










文章目录
前言
这里接上文 [Pytorch 源码阅读] —— 谈谈 dispatcher(一) 中对 Pytorch 中 dispatcher 的相关概念介绍,主要是对相关概念和类间的关系做一个概述,没有读过前面文章的同学建议先读一下前面的文章。这里就是深入各个类的源码,对这些类做一个详细的解读。文章篇幅会很长,主要还是记录一下我在阅读源码,包括梳理类之间关系的一个过程,源代码中我基本都标注了所在文件位置,方便有兴趣的读者可以沿着我的这个过程一起探索神秘的 dispatcher。
源码阅读
在源码部分,主要还是介绍类及各个类之间的关系为主,本文尝试由点及面的来进行源码阅读。所以还要从 Pytorch 统一的数据结构 IValue 类(interpreter value)说起。
IValue 类
前面我们已经提到,它是 Pytorch 中定义对数据的一个统一表达。从概念上,一个 16-byte IValue 类型由 3 个字段组成,一个 8-byte 的payload 类型,可以简单理解为指向相关数据的指针,4-byte 的 tag 则是表示 Ivalue 中包含的值是何种类型,最后一个是 1-byte 的 bool 类型,说明是否是 intrusive_ptr。
// aten/src/ATen/core/ivalue.h
struct TORCH_API IValue final {
IValue(const IValue& rhs)
: IValue(rhs.payload, rhs.tag, rhs.is_intrusive_ptr) {
if (is_intrusive_ptr && payload.u.as_intrusive_ptr != c10::UndefinedTensorImpl::singleton()) {
c10::raw::intrusive_ptr::incref(payload.u.as_intrusive_ptr);
}
}
...
};
其中 Payload 是一个嵌套联合体,为了使非 tensor 类拷贝起来更简单快捷,其定义为:
union Payload {
union TriviallyCopyablePayload {
TriviallyCopyablePayload() : as_int(0) {}
int64_t as_int;
double as_double;
bool as_bool;
c10::intrusive_ptr_target* as_intrusive_ptr;
struct {
DeviceType type;
DeviceIndex index;
} as_device;
} u;
at::Tensor as_tensor;
Payload() : u() {}
~Payload() {}
};
接下来是 Tag 则是对 IValue 可以包含数据类型的一个枚举:
enum class Tag : uint32_t {
#define DEFINE_TAG(x) x,
TORCH_FORALL_TAGS(DEFINE_TAG)
#undef DEFINE_TAG
};
#define TORCH_FORALL_TAGS(_) \
_(None) \
_(Tensor) \
_(Storage) \
_(Double) \
_(ComplexDouble) \
_(Int) \
_(Bool) \
_(Tuple) \
_(String) \
_(Blob) \
_(GenericList) \
_(GenericDict) \
_(Future) \
_(Device) \
_(Stream) \
_(Object) \
_(PyObject) \
_(Uninitialized) \
_(Capsule) \
_(RRef) \
_(Quantizer) \
_(Generator) \
_(Enum)
可以看到 IValue 可以包含很多种不同的类型,在 IValue 的定义中,设置了对应类型来初始化或者获取其中真实类型的操作相关:
// aten::Tensor 类型
IValue(at::Tensor t) : tag(Tag::Tensor), is_intrusive_ptr(false) {
new (&payload.as_tensor) at::Tensor(std::move(t));
}
bool isTensor() const {
return Tag::Tensor == tag;
}
at::Tensor toTensor() &&;
at::Tensor& toTensor() &;
const at::Tensor& toTensor() const&;
// Double
IValue(double d) : tag(Tag::Double), is_intrusive_ptr(false) {
payload.u.as_double = d;
}
bool isDouble() const {
return Tag::Double == tag;
}
double toDouble() const {
AT_ASSERT(isDouble());
return payload.u.as_double;
}
在 aten/src/ATen/core/ivalue_inl.h 中有对应成员函数的具体实现,感兴趣的读者可以自行阅读。通过 IValue 的统一数据表示,引出了 pytorch 中 boxing 和 unboxing 的概念。我们将 IValue 就可以看做是 Boxing,字面理解就是它会把各种各样的数据类型都打包起来,对外看起来是一致的,而相对的各种各样的类型就是 Unboxing 了。因为 unboxing 是对很多不同类型的统称,所以一般的 unboxing 形式的函数都是采用了模板形式来实现的。
schema
在 Pytorch 中一个算子都要有一个对应的 schema,基本上所有算子的schema 都定义在了 aten/src/ATen/native/native_functions.yaml 文件中,以字符串的形式呈现,下面以 torch.add 为例:
– func: add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
