







目录
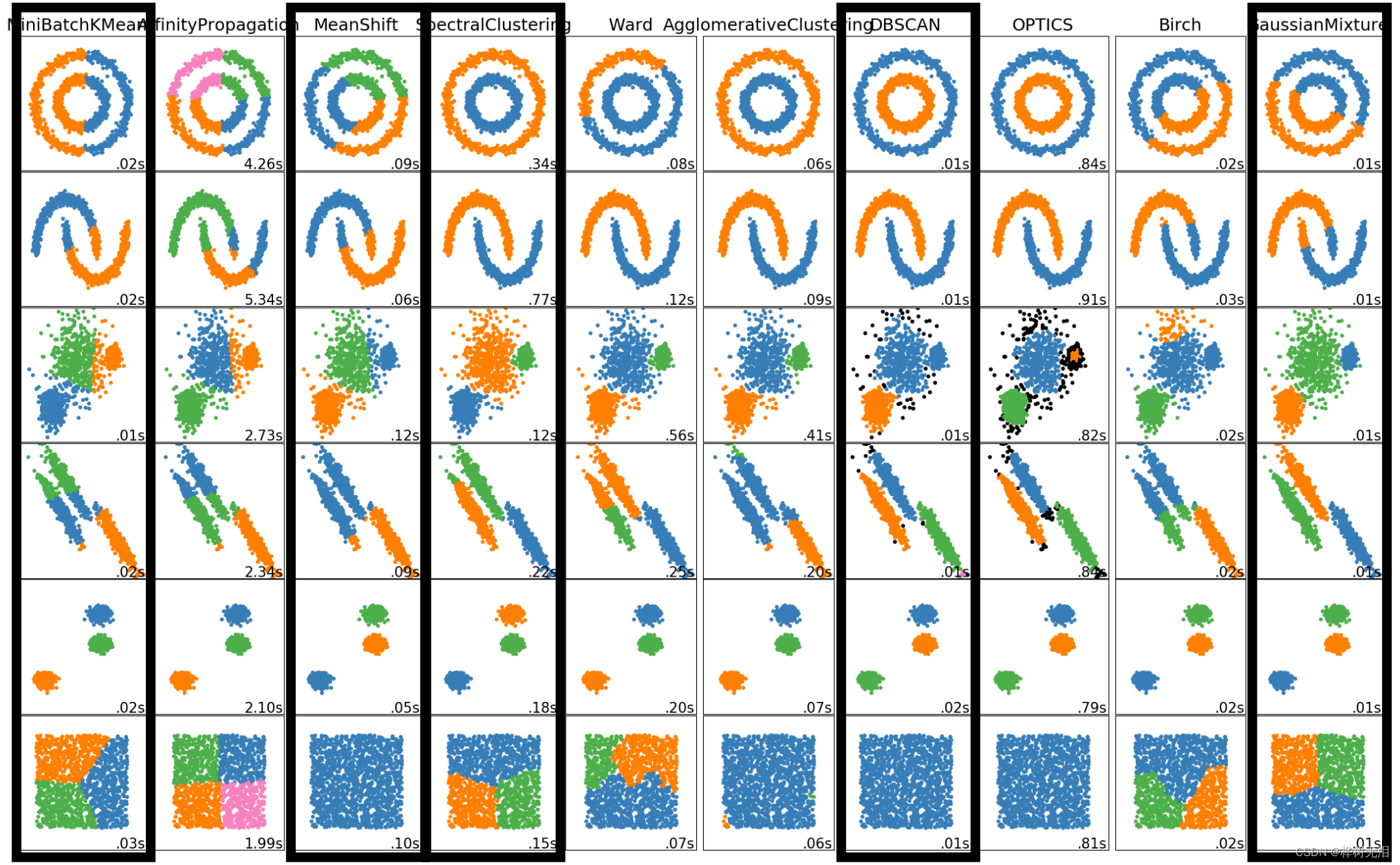
1. 聚类简介
把相似的放在一起
2. 数学基础
2.1 谱定理与瑞利熵
谱定理:一个对称矩阵拆成两个旋转矩阵和一个缩放矩阵,缩放矩阵是对角矩阵。

瑞利熵:一个向量取值范围取决于缩放矩阵

2.2 概率论基础
2.2.1 联合概率

2.2.2 边缘分布

把其中一个变量直接去掉,通过联合分布得到单独的x,y分布
2.2.3 条件概率
指定y为某一个值的x的分布

贝叶斯公式

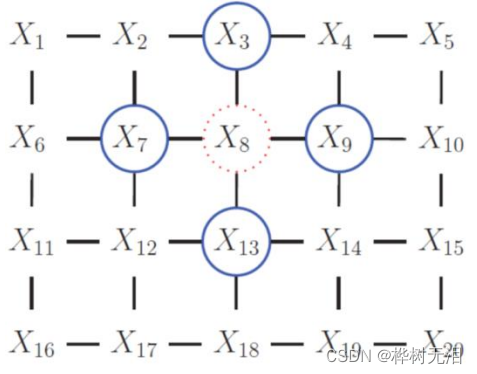
2.3 图论
2.3.1 有向图
由一系列的节点和一系列的边组成,节点代表随机变量,边代表随机变量之间的联系。z代表年龄,x代表发色。变量之间一定要有关联才能连线。有父子关系

