








目录
监督学习的两个任务:回归和分类。线性回归,损失函数和梯度下降。
过在数字广告上花更多钱来赚多少钱?这个贷款申请人是否会偿还贷款?明天股市会发生什么?
在监督学习问题中,我们从包含具有相关正确标签的训练样本的数据集开始。例如,当学习对手写数字进行分类时,监督学习算法需要数千张手写数字图片以及包含每个图像所代表的正确数字的标签。然后,该算法将学习图像与其相关数字之间的关系,并应用该学习的关系来对机器以前未见过的全新图像(无标签)进行分类。这就是您可以通过手机拍照来存入支票的方式!
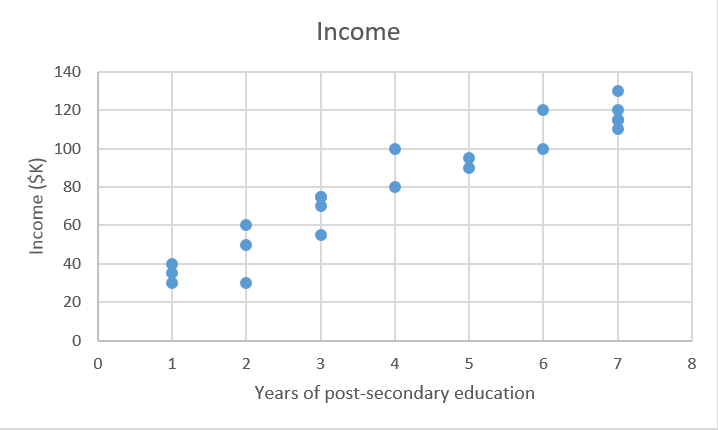
为了说明监督学习的工作原理,让我们根据某人完成的高等教育年数来检验预测年收入的问题。更正式地表达,我们想建立一个模型,该模型近似于高等教育年数X与相应的年收入Y之间的关系f。
![]()
X(输入) = 高等教育年数
Y(输出) = 年收入
f = 描述X和Y之间关系的函数
ε(epsilon) = 随机误差项(正或负),均值为零关于epsilon:
(1)ε 表示模型中的不可约误差,这是由于您试图解释的现象中的固有噪声而导致的算法性能的理论极限。例如,想象一下建立一个模型来预测硬币翻转的结果。
(2)顺便提一下,数学家保罗·埃尔德斯将子称为“epsilons”,因为在微积分中(但不是在统计中!) ε 表示任意小的正数。适合,不是吗?
预测收入的一种方法是创建一个基于规则的严格模型,用于衡量收入和教育的相关性。例如:“我估计,每增加一年的高等教育,年收入就会增加5,000美元。”
收入=($ 5,000 * years_of_education)+ baseline_income
这种方法是设计解决方案的一个例子(与学习解决方案相比,如下面描述的线性回归方法)。
您可以通过包含有关学位类型,工作年限,学校等级的一些规则来提出更复杂的模型。例如:“如果他们完成了学士学位或更高学历,则给收入估计数增加1.5倍。”
但是这种明确的基于规则的编程对复杂数据不起作用。想象一下,尝试设计一个由if-then语句组成的图像分类算法,该语句描述了应该标记为“cat”或“not cat”的像素亮度组合。
有监督的机器学习通过让计算机为您完成工作来解决这个问题。通过识别数据中的模式,机器能够形成启发式。这与人类学习的主要区别在于机器学习在计算机硬件上运行,并且通过计算机科学和统计学的镜头可以最好地理解,而人类模式匹配在生物大脑中发生(同时实现相同的目标)。
在有监督的学习中,机器试图通过学习算法运行标记的训练数据,从头开始学习收入和教育之间的关系。只要我们有多年的教育X作为投入,这种学习函数可用于估计收入Y未知的人的收入。换句话说,我们可以将我们的模型应用于未标记的测试数据以估计Y.
监督学习的目标是在给出X已知且Y未知的新例子时尽可能准确地预测Y. 在下文中,我们将探讨几种最常见的方法。
监督学习的两个任务:回归和分类
回归:预测连续数值。那房子卖多少钱?
分类:分配标签。这是猫还是狗的照片?