在 native_functions.yaml 中可以找到上述定义,最终通过脚本分析和代码生成,这个算子定义会被翻译成下面的形式:
namespace at {
TORCH_LIBRARY(aten, m) {
m.def("aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor");
}
这里就是上面提到的算子注册到 dispatch table 的第一步☝🏻。这里我们可以将 schema 看做是对一个算子的总体描述,这个描述包含了:算子名称,输入个数和类型,参数个数个类型,返回值类型等信息。继续深入,这里的字符串会在 m.def 里面被解析成 FunctionSchema 的类对象,让我们来看看相关源码:
// torch/include/torch/library.h
template <typename Schema>
Library& def(Schema&& raw_schema) & {
// 完美转发,调用 schema() 函数
c10::FunctionSchema s = schema(std::forward<Schema>(raw_schema));
return _def(std::move(s));
}
// schema() 函数的实现
inline c10::FunctionSchema schema(const char* s) {
return schema(s, c10::AliasAnalysisKind::FROM_SCHEMA);
}
inline c10::FunctionSchema schema(const char* str, c10::AliasAnalysisKind k) {
c10::FunctionSchema s = torch::jit::parseSchema(str);
s.setAliasAnalysis(k);
return s;
}
继续:
// torch/csrc/jit/frontend/function_schema_parser.cpp
C10_EXPORT FunctionSchema parseSchema(const std::string& schema) {
auto parsed = parseSchemaOrName(schema);
return parsed.right();
}
C10_EXPORT either<OperatorName, FunctionSchema> parseSchemaOrName(
const std::string& schemaOrName) {
return SchemaParser(schemaOrName).parseDeclarations().at(0);
}
讲过上面层层调用,最后在 SchemaParser(const std::string& str),函数中对具体的 schema 字符串进行解析,最终返回的是 FunctionSchema 类型。下面看一下 FunctionSchema 类型的定义:
struct FunctionSchema {
FunctionSchema(
std::string name,
std::string overload_name,
std::vector<Argument> arguments,
std::vector<Argument> returns,
bool is_vararg = false,
bool is_varret = false)
: name_({std::move(name), std::move(overload_name)}),
arguments_(std::move(arguments)),
returns_(std::move(returns)),
is_vararg_(is_vararg),
is_varret_(is_varret) {
checkSchema();
}
...
};
从上面的初始化参数可以看出字符串根据其内容,被解析出了对算子的一个更具体的描述。这里简单为 name 和 overload_name 的区别做一个说明,上述 add 算子的 name 为 aten::name,overload_name 为空。
-func: arange.start_out(Scalar start, Scalar end, Scalar step=1, *, Tensor(a!) out) -> Tensor(a!)
上述是定义在 native_functions.yaml 中的 arange 算子的某一个 schema,这里解析出来的 name 就是 aten::arange,overload_name 则是 start_out,所以一个算子定义的全名为:name+"."+overload_name 。所以最终我们字符串定义的 schema 会变成 c10::FunctionSchema 这个类,在后面的 dispatch 中会起到很大的索引作用。
OperatorHandle
前面介绍数据类型和算子的定义,下面就是要怎么实现算子和使用算子了。这个 Handle 类主要是用来处理一些已经注册了 schema 的算子,其主要有接口可以查询到已经注册 op 的 operator_name,包括查询/返回它的 FunctionSchema,还有就是注册函数的调用,其主要通过 OperatorDef 类及相关 list 迭代器实现,对外的接口。
// aten/src/ATen/core/dispatch/Dispatcher.h
class TORCH_API OperatorHandle {
public:
const OperatorName& operator_name() const {
return operatorDef_->op.operator_name();
}
bool hasSchema() const {
return operatorDef_->op.hasSchema();
}
const FunctionSchema& schema() const {
return operatorDef_->op.schema();
}
...
