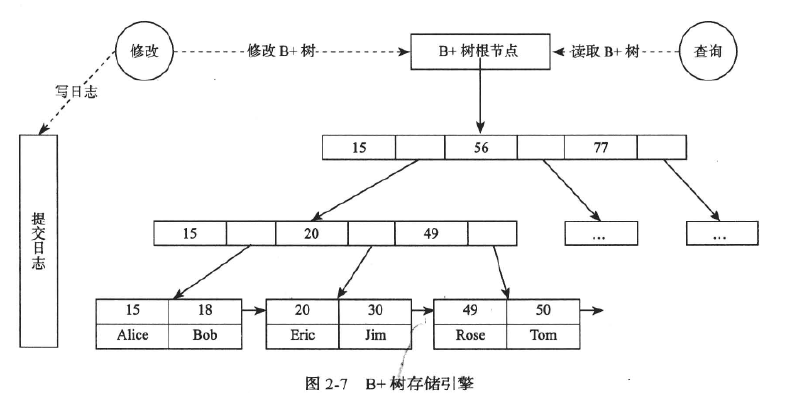
B+树的根节点是常驻内存。
缓冲区管理器负责将可用的内存划分成缓冲区,缓冲区是与页面同等大小的区域,磁盘块的内容可以传送到缓冲区中。
缓冲区管理器的关键在于替换策略。
LRU算法淘汰最长时间没有读或者写过的块。
现代数据库一般采用LIRS算法,将缓冲池分为两级,数据首先进人第一级,如果数据在较短的时间内被访问两次或者以土,则成为热点数据进入第二级,每一级内部还是采用LRU替换算法。
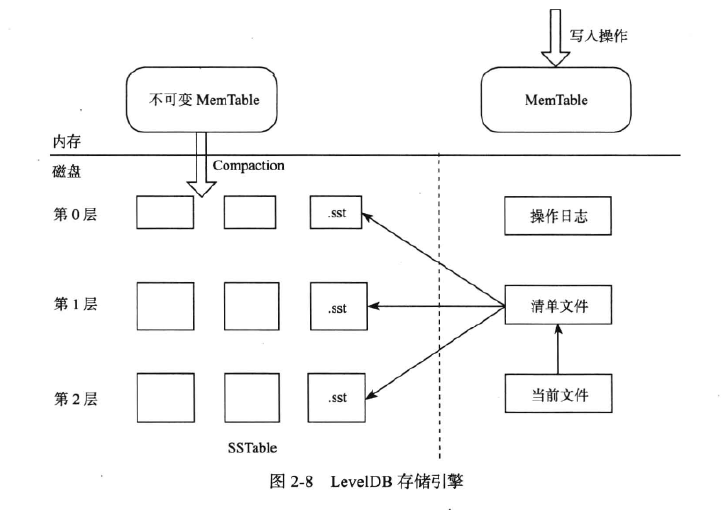
2、LSM树存储引擎
将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写人磁盘,读取时需要合并磁盘中的历史数据和内存中最近的修改操作。
有效地规避了磁盘随机写人问题,读取时可能需要访问较多的磁盘文件
4、数据模型
存储引擎相当于存储系统的发动机,数据模型就是存储系统的外壳。
存储系统的数据模型主要包括三类:文件、关系以及键值
4.1、文件模型和对象模型
文件系统以目录树的形式组织文件
POSIX( Portable Operating System interface)是应用程序访问文件系统的api标准,定义文件系统存储接日及操作集。定义了读写操作语义。
要求读写并发时能够保证操作的原子性。
POS IX标准适合单机文件系统
对象模到与文件模型比较类似,与文件模型不同的是,对象模型要求对象一次性写入到系统,只能删除整个对象,不允许修改其中某个部分。
每个关系是一个表格,由多个元组(行)构成,而每个元组又包含多个属性(列)。关系名、属性名以及属性类型称作该关系的模式(schema)。
SQL还包括两个重要的特性:索引以及事务。
数据库索引用于减少SQL执行时扫描的数据量,提高读取性能。
数据库事务则规定了各个数据库操作的语义,保证了多个操作并发执行时的ACIO特性(原子性、一致性、隔离性、持久性),
4.2键值模型和表格模型
大量的NoSQL系统采用了键值模型
key-value模型过于简单,
支持的应用场景有限,NaSQL系统中使用比较广泛的模型是表格模型。表格模型弱化了关系模型中的多表关联,支持基于单表的简单操作
表格模型除了支持简单的基于主键的操作,还.支持范围扫描。也支持基于列的操作。
表格模型一般不支持多表关联操作,事务操作支持也比较弱
表格模型往往还支持无模式特性,
5、事务与并发控制
事务ACID属性
事务分为3种类型:读事务,写事务以及读写混合事务。
并发控制,数据库锁
锁也分为两种类型:读锁以及写锁,允许对同一个元素加多个读锁,但只允许加一个写锁,且写事务将阻塞读事务。