本节的其余部分将重点关注回归。在第2.2部分中,我们将深入研究分类方法。
回归:预测连续值
回归预测到连续 目标变量Y。它允许您根据输入数据X估算一个值,例如房价或人的寿命。
这里,目标变量意味着我们关心预测的未知变量,而连续意味着Y可以承担的值中没有间隙(不连续)。一个人的体重和身高是连续的值。另一方面,离散变量只能采用有限数量的值 - 例如,某人拥有的孩子数量是离散变量。
预测收入是一个典型的回归问题。您的输入数据X包括有关数据集中可用于预测收入的个人的所有相关信息,例如教育年限,工作年限,职位或邮政编码。这些属性称为特征,可以是数字(例如多年的工作经验)或分类(例如职称或研究领域)。
你会想与这些特征与目标输出Y.尽可能多的训练观察成为可能,让你的模型可以学习的关系˚F X和Y之间
数据被分成训练数据集和测试数据集。训练集有标签,因此您的模型可以从这些标记的示例中学习。测试组并没有有标签,例如,你还不知道你想预测值。重要的是,您的模型可以推广到之前没有遇到的情况,以便它可以在测试数据上表现良好。
回归
Y = f(X)+ε,其中X =(x1,x2 ...... xn)
训练:机器从标记的训练数据中学习f
测试:机器根据未标记的测试数据预测Y.
注意,X可以是具有任意数量维度的张量。1D张量是矢量(1行,多列),2D张量是矩阵(许多行,多列),然后您可以使用具有3个,4个,5个或更多维度的张量(例如,具有行的3D张量) ,列和深度)。有关这些术语的评论,请参阅此线性代数评论的前几页。
在我们简单的2D示例中,这可以采用.csv文件的形式,其中每行包含一个人的教育水平和收入。添加更多具有更多功能的列,您将拥有更复杂但可能更准确的模型。

那么我们如何解决这些问题呢?
我们如何构建能够在现实世界中进行准确,有用的预测的模型?我们通过使用监督学习算法来实现这一目标。
现在让我们来看看有趣的部分:了解算法。我们将探索一些方法来回归和分类,并说明关键的机器学习概念。
线性回归(普通最小二乘)
“划清界线。是的,这算作机器学习。“
首先,我们将专注于使用线性回归解决收入预测问题,因为线性模型不能很好地与图像识别任务一起工作(这是深度学习的领域,我们将在后面探讨)。
我们有我们的数据集X ,以及相应的目标值Y.的目标普通最小二乘法(OLS)回归是学习,我们可以用它来预测新的线性模型Ÿ给予了前所未见的X用尽可能少的错误越好。我们想根据他们接受多少年的教育来猜测他们的收入是多少。
X_train = [4,5,0,2,...,6]#中学后教育年数
Y_train = [80,91.5,42,55,...,100]#相应的年收入,数千美元
线性回归是一种参数方法,这意味着它假设关于X和Y的函数的形式(我们将在后面介绍非参数方法的例子)。我们的模型将是一个预测ŷ给定特定x的函数:
在这种情况下,我们明确假设X和Y之间存在线性关系 - 也就是说,对于X中的每一个单位增加,我们看到Y中的常数增加(或减少)。
β0是y轴截距,β1是我们线的斜率,即一年的教育收入增加(或减少)多少。
我们的目标是学习模型参数(在这种情况下,β0和β1),以最大限度地减少模型预测中的误差。
要找到最佳参数:
定义成本函数或损失函数,用于衡量模型预测的不准确程度。
找到使损失最小化的参数,即使我们的模型尽可能准确。
在图形上,在两个维度中,这导致最佳拟合线。在三个维度上,我们将绘制一个平面,依此类推更高维的超平面。
关于维度的注释:为简单起见,我们的示例是二维的,但您通常在模型中有更多的特征(x)和系数(beta),例如,在添加更多相关变量以提高模型预测的准确性时。相同的原则推广到更高的维度,尽管在三维之外可视化更加困难。

在数学上,我们看一下每个实际数据点(y)和模型预测(ŷ)之间的差异。将这些差异平方以避免负数并惩罚较大的差异,然后将它们相加并取平均值。这是衡量我们的数据与线路匹配程度的指标。
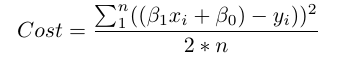
n =观察数量。使用2 * n而不是n可以使得数学运算更加干净,当采用导数来最小化损失时,尽管一些统计数据的人说这是亵渎神明。当你开始对这种东西发表意见时,你会知道你一直在兔子洞里。
对于像这样的简单问题,我们可以使用微积分来计算闭合形式解,以找到最小化我们的损失函数的最佳β参数。但随着成本函数的复杂性增加,找到带有微积分的封闭形式解决方案已不再可行。这是称为梯度下降的迭代方法的动机,它允许我们最小化复杂的损失函数。
梯度下降:学习参数
“戴上眼罩,走下坡路。当你无处可去时,你已经找到了最低点。“
梯度下降会一次又一次地出现,特别是在神经网络中。像scikit-learn和TensorFlow这样的机器学习库在任何地方都使用它,所以值得了解细节。
梯度下降的目标是通过迭代地获得更好和更好的近似值来找到模型损失函数的最小值。
想象一下,你自己穿过一个蒙着眼睛的山谷。你的目标是找到山谷的底部。你会怎么做?