// 以 boxed 的方式调用函数
void callBoxed(Stack* stack) const {
c10::Dispatcher::singleton().callBoxed(*this, stack);
}
// 为了 unbox 的形式调用,这里还有一个 TypedOperatorHandle 类
template<class FuncType>
TypedOperatorHandle<FuncType> typed() const {
return TypedOperatorHandle<FuncType>(operatorIterator_);
}
void redispatchBoxed(DispatchKeySet ks, Stack* stack) const {
c10::Dispatcher::singleton().redispatchBoxed(*this, ks, stack);
}
private:
Dispatcher::OperatorDef* operatorDef_;
std::list<Dispatcher::OperatorDef>::iterator operatorIterator_;
};
这里的 TypedOperatorHandle 则是与 OperatorHandle 同样的功能,只是把 op 的参数模板化了,并且可以用 unboxed 的方式调用相关实现函数:
template<class Return, class... Args>
class TypedOperatorHandle<Return (Args...)> final : public OperatorHandle {
public:
// 以 unboxed 的方式调用函数
C10_ALWAYS_INLINE Return call(Args... args) const {
return c10::Dispatcher::singleton().call<Return, Args...>(*this, std::forward<Args>(args)...);
}
C10_ALWAYS_INLINE Return redispatch(DispatchKeySet currentDispatchKeySet, Args... args) const {
return c10::Dispatcher::singleton().redispatch<Return, Args...>(*this, currentDispatchKeySet, std::forward<Args>(args)...);
}
private:
explicit TypedOperatorHandle(std::list<Dispatcher::OperatorDef>::iterator operatorIterator)
: OperatorHandle(operatorIterator) {}
friend class OperatorHandle;
};
可以看到其就定义了两个 unbox 形式的调用函数。
KernelFunction
根据官方介绍这个类相当于 std::function,但是表示的是算子的 kernel 函数,可以从一个 Boxed/unboxed 的函数,仿函数,lambda 函数创建一个 kernekFunction,包括有需要它会自动适配到对应 boxed/unboxed。
// aten/src/ATen/core/boxing/KernelFunction.h
class TORCH_API KernelFunction final {
public:
// 3 种不同的函数形式,boxed 所有输入的都是 Stack,即 vector<IValue>;
using InternalBoxedKernelFunction = void(OperatorKernel*, const OperatorHandle&, DispatchKeySet, Stack*);
using BoxedKernelFunction = void(const OperatorHandle&, Stack*);
using BoxedKernelFunction_withDispatchKeys = void(const OperatorHandle&, DispatchKeySet, Stack*);
// 以 boxed 的方式调用函数
void callBoxed(const OperatorHandle& opHandle, DispatchKeySet dispatchKeySet, Stack* stack) const;
// 以 unboxed 的方式调用函数
template<class Return, class... Args>
Return call(const OperatorHandle& opHandle, DispatchKeySet dispatchKeySet, Args... args) const;
// 以 boxed/unboxed 的方式从 函数/仿函数/lambda 函数创建 KernelFunction
template<BoxedKernelFunction* func>
static KernelFunction makeFromBoxedFunction();
template<class FuncPtr, bool AllowLegacyTypes = false>
static KernelFunction makeFromUnboxedFunction(FuncPtr);
template<bool AllowLegacyTypes = false, class KernelFunctor>
static KernelFunction makeFromUnboxedFunctor(std::unique_ptr<OperatorKernel> kernelFunctor);
....