![]()
2.3.2 无向图
无父子关系,没有方向
2.4 拉格朗日优化
最大值在相切位置

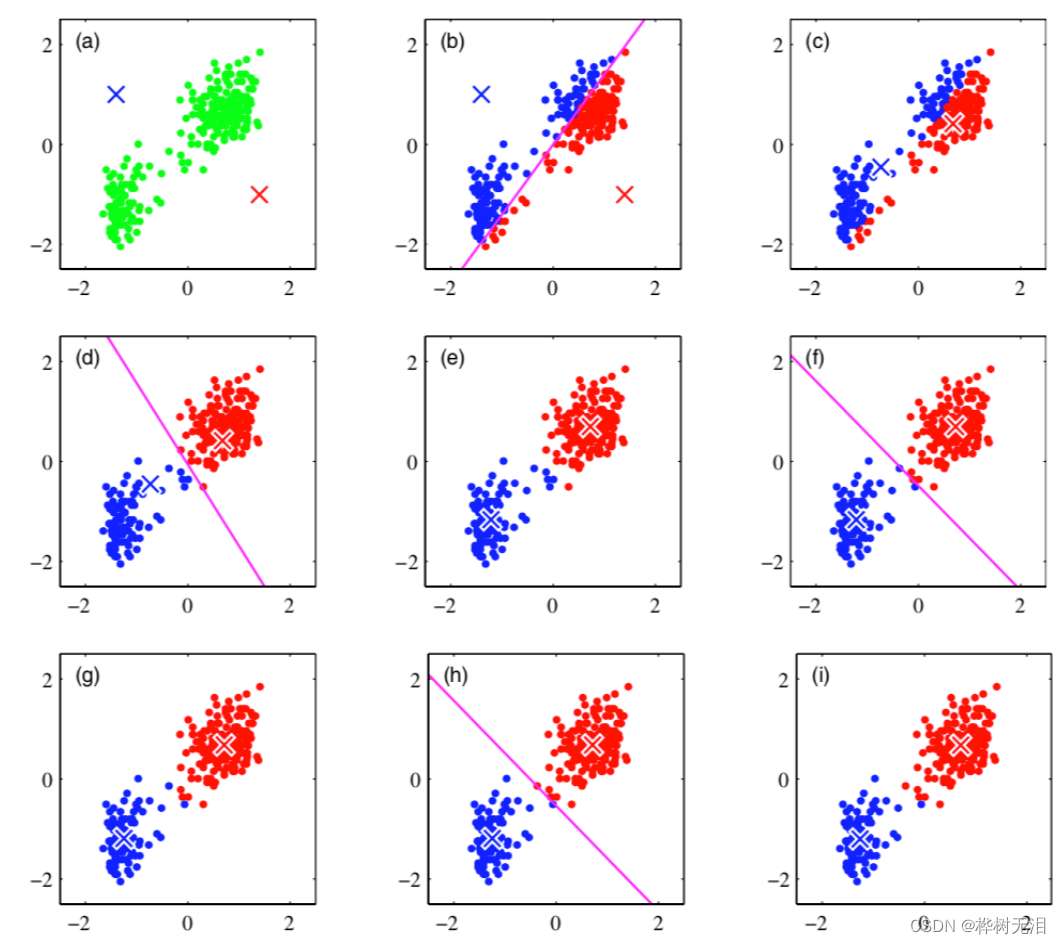
3 K-Means算法
3.1 算法步骤
1、人工给定K个类 2、每个点是哪一个类 3、更新中心点的位置 4、迭代直到算法收敛
算法收敛的条件: 1、中心点不再移动 2、所有点分配点不再变化
3.2 K-Medoids
K-means对于有噪声存在的点效果不好。K-Medoids不再选平均值,而是选择一个点使得所有点的距离和最小。