一个合理的方法是触摸你周围的地面,并在地面向下倾斜的任何方向上移动最陡峭。迈出一步,不断重复同样的过程,直到地面平坦。然后你知道你到达了山谷的底部; 如果你从任何方向移动,你将会在同一高度或更远的山坡上移动。
回到数学,地面成为我们的损失函数,山谷底部的高度是该函数的最小值。
让我们来看看我们在回归中看到的损失函数:
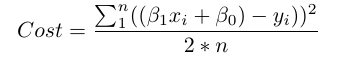
我们看到这实际上是两个变量的函数:β0和β1。确定所有其余变量,因为在训练期间给出X,Y和n。我们想尽量减少这个功能。
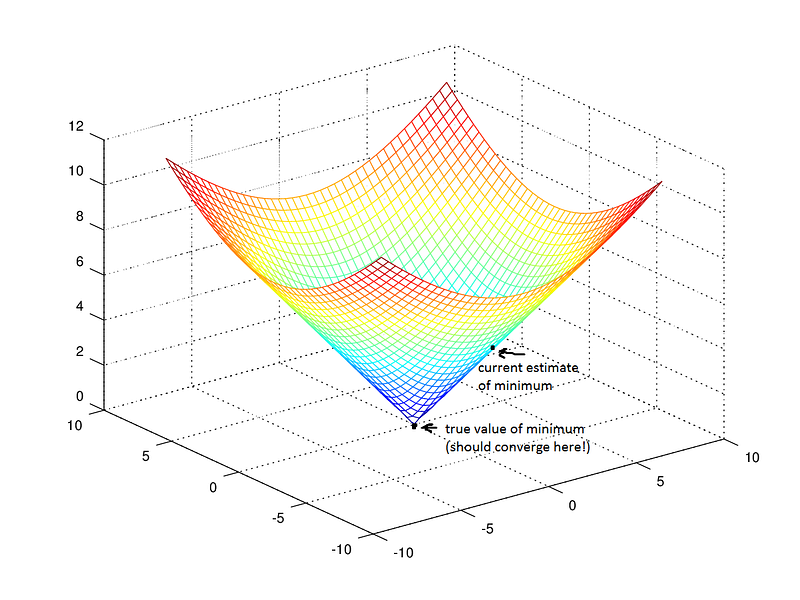
函数是f(β0,β1)= z。要开始梯度下降,您需要猜测最小化函数的参数β0和β1。
接下来,您可以找到关于每个beta参数的损失函数的偏导 数:[ dz/dβ0,dz/dβ1 ]。甲偏导数表示总损耗多少增加或减少如果增加β0或β1由一个非常小的量。
换句话说,假设零高等教育(β0)会增加您模型的损失(即不准确),那么增加您对年收入的估计会增加多少?你想向相反的方向走,这样你最终走下坡路,尽量减少损失。
同样,如果你增加每个增量教育年度对收入的影响程度(β1)的估计值,这会增加多少损失(z)?如果偏导数dz /β1是负数,则增加 β1是好的,因为它将减少总损失。如果是正数,则需要降低 β1。如果它为零,则不要更改β1,因为这意味着您已达到最佳状态。
继续这样做直到你到达底部,即算法收敛并且损失已经最小化。除了本系列的范围之外,还有许多技巧和特殊情况,但通常,这就是为参数模型找到最佳参数的方法。
过度拟合
过度拟合: Sherlock,你对刚刚发生的事情的解释对于这种情况来说太具体了。”
正规化: 不要过于复杂化,Sherlock。我会为每一个额外的单词打你。
超参数(λ): 这是我为每一个额外的单词打你的力量。
机器学习中的一个常见问题是过度拟合:学习一种功能,可以完美地解释模型所学习的训练数据,但不能很好地概括为看不见的测试数据。当模型从训练数据中过度扩展到开始拾取不能代表现实世界中的模式的特性时,就会发生过度拟合。当您使模型变得越来越复杂时,这尤其成问题。欠拟合是一个相关问题,您的模型不够复杂,无法捕捉数据中的基本趋势。
偏差 - 方差权衡:
偏差是通过简化模型逼近现实世界现象而引入的误差量。
方差是指模型的测试误差根据训练数据的变化而变化的程度。它反映了模型对其所训练的数据集的特性的敏感性。
随着模型的复杂性增加,它变得更加摇摆(灵活),其偏差减小(它很好地解释了训练数据),但方差增加(它也没有概括)。最终,为了拥有一个好的模型,你需要一个低偏差和低差异的模型。

资料来源:Coursera的ML课程,由Andrew Ng教授
请记住,我们唯一关心的是模型如何对测试数据执行。您希望预测 哪些电子邮件在标记之前将被标记为垃圾邮件,而不仅仅是构建一个在重新分类用于构建自身的电子邮件时100%准确的模型。后见之明是20/20 - 真正的问题是所吸取的经验教训是否有助于将来。
