







 本文介绍了如何利用Python实现KMeans三维聚类方法进行冲突分析。通过聚类,可以将数据分为不同的组别,从而进行深入的冲突识别和理解。文章提供了完整的代码示例,并展示了聚类结果。
本文介绍了如何利用Python实现KMeans三维聚类方法进行冲突分析。通过聚类,可以将数据分为不同的组别,从而进行深入的冲突识别和理解。文章提供了完整的代码示例,并展示了聚类结果。
原始数据如图
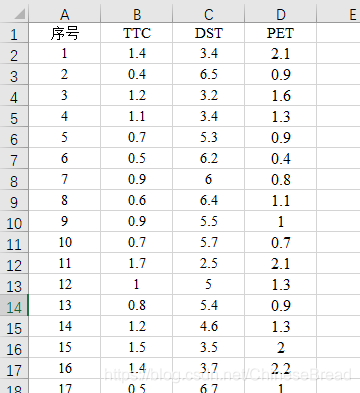
完整代码如下:
#coding:utf-8
import random
from sklearn import datasets
import pandas as pd
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 正规化数据集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 计算一个样本与数据集中所有样本的欧氏距离的平方
def euclidean_distance(one_sample, X):
one_sample = one_sample.reshape(1, -1)
X = X.reshape(X.shape[0], -1)
distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1)
return distances
class Kmeans():
"""Kmeans聚类算法.
Parameters:
-----------
k: int
聚类的数目.
max_iterations: int
最大迭代次数.
varepsilon: float
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









