







数据挖掘Part 3 聚类分析
3.1聚类分析基本概念和方法
聚类分析(无监督学习)简称聚类,是一个把数据对象(或观测)划分成子集的过程。每个子集是一个簇,使得簇中的对象彼此相似,但与其他簇中的对象不相似。由聚类分析产生的簇的集合称作一个聚类。
相同的数据集不同的聚类方法也可能产生不同的聚类。
用处:1.发现数据内事先未知的群组;
2.离群点检测
基本聚类方法:
1.划分方法(把对象组织成多个互斥的组或簇,优化一个客观划分准则)——k-means
2.层次方法——Chameleon
3.基于密度的方法——DBSCAN
4.基于网格的方法——STING
| 方法 | 一般特点 |
|---|---|
| 划分方法 | 发现球形互斥的簇;对中小规模数据集有效;基于距离;可以用均值或中心点等代表簇中心 |
| 层次方法 | 聚类是一个层次分解(即多层);不能纠正错误的合并或划分;可以集成其他技术,如微聚类或考虑对象“连接” |
| 基于密度的方法 | 可以发现任意形状的簇;簇是对象空间中被低密度区域分隔的稠密区域;簇密度:每个点的“邻域”内必须具有最少个数的点;可能过滤离群点 |
| 基于网格的方法 | 使用一种多分辨率网格数据结构;快速处理(典型的,独立与数据对象数,但依赖于网格大小) |
3.2度量数据的相似性与相异性
相似性和相异性都称为近邻性。
用对象之间的距离确定两个对象的相似性(欧式空间、公路网、向量空间等)
在其他方法中,相似性可以用基于密度的连接性或邻近性定义,并且可能不依赖两个对象之间的绝对距离。
sim(i , j)= 1 - d( i , j)
d(i,j)一般而言是非负数值代表对象之间的差异性。
(1)相异度计算方法(一种标称属性的相似度度量)
标称属性:一般可取两个或多个状态
两对象之间的相异性可以根据不匹配率来计算
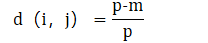
m是i与j相同状态的属性数,p是刻画对象的属性个数。
(2)Jaccard距离(二元属性相似度度量)
给定两个比较对象A,B。A,B均有n个两元属性,即每个属性取值为{0,1}。
M00:A,B属性值同时为0的属性个数;
M01:A属性值为0且B属性值为1的属性个数;
M10:A属性值为1且B属性值为0的属性个数;
M11:A,B属性值同时为1的属性个数;
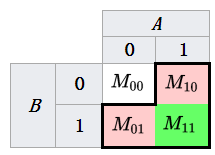
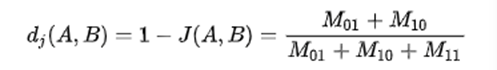
此处分母之所以不加M00的原因在于:
对于杰卡德相似系数或杰卡德距离来说,它处理的都是非对称二元变量。非对称的意思是指状态的两个输出不是同等重要的,例如,疾病检查的阳性和阴性结果。
按照惯例,我们将比较重要的输出结果,通常也是出现几率较小的结果编码为1(例如HIV阳性),而将另一种结果编码为0(例如HIV阴性)。给定两个非对称二元变量,两个都取1的情况(正匹配)认为比两个都取0的情况(负匹配)更有意义。负匹配的数量s认为是不重要的,因此在计算时忽略。
(3)数值属性的相似度度量方法
欧几里得距离、曼哈顿
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3140
3140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