private:
OperatorKernel* getFunctor_() const;
std::shared_ptr<OperatorKernel> functor_;
InternalBoxedKernelFunction* boxed_kernel_func_; // 内部定义的 boxed 的函数指针
void* unboxed_kernel_func_; // 常规的函数指针
};
KernelFunction 更多的成员函数实现是在 aten/src/ATen/core/boxing/KernelFunction_impl.h 中,有兴趣的读者可以做额外展开阅读。
OperatorEntry
这个类是内部使用的,用户一般是不会直接访问到,是更底层记录算子的一些信息的,上层的相关类都是依赖 OperatorEntry 类实现的。
// aten/src/ATen/core/dispatch/OperatorEntry.h
class TORCH_API OperatorEntry final {
public:
// 使用 op name 即可初始化
explicit OperatorEntry(OperatorName&& operator_name);
// 获取相关算子的 schema
const FunctionSchema& schema() const {
return schema_->schema;
}
// 注册 schema
void registerSchema(FunctionSchema&&, std::string&& debug);
void deregisterSchema();
// 注册实现
std::list<AnnotatedKernel>::iterator registerKernel(
const Dispatcher& dispatcher,
c10::optional<DispatchKey> dispatch_key,
KernelFunction kernel,
c10::optional<CppSignature> cpp_signature,
std::unique_ptr<FunctionSchema> inferred_function_schema,
std::string debug
);
// 根据 dispatch key 查找相关 kernel
const KernelFunction& lookup(DispatchKey k) const {
const auto& kernel = dispatchTable_[static_cast<uint8_t>(k)];
if (C10_UNLIKELY(!kernel.isValidUnboxed())) {
if (!kernel.isValid()) {
reportError(k);
}
}
return kernel;
}
...
private:
OperatorName name_;
c10::optional<AnnotatedSchema> schema_;
std::array<KernelFunction, static_cast<uint8_t>(DispatchKey::NumDispatchKeys)> dispatchTable_;
DispatchKeyExtractor dispatchKeyExtractor_;
ska::flat_hash_map<DispatchKey, std::list<AnnotatedKernel>> kernels_;
...
};
Dispatcher
这个是动态分发的主要类,但是不是用户直接可以用的。注册相关 op 函数kernel 可以使用 aten/src/ATen/core/op_registration/op_registration.h 的 RegisterOperators 类。
// aten/src/ATen/core/dispatch/Dispatcher.h
class TORCH_API Dispatcher final {
private:
// For direct access to backend fallback information
friend class impl::OperatorEntry;
struct OperatorDef final {
explicit OperatorDef(OperatorName&& op_name)
: op(std::move(op_name)) {}
impl::OperatorEntry op;
size_t def_count = 0;
size_t def_and_impl_count = 0;
};
friend class OperatorHandle;
template<class> friend class TypedOperatorHandle;
public:
~Dispatcher();
static Dispatcher& realSingleton();
// 全局只需要一个 diapatch table
C10_ALWAYS_INLINE static Dispatcher& singleton() {
return realSingleton();
}
// 通过 schema 查找来访问 operator
c10::optional<OperatorHandle> findSchema(const OperatorName& operator_name);
OperatorHandle findSchemaOrThrow(const char* name, const char* overload_name);
c10::optional<OperatorHandle> findOp(const OperatorName& operator_name);
// 调用算子
template<class Return, class... Args>
Return call(const TypedOperatorHandle<Return (Args...)>& op, Args... args) const;
template<class Return, class... Args>
static Return callWithDispatchKeySlowPath(const TypedOperatorHandle<Return (Args...)>& op, bool pre_sampled, DispatchKeySet dispatchKeySet, const KernelFunction& kernel, Args... args);
void callBoxed(const OperatorHandle& op, Stack* stack) const;
// 注册一个新的算子 schema
RegistrationHandleRAII registerDef(FunctionSchema schema, std::string debug);
// 注册一个算子 kernel 到 dispatch table 上
RegistrationHandleRAII registerImpl(OperatorName op_name, c10::optional<DispatchKey> dispatch_key, KernelFunction kernel, c10::optional<impl::CppSignature> cpp_signature, std::unique_ptr<FunctionSchema> inferred_function_schema, std::string debug);
...
