







1.32bit系统,4G寻址空间,按线程栈10M来算(ulimit -a 查看stack size 默认为8192KB,即8M),系统最多支持400个线程。按原先的做法,将accept的套接字的缓冲区交由epoll监听,epoll监听到有数据之后,开新线程来处理。
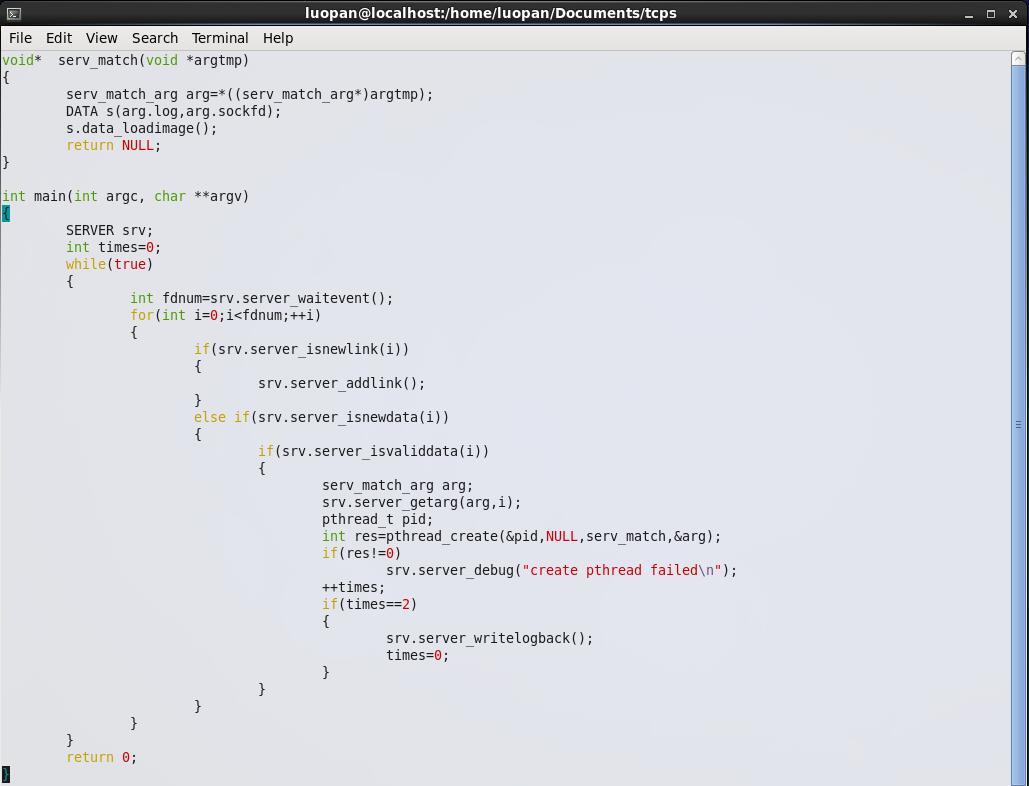
这样做有个两个大问题:
【1】即使监听到了有新数据,由于新线程开不出来,还是没法处理数据,且因为EPOLLONESHOT的原因,再也没法收到读的信号,数据会一直卡在缓冲区中。
【2】图像检索服务,全放在一个线程中操作 。检索服务分为3部分【从对端读取图片】+【与数据库中的特征向量比对】+【将匹配度高的图像写入对端socket】,整个过程包含读socket+遍历计算+写socket,算是一个长连接。那么在上面的模型中,本质上是先接收下了连接,但连接上发来的检索请求会因线程数不够而迟迟得不到解决,或索性因为EPOLLONESHOT的存在而一直得不到解决。上面的模型,本质上还是在用线程数撑并发连接数!!
那怎么做???哈哈哈,我想到了操作系统的任务调度机制!!!!‘
是的,可以使用队列,先将请求放在队列中,只管从队列中取任务,然后再往队列中放任务就可以了。
上面的检索服务实际上可以分成3部分:【读】+【计算】+【写】,所以可以分成3个任务队列。这样【读】需要占用的自定义接收缓冲区,【计算】不需要,这份(自定义接收缓冲区大小)4B的内存可以省下来了;【计算】需要的存储合适图片名的自动变量的这份内存,也可以省下来了。而且最重要的是:上面任务丢失的问题解决了。不会再因为线程数不够导致任务没接到,而永远将新数据卡在缓冲区中。再也不是用线程数撑并发数了。
下午编写的时候,发现其实这样的方法仍然不是最好的,因为大文件的【读】和【写】仍然可以拆分。最好的方法应该是
以读为例,先读文件头,将文件长度存在全局map中,以供查询文件是否读完
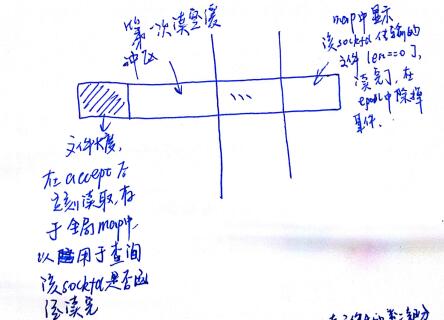
这样的话,其他文件不会因为线程已经耗完,导致只能在任务队列中呆着

其实第二种方法虽然解决了任务丢失的问题,但没解决任务均衡的问题。用操作系统的话来讲,这个任务调度机制是先进先服务。而第三种方法是时间片轮转的迁移使用。操作系统没白学















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









