







前言
近日闲来无事,一直想着学习LLM、VLM和VLA的内容,把理论和实践走一遍,在最近把LLM和VLM/VLA的综述看完,索性操刀实践一波LLM和VLM的相关项目。这就是这篇LLM的实操记录的缘由。
项目介绍
Minimind 是一个目标在于以最小成本训练LLM的项目,其中包含两种尺寸的模型:0.025b模型和0.1b模型,包括模型的全生态训练:预训练、微调、人类反馈增强、Lora和 R1-zero,以及api部署。以下将对本项目进行实操和测试。
本人在autodl租用了一款32GB服务器,完成了对0.025b模型的训练(预训练、微调、人类反馈增强和 R1-zero)和api部署。模型的结构如下,隐藏层维度为512,transformer layer为8层。
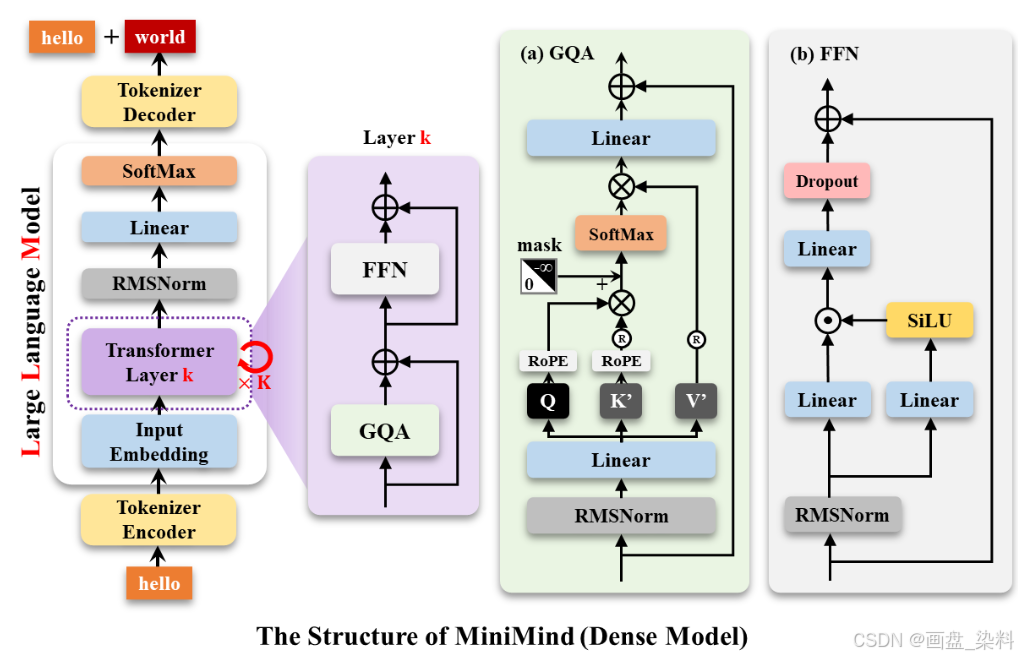
Tokenizer 采用 Minimind作者预训练的minimind-tokenizer,词表大小仅为6,400,以方便在性能预算不足的设备进行精度尚可的快速推理。以下是目前市面上较好的Tokenizer:
| Tokenizer模型 | 大小 | 来源 |
|---|---|---|
| yi tokenizer | 64,000 | 01万物 |
| qwen2 tokenizer | 151,643 | 阿里云 |
| glm tokenizer | 151,329 | 智谱AI |
| mistral tokenizer | 32,000 | Mistral AI |
| llama3 tokenizer | 128,000 | Meta |
| minimind tokenizer | 6,400 | 作者训练 |
Benchmark
以下是对minidmind作者训练的0.1b微调模型的推理测试。


可见效果非常好,足够一般的使用场景。
R1-zero模型
训练全过程
没有使用预训练权重,初始化一个torch模型,0.025b (25MB) ,8层transformer layers和512的隐藏层宽度。依次进行下述流程的训练:
预训练: 在一个1.6G的中文数据集(提取自匠数大模型数据集)上进行训练,4个epoch。该预训练流程用于灌输维基百科类型的事实知识给模型。
数据内容预览:
{"text": "如何才能摆脱拖延症? 治愈拖延症并不容易,但以下建议可能有所帮助..."}
微调: 依次在两个数据集上训练,一个是文本长度短于512的文本数据集(7.5G,清洗自匠数大模型SFT数据集),一个是文本长度短于2048的文本数据集(9G,提取并清洗自Qwen2/2.5的对话流)。LLM将学习怎么对话。
数据内容预览:
{
"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"}
]
}
模型训练效果展示:

人类反馈强化学习RLHF: 在一个0.86G的英文数据集(清洗自Magpie-DPO数据集 )进行训练。用于学习人类偏好,使得语言更加贴近人类对话习惯。
数据内容格式:
{
"chosen": [
{"content": "Q", "role": "user"},
{"content": "good answer", "role": "assistant"}
],
"rejected": [
{"content": "Q", "role": "user"},
{"content": "bad answer", "role": "assistant"}
]
}
模型训练效果展示:

R1-zero: deepseek最近很火,一个重要原因是模型经过推理数据集的训练后出现了自我纠正的能力,体现了令人震惊的思考能力。推理数据集结合了多个R1的蒸馏数据集R1-Llama-70B、R1-Distill-SFT、 Alpaca-Distill-R1、 deepseek_r1_zh,提取了中文的内容。
Tips: 但是由于目前本实验的模型仅为0.025b,模型拟合能力较差,同时训练轮次较低,无法实现很好的推理能力。本人师兄在0.5b模型上复现了r1-zero能力,但是对于更低大小的模型本没有尝试。Minimind作者在0.1b模型上实现了一定程度的r1-zero。
数据内容格式:
{
"conversations": [
{
"role": "user",
"content": "你好,我是小芳,很高兴认识你。"
},
{
"role": "assistant",
"content": "<think>\n你好!我是由中国的个人开发者独立开发的智能助手MiniMind-R1-Lite-Preview,很高兴为您提供服务!\n</think>\n<answer>\n你好!我是由中国的个人开发者独立开发的智能助手MiniMind-R1-Lite-Preview,很高兴为您提供服务!\n</answer>"
}
]
}
模型训练效果展示:

API部署
利用Openai接口创建本地推理模型的服务器。推理模型为微调训练的模型。
创建client端进行对话:

心得与总结
自己训练LLM还是很好玩的,学习了从0到R1-zero的模型训练,深刻体会到了LLM的魅力,大力出奇迹,scaling law无法绕过,LLM的智能来源于模型的大小。我在同样的训练流程中训练了一个0.1b的微调模型,明显能够体会到,同样的训练轮次(4epoch),模型的回答质量明显上升,出现的幻觉更少。而对于0.025b模型,把训练轮次从4提高到8,模型回答质量改善轻微,有这时间不如加大模型参数量。大就是智能!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