};
内部调用逻辑
针对不同的算子 schem,它们都有一个最终的算子调用过程,内部实现一个很常规的方法是使用 dispatcher 类的方法,下面以 abs 算子为例,因为其输入是 unboxed 的 tensor 类型,所以需要以 Unboxed 的形式:
at::Tensor & Tensor::abs_() const {
static auto op = c10::Dispatcher::singleton() // 返回一个 static 的 dispatcher 对象
.findSchemaOrThrow("aten::abs_", "") // 返回 OperatorHandle 类
.typed<at::Tensor & (at::Tensor &)>(); // 返回 TypedOperatorHandle 类
return op.call(const_cast<Tensor&>(*this)); // 最后调用 TypedOperatorHandle 的 call 函数
}
下面我们就深入追踪一下这个 op.call 函数:
// aten/src/ATen/core/dispatch/Dispatcher.h
// 返回来调用 dispatcher 类中定义的 call 函数
C10_ALWAYS_INLINE Return call(Args... args) const {
return c10::Dispatcher::singleton().call<Return, Args...>(*this, std::forward<Args>(args)...);
}
diapatcher 类对 call 的定义为:
template<class Return, class... Args>
C10_DISPATCHER_INLINE_UNLESS_MOBILE Return Dispatcher::call(const TypedOperatorHandle<Return(Args...)>& op, Args... args) const {
detail::unused_arg_(args...);
// 获取当前 dispatchKeySet
auto dispatchKeySet = op.operatorDef_->op.dispatchKeyExtractor()
.template getDispatchKeySetUnboxed<Args...>(args...);
// 根据 最好优先级 key 来找到当前应该派发的 KernelFunction
const KernelFunction& kernel = op.operatorDef_->op.lookup(dispatchKeySet.highestPriorityTypeId());
// 最后调用 KernelFunction 类的 call 函数
return kernel.template call<Return, Args...>(op, dispatchKeySet, std::forward<Args>(args)...);
}
最后又调用了 KernelFunction 中的 call 函数:
template<class Return, class... Args>
C10_ALWAYS_INLINE Return KernelFunction::call(const OperatorHandle& opHandle, DispatchKeySet dispatchKeySet, Args... args) const {
// 如果是 unboxed 形式的函数
if (C10_LIKELY(unboxed_kernel_func_ != nullptr)) {
return callUnboxedKernelFunction<Return, Args...>(unboxed_kernel_func_, functor_.get(), dispatchKeySet, std::forward<Args>(args)...);
}
// 如果是 boxed 形式的函数
return impl::BoxedKernelWrapper<Return(Args...)>::call(
boxed_kernel_func_,
functor_.get(),
opHandle,
dispatchKeySet,
std::forward<Args>(args)...
);
}
如果是 unboxed 的行为:
// aten/src/ATen/core/boxing/KernelFunction_impl.h
template<class Return, class... Args>
inline Return callUnboxedKernelFunction(void* unboxed_kernel_func, OperatorKernel* functor, DispatchKeySet dispatchKeySet, Args&&... args) {
using ActualSignature = Return (OperatorKernel*, DispatchKeySet, Args...);
ActualSignature* func = reinterpret_cast<ActualSignature*>(unboxed_kernel_func);
// 将相关参数传入,unboxed_kernel_func 运行
return (*func)(functor, dispatchKeySet, std::forward<Args>(args)...);
}
如果是 boxed 的行为:
// aten/src/ATen/core/boxing/KernelFunction_impl.h
static Result call(
KernelFunction::InternalBoxedKernelFunction* boxed_kernel_func,
OperatorKernel* functor,
const OperatorHandle& opHandle,
DispatchKeySet dispatchKeySet,
Args... args
) {
torch::jit::Stack stack = boxArgs<Args...>(std::forward<Args>(args)...);
// 将相关参数传入,boxed_kernel_func 运行
(*boxed_kernel_func)(functor, opHandle, dispatchKeySet, &stack);
......