3.3 K-Mean的缺陷
- K是不知道的
- 对噪声敏感
- 没有置信度,对于处于边界的点是不合理的

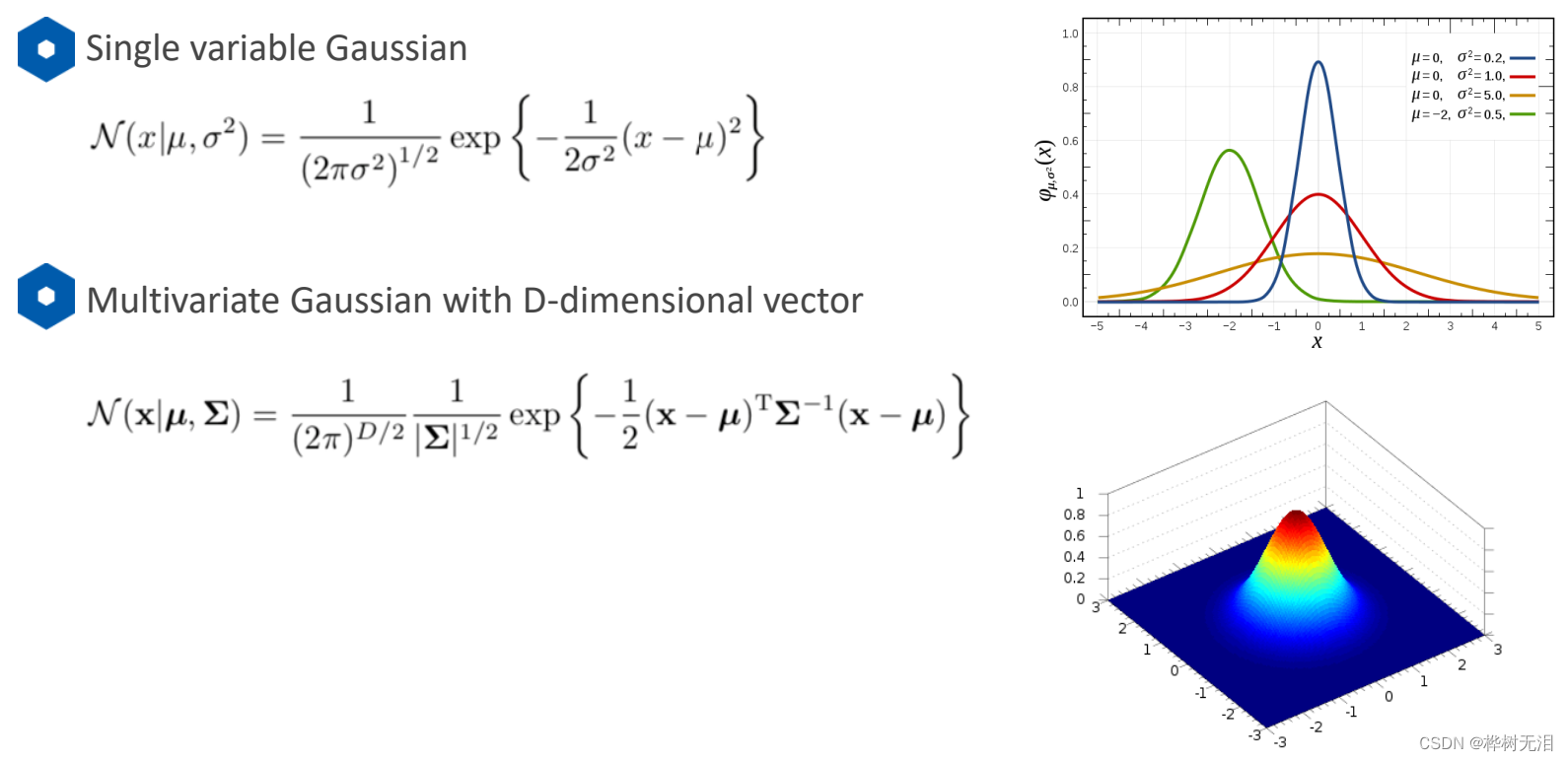
4 高斯GMM模型
4.1 概述
用高斯模型来描绘每个类的,给出每个点是该类的概率
n个高斯模型的线性组合


5 Spectral Clustering 谱聚类
5.1 概述
之前的点是在欧式空间中聚类的,所以对于不规则的分布效果不好。谱聚类是根据点与点之间的连接性。利用点与点之间的关系建立相似度矩阵,求出其特征向量,利用每个点的特征向量进行K-Means聚类。

计算点与点之间的相似度,

无向图矩阵建立方法:
1、每一个节点之间都有连线,相似度是根据距离
2、每个节点只选择与它距离相近的几个点连线 KNN RNN
得到相似矩阵处理得到对角矩阵Degree matrixD,D矩阵对角线的值是所在那一行的和,意义是第i个节点,它所连接所有节点权重的和。

5.2 步骤

- 找出相似矩阵
- 找出拉欧拉斯矩阵最小特征值作为每一行的特征向量
- 再利用特征值做K-means
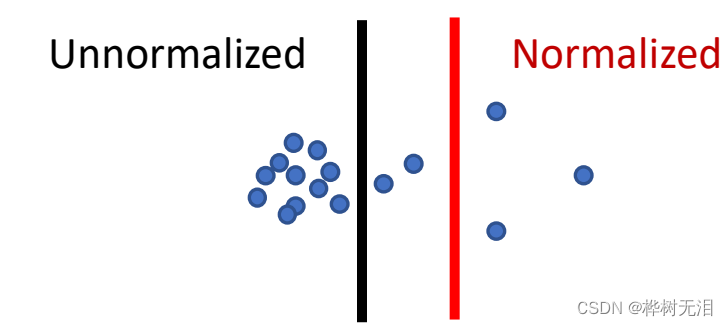
经过归一化的谱聚类两类密度相似,不经过想数量相似


5.3 总结
- 复杂度高,运算量大是n的3次方
- 不会对类的形状有任何假设,基于图论
- 可以对任何维度的数据进行分类
- 可以估计有多少类,不需要人工指定

















 4985
4985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











