









我终于看懂了这篇paper!
RCNN解决了用卷积网络做目标检测的问题,通过selective search在特征图上得到region proposal,进而使用svm进行二分类,得到了目标检测需要的分类信息和位置信息。
Fast rcnn解决了RCNN得到region proposal费时费空间的问题。通过引入Roi pooling使任意大小的输入可以输出为指定大小的roi向量,这样,一张图片的所有Roi计算都可以共享(只需要跑一次backbone)。在得到roi后分别送入分类和回归任务中,实现了k+1分类,和(k+1)*4的回归任务。
Faster rcnn解决了region proposal非常耗时的问题,目前都是由selective search得到region proposal。卷积网络已经可以由GPU实现,然而SS还停留在古老的cpu方法。所以Faster rcnn提出了著名的RPN(region proposal network)来实现卷积共享。
Faster Rcnn
Faster Rcnn由两部分组成,一个是全卷积网络用于获得候选区域,一个是fast rcnn检测器使用候选区域进行分类和回归。这个fast rcnn检测器主要是指,从RoI pooling layer层开始,做分类和回归的那部分。

RPN
rpn的核心是anchors,其实就是一个滑动窗口。rpn的输入是backbone输出的feature map。当backbone使用vgg的时候,图片输入800*600,下采样16倍,也就是特征图输出(800/16)*(600/16)=50*38.
anchors是个滑动窗口,论文中使用ZF网络,所以特征图是256维的。anchors在特征图上滑动,也就是产生50*38个anchors,每个anchor能产生k个anchors boxes,也就是对应原图k个region proposal。

文中设置anchor有1:1,1:2,2:1的比例,还有三个大小,一共产生9个anchor boxes,也就是共50*38*9个boxes。这就实现了多尺度和多长宽比的输入。
rpn输入首先过一个3x3卷积,之后分为两路。一路用来分类,2k个分数,表示一个anchor产生k个boxes(k=9),有positive和negative两个情况,由1x1卷积输出,设置num_output=18,这个矩阵的大小为WxHx(9*2);一路用来回归,4k个分数,表示(x, y, w, h)的坐标,由另一个1x1卷积输出,设置num_output=18,这个矩阵的大小为WxHx(9*4)。
分类:1x1卷积后面的reshape是为了便于softmax分类。其在caffe blob中的存储形式为[1, 2x9, H, W]。而在softmax分类时需要进行positive/negative二分类,所以reshape layer会将其变为[1, 2, 9xH, W]大小,即单独“腾空”出来一个维度以便softmax分类,之后再reshape回复原状。这里实际上做的是二分类,用sigmoid也可以。这就可以得到某个anchor boxes有没有待检测物体,也就是positive anchor。
回归:1x1卷积输出为WxHx36,相当于每个点都有9个anchors,每个anchors有4个用于归回的
![]()
所以rpn的输出是:1. 大小为50*38*2k的positive/negative softmax分类特征矩阵,2. 大小为 50*38*4k 的regression坐标回归特征矩阵。
rpn解决的问题是比selective search快,快在ss得到候选框需要对一大堆的框遍历,这个遍历只能在cpu上做,rpn生成框的过程直接通过1*1卷积实现,可以用gpu,四舍五入不要时间。而且速度快了就可以搞更多的框,检测出的目标就更多了。
Proposal Layer
proposal layer用于处理rpn输出的回归量和positive anchors。输入有三个,positive vs negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的![]() 变换量rpn_bbox_pred,以及im_info;另外还有参数feat_stride=16(下采样倍数)。
变换量rpn_bbox_pred,以及im_info;另外还有参数feat_stride=16(下采样倍数)。
im_info=[M, N, scale_factor]储存了图像所有的缩放信息,M、N是图片传入faster rcnn前的缩放大小,经过backbone的4个pooing后WxH=(M/16)x(N/16),其中scale_stride=16则保存了该信息,用于计算anchor偏移量。
Proposal Layer forward的处理方法为:
- 生成anchors,利用
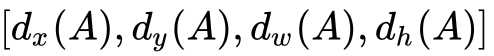 对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致) - 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors
- 限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界(见文章底部QA部分图21)
- 剔除尺寸非常小的positive anchors
- 对剩余的positive anchors进行NMS(nonmaximum suppression)
- Proposal Layer有3个输入:positive和negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的(e.g. 300)结果作为proposal输出
在anchor产生的3(比例1:2、2:1、1:1)*3(128*128、256*256、512*512)=9个anchor boxes中,每个都根据IoU划分了正、负、不参加训练的标签。这里有9个回归器,比如anchor A(256*256, 1:2)为正,那么就有gt A,那么anchor A就可以和gt A进行回归。9个回归器并不是都起作用的。回归的过程可以学到![]() ,也就是说这里学到的是某个anchor和gt的变化关系,而不是直接学到gt,
,也就是说这里学到的是某个anchor和gt的变化关系,而不是直接学到gt,
ROI pooling
roi pooling的输入有两个,1.原始的feature maps, 2. rpn的输出proposal boxes。具体看fast rcnn。
输出是7x7的特征向量。这个向量被送入后续全连接层进行分类和回归。这里必须用roi pooling的原因是,anchor得到的region proposal的尺寸可能是不一样的,不一样的尺寸没法送入全连接层。
faster rcnn的训练过程:
faster rcnn是two-stage的算法,体现在训练过程需要两步,也就是rpn和fast rcnn需要交替训练:
- 在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
- 利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
- 第二训练RPN网络,对应stage2_rpn_train.pt
- 再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
相比于fast rcnn是一阶段的,因为获得region proposal的过程不需要训练。
训练过程如果
Loss
整个网络使用的loss也分为分类损失和回归损失:

上述公式中i表示anchors index,pi表示positive softmax probability,p*i代表对应的GT predict概率(即当第i个anchor与GT间IoU>0.7,认为是该anchor是positive,p*i=1;反之IoU<0.3时,认为是该anchor是negative,p*i=0;至于那些0.3<IoU<0.7的anchor则不参与训练)。

t代表predict bounding box,t*代表对应positive anchor对应的GT box。可以看到,整个Loss分为2部分:
- cls loss,即rpn_cls_loss层计算的softmax loss,用于分类anchors为positive与negative的网络训练
- reg loss,即rpn_loss_bbox层计算的soomth L1 loss,用于bounding box regression网络训练。注意在该loss中乘了p*i,相当于只关心positive anchors的回归(其实在回归中也完全没必要去关心negative)。
λ用于平衡两者的系数。
所以整体看看faster rcnn的前向传播:
1. 使用back bone对image提取feature map, 比如使用vgg下采样16倍,输入800*600,输出50*38*256的特征图,256为通道数。
2. 使用RPN得到region proposal。首先用在50*30上生成了50*30个anchor,对应50*30*9个anchor boxes。每个anchor box通过2个1x1卷积得到分类和回归特征,对于每个anchor,分类是9*2,回归是9*4.
3. 根据ground truth的iou确定每个anchor boxes是positive还是nagetive,或者两个都不是。
(1)和一个ground truth的IoU值最大的那些anchor;(2)和任意一个ground truth的IoU大于或等于0.7的anchor。注意到单个ground truth可能分配正样本标签给多个anchor。第(2)个条件足以确定正样本,仍然使用第(1)个条件的原因是存在在第(2)个条件下没有正样本的情况。不是正样本的anchor中,那些和所有ground truth的IoU值小于0.3的被分配为负样本,其余那些既不是正样本也不是负样本的anchor,不作为训练样本,被忽略掉的。这样对于一个滑窗,原图产生的9个anchor,anchor可能被分配到正样本、负样本、被忽略样本的标签。然后对每个正样本anchor对应的ground truth,打上回归的标签,交给该anchor对应的回归器预测。
4. 从一张图片中随机采样256个anchor boxes,正负样本的比例是1:1,如果张图片中正样本anchor boxes的数量少于128个,就减少负样本anchor boxes的数量和正样本anchor boxes数量相同。需要注意的是,这256个anchor boxes中来自不同的滑窗。
5. 所以每个anchor生成了9*256的向量,也就是每个256维的向量,经过2个1x1卷积,得到了一个4维的box回归和2维的box分类,那么一个anchor就是9*(4+2)的输出。这个输出是这么来的:9个256维的向量,送入了分类和9个回归,对应9个不同的尺寸。然后对正样本的anchor boxes进行回归。
6. 然后就是使用rpn得到的region proposal在feature map上得到待检测的小特征图,这些特征图送入了roi pooling中。文章说到的roi pooling和region proposal共享了卷积,就是使用最后一层卷积同时得到了region proposal和feature map。
参考:https://zhuanlan.zhihu.com/p/31426458
https://www.zhihu.com/question/42205480














 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