);
}
所以整理上述过程,要调用一个算子底层实现的过程是:
- 通过 dispatcher 类 + op name 的形式来查找对应的算子 schema 。因为 schema 中定义了相关的算子输入、输出、参数的相关信息。
- 其中 FunctionSchema 类只是记录,想要具体访问还是要使用 OperatorHandle 类,所以上面返回的是 OperatorHandle 类对象。
- 因为算子的输入基本都是 scalar / tensor 这种 Unboxed 类型的参数,所以要进一步根据输入参数和返回类型来获取 TypedOperatorHandle 类,并调用相关的 call 函数
-
TypedOperatorHandle::call (已经获得了函数的返回类型和输入参数个数及类型)
-
dispatcher::call (通过 dispatcher 中的 dispatchKetSet 等,找到当前最高优先级的 Key 并找到对应的 KernelFunction 类)
-
KernelFunction::call (KernelFunction 中有 unboxed_kernel_func_ 和 boxed_kernel_func_两个成员变量,用来代表其记录的相关的函数指针,这里根据当前带有的是 unboxed 的还是 boxed 的 kernel function 来决定最后的调用方式)
kernel 是如何注册上的
前面提到过,kernel 的注册主要是使用了 m.impl 接口,这里就从源码的角度来看一下 m.impl 是如何将 kernel 塞进 dispatch table 的。这里以 conv 算子为例,重温一下注册 kernel 的语法:
TORCH_LIBRARY_IMPL(aten, CompositeImplicitAutograd, m) {
m.impl("conv2d", TORCH_FN(wrapper__conv2d));
}
这里主要是 TORCH_LIBRARY_IMPL 这个宏中定义的 Library 类:
// torch/library.h
template <typename Name, typename Func>
Library& impl(Name name, Func&& raw_f) & {
CppFunction f(std::forward<Func>(raw_f));
return _impl(name, std::move(f));
}
// 注册实现
RegistrationHandleRAII Dispatcher::registerImpl(
OperatorName op_name,
c10::optional<DispatchKey> dispatch_key,
KernelFunction kernel,
c10::optional<impl::CppSignature> cpp_signature,
std::unique_ptr<FunctionSchema> inferred_function_schema,
std::string debug
) {
std::lock_guard<std::mutex> lock(mutex_);
auto op = findOrRegisterName_(op_name);
auto handle = op.operatorDef_->op.registerKernel(
*this,
dispatch_key,
std::move(kernel),
// NOLINTNEXTLINE(performance-move-const-arg)
std::move(cpp_signature),
std::move(inferred_function_schema),
std::move(debug)
);
++op.operatorDef_->def_and_impl_count;
return RegistrationHandleRAII([this, op, op_name, dispatch_key, handle] {
deregisterImpl_(op, op_name, dispatch_key, handle);
});
}
通过 TORCH_LIBRARY_IMPL 宏来访问 Library 类的 _impl 函数,在 _impl 函数中对 op name 及相关的 dispatch_key 进行 check,最后调用 Dispatcher 类的 registerImpl 接口,在内部调用 OperatorEntry 类的 registerKernel 接口将函数塞进 Dispatcher 类,并更新相关的 DispatchTable。