右侧的模型对训练数据没有损失,因为它完全适合每个数据点。但是这一课并没有概括。在解释一个尚未上线的新数据点时,这将是一项糟糕的工作。
两种打击过度拟合的方法:
1.使用更多培训数据。您拥有的越多,通过从任何单个训练示例中学习太多来过度拟合数据就越困难。
2.使用正则化。在损失函数中添加一个惩罚,用于构建一个模型,该模型为任何一个特征分配过多的解释力,或者允许考虑太多的特征。
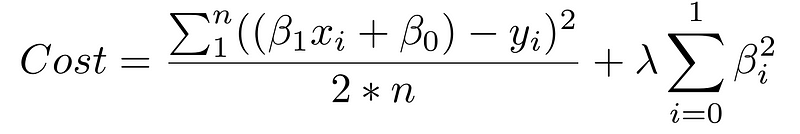
上面总和的第一部分是我们的正常成本函数。第二部分是一个正则化项,它为大的β系数增加了一个惩罚,它给任何特定的特征提供了太多的解释力。有了这两个要素,成本函数现在可以在两个优先级之间取得平衡:解释培训数据并防止该解释变得过于具体。
成本函数中正则化项的lambda系数是一个超参数:模型的一般设置,可以增加或减少(即调整) 以提高性能。较高的λ值将更严厉地惩罚可能导致潜在过度拟合的大β系数。要确定lambda的最佳值,您需要使用一种称为交叉验证的方法,该方法包括在训练期间保留一部分训练数据,然后查看模型解释保持部分的程度。我们将更深入地讨论这个问题
呜!我们做到了。
这是我们在本节中介绍的内容:
- 受监督的机器学习如何使计算机能够从标记的训练数据中学习而无需明确编程
- 监督学习的任务:回归和分类
- 线性回归,一种面包和黄油参数算法
- 学习参数与梯度下降
- 过度拟合和正规化
在下一节 - 第2.2部分:监督学习II - 我们将讨论两种基本的分类方法:逻辑回归和支持向量机。
练习材料和进一步阅读
2.1a - 线性回归
有关线性回归的更全面处理,请阅读“ 统计学习简介”的第1-3章。这本书是免费在线提供的,是一个很好的资源,用于理解机器学习概念和附带的练习。
更多练习:
- 玩Boston Housing数据集。您既可以使用具有良好GUI的软件(如Minitab和Excel),也可以使用Python或R进行艰苦(但更有价值)的方式。
- 尝试一下Kaggle挑战,例如住房价格预测,看看其他人在自己尝试之后如何解决问题。
2.1b - 实施梯度下降
要在Python中实际实现梯度下降,请查看本教程。而这里是一个更严格的数学相同的概念描述。
在实践中,您很少需要从头开始实现渐变下降,但了解它在幕后的工作方式将使您能够更有效地使用它并理解为什么它们会在事情发生时中断。
原文:https://medium.com/machine-learning-for-humans/supervised-learning-740383a2feab















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