解决死锁的思路主要有两种:第一种思路是为每个事务设置一个超时时间,超时后自动回滚。第二种思路是死锁检测:死锁出现的原因在于事务之间互相依赖,依赖关系构成一个环路。检测到死锁后叮以通过回滚其中某些事务来消除循环依赖。
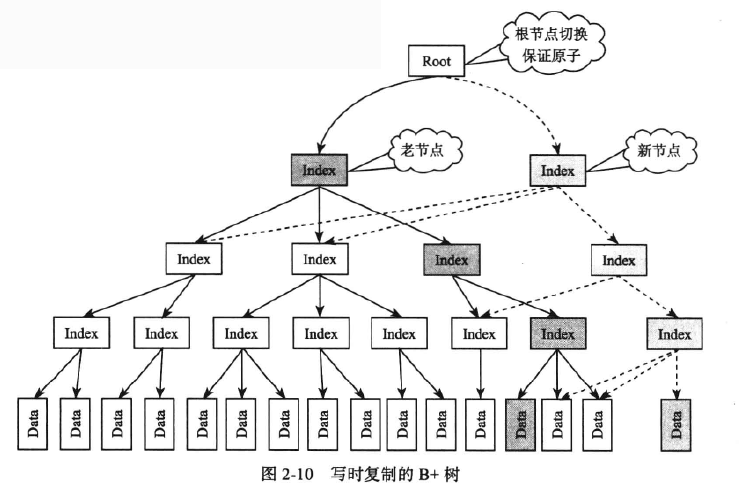
写时复制
写时复制(copy-on-write)读操作不用加锁,极大地提高了读取性能。
写操作成本高,多个写操作之间是互斥的同一时刻只允许一个写
多版本并发控制
C能够实现读事务不加锁。对每行数据维护多个版本,无论事务的执行时间有多长,MVCC能够提供与事务开始时刻相一致的数据。提高了系统的并发度。定期删除不再需要的版本,及时同收空间。
6、故障恢复
数据库系统以及其他的分布式存储系统一般采用操作日志
操作日志分为回滚日志 、重做日志以及UNDO/REDO日志。
7、操作日志
保证数据库的一致性,数据库操作需要持久化到磁盘,通过操作日志顺序记录每个数据库操作并在内存中执行这些操作,内存中的数据定期刷新到磁盘,实现将随机写请求转化为顺序写请求。
关系数据库系统一般采用UNDO/REDO日志
REDO的操作日志日志的约束规则为:必须先刷人到磁盘中在修改内存中的元素X之前,要确保与这一修改相关。
成组提交:Group Commit技术是一种有效的优化手段。REDO日志首先写人到存储系统的日志缓冲区中。
成组提交技术保证REDO日志成功刷人磁盘后才返回写操作成功。这种做法可能会牺牲写事务的延时,但大大提高了系统的吞吐量。
检查点,需要将内存中的数据定期转储到磁盘
8、数据压缩
数据压缩分为有损压缩与无损压缩两种。
有损从缩算法压缩比率高,但数据可能失真,一般用于床缩图片、音频、视频。
无损版缩算法能够完全还原原始数据,
压缩算法的核心是找重复数据,列式存储技术通过把相同列的数据组织在一起。
压缩算法
压缩的本质就是找数据的重复或者规律,用尽量少的字节表示。
Huffman编码
前缀编码要求一个字符的编码不能是另一个字符的前缀二
LZ系列压缩算法
LZ系列压缩算法是基于字典的压缩算法。
LZ系列的算法是一种动态创建字典的方法,压缩过程中动态创建字典并保存在从缩信息里面
列式存储
传统的行式数据库将一个个完整的数据行存储在数据页中。在磁盘中是比较高效的
列式数据库是将同一个数据列的各个值存放在一起。
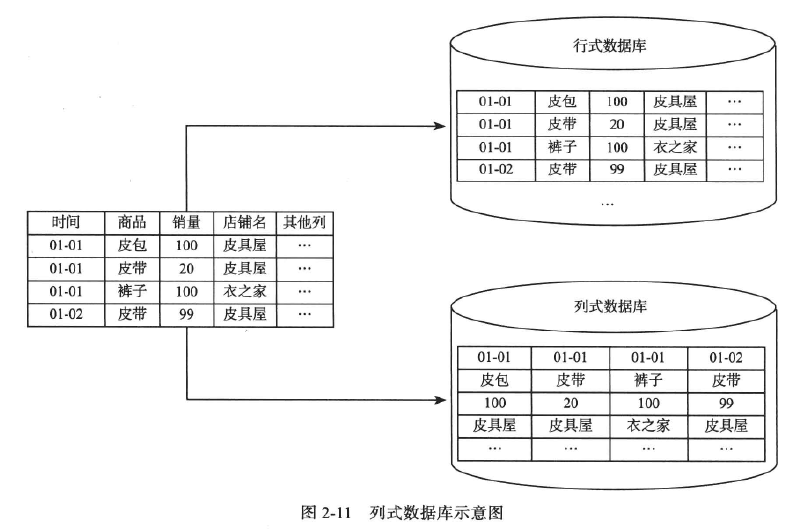
列式数据库压缩时有很大的优势。
Bigtable列式数据库对网页库压缩可以达到15倍以上的压缩率。















 8540
8540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