at::Tensor wrapper__conv2d(const at::Tensor & input, const at::Tensor & weight, const c10::optional<at::Tensor> & bias, at::IntArrayRef stride, at::IntArrayRef padding, at::IntArrayRef dilation, int64_t groups) {
return at::native::conv2d(input, weight, bias, stride, padding, dilation, groups);
}
// 层层调用
// aten/src/ATen/native/Convolution.cpp
at::Tensor conv2d(
const Tensor& input, const Tensor& weight, const c10::optional<Tensor>& bias,
IntArrayRef stride, c10::string_view padding, IntArrayRef dilation,
int64_t groups) {
return at::_convolution_mode(
input, weight, bias, stride, std::move(padding), dilation, groups);
}
// build/aten/src/ATen/Functions.cpp
at::Tensor _convolution_mode(const at::Tensor & input, const at::Tensor & weight, const c10::optional<at::Tensor> & bias, at::IntArrayRef stride, c10::string_view padding, at::IntArrayRef dilation, int64_t groups) {
static auto op = c10::Dispatcher::singleton()
.findSchemaOrThrow("aten::_convolution_mode", "")
.typed<at::Tensor (const at::Tensor &, const at::Tensor &, const c10::optional<at::Tensor> &, at::IntArrayRef, c10::string_view, at::IntArrayRef, int64_t)>();
return op.call(input, weight, bias, stride, padding, dilation, groups);
}
上面就是通过相关接口 dispatch 函数的调用。
首先需要注册相关 schema 及 impl(kernel),调用的时候就是先实例化一个 dispatcher 对象,然后通过 op name 获取这个算子的 operatorHandle,并且根据 box/unbox 和 dispatchkey 来最后调用实现的对应算子 kernel。
根据数据类型再次分发
之前在介绍 Tensor C++ 相关实现中提到,一个算子在调用过程中可能还会根据具体的数值类型进行再次分发,当时是用下面的图表示的:
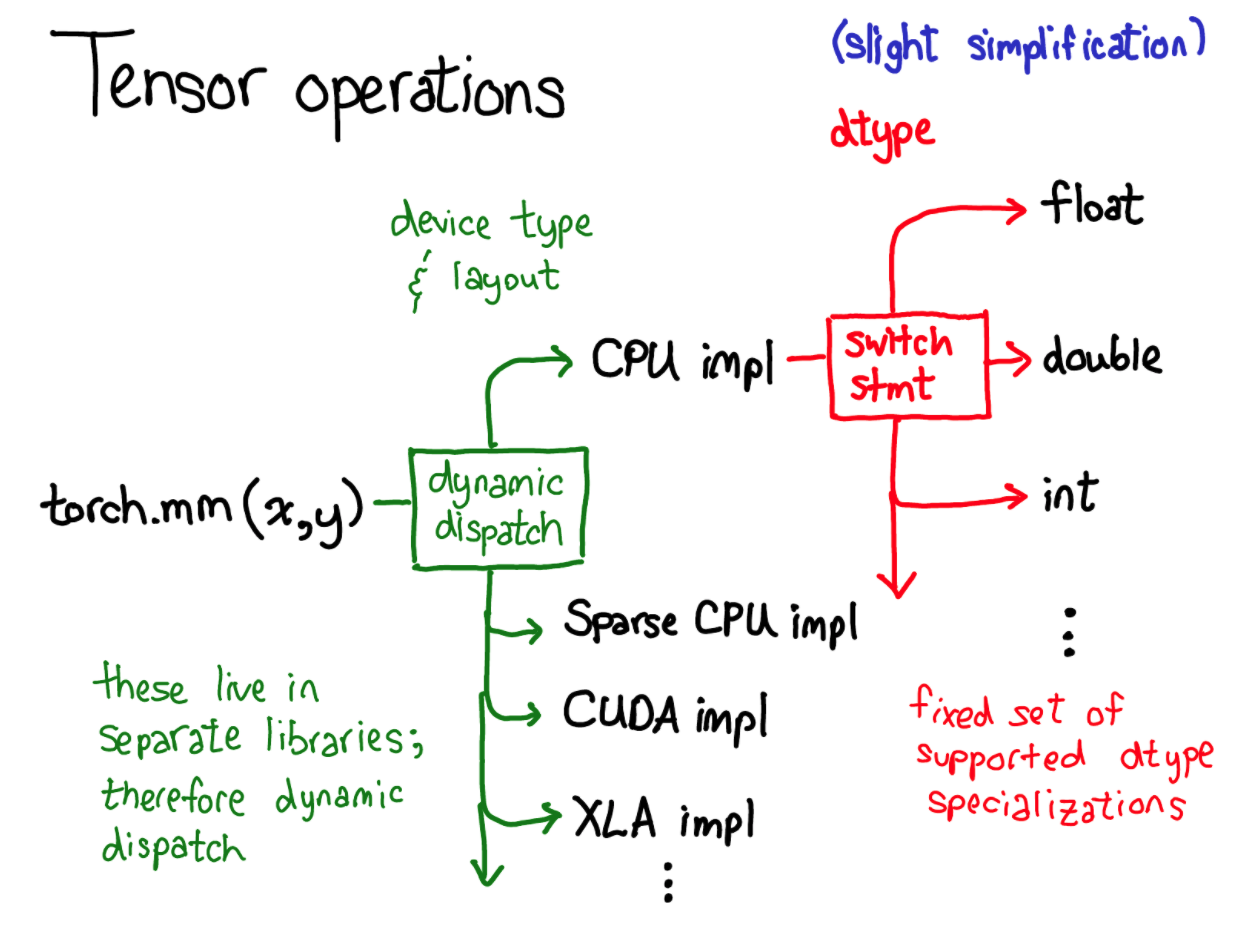
我们上面介绍的 dispacther 相关内容都是绿色部分,根据 device type,layout 等信息进行动态分发,下面简单对红色的部分进行一个源码定位。
Pytorch 中有很多带有 AT_DISPATCH_ALL_TYPES 关键字的宏来做相关的根据类型分发的内容,下面以 logical_xor 算子为例进行说明,首先来看一下这个算子的实现函数:
// aten/src/ATen/native/BinaryOps.cpp
Tensor logical_xor(const Tensor& self, const Tensor& other) {
return comparison_op(self, other, static_cast<OutFunc>(at::logical_xor_out));
}
template <typename OutImpl>
Tensor comparison_op(
const Tensor& self,
const Scalar& other,
OutImpl& out_impl) {
return comparison_op(
self, wrapped_scalar_tensor_and_check_convert(other, self), out_impl);
}
static Tensor wrapped_scalar_tensor_and_check_convert(
const Scalar& scalar,
Tensor tensor) {
check_convert(scalar, tensor.scalar_type());
return wrapped_scalar_tensor(scalar);
}
最后是在 check_convert 函数中调用了相关的分发的宏:
static void check_convert(const Scalar& scalar, ScalarType scalarType) {
// Validate that is possible to convert scalar to tensor dtype without
// overflow
AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND3(
at::ScalarType::Bool,
at::ScalarType::BFloat16,
at::ScalarType::Half,
scalarType,
"check_convert",
[&] { scalar.to<scalar_t>(); });
}
#define AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND3( \
SCALARTYPE1, SCALARTYPE2, SCALARTYPE3, TYPE, NAME, ...) \
[&] { \
const auto& the_type = TYPE; \
/* don't use TYPE again in case it is an expensive or side-effect op*/ \
at::ScalarType _st = ::detail::scalar_type(the_type); \
RECORD_KERNEL_FUNCTION_DTYPE(NAME, _st); \
switch (_st) { \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Byte, uint8_t, __VA_ARGS__) \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Char, int8_t, __VA_ARGS__) \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Double, double, __VA_ARGS__) \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Float, float, __VA_ARGS__) \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Int, int32_t, __VA_ARGS__) \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Long, int64_t, __VA_ARGS__) \
AT_PRIVATE_CASE_TYPE(NAME, at::ScalarType::Short, int16_t, __VA_ARGS__) \
...
可以看到其是采用宏的方式来代替冗长的 switch…case 的操作。
总结
纸上得来终觉浅,虽然后来在 Linux 中配置了可以 debug 的 Pytorch 源码,不过主要还是单纯的通过梳理函数调用之间的关系得到的,介绍的可能会忽略掉一些比较重要的内容,不过到这里基本就对 Pytorch dispatcher 有了更深一步的认识,虽然可能各个类之间相互交错,如果自己可以跟一遍下来相信还是能对你有所帮助的。

















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









