










版本说明
因为 Pytorch 版本迭代还是蛮快的,这里给出我源码阅读的版本及 commit 号以供参考。
master 分支,commit 号: 047925dac1c07a0ad2c86c281fac5610b084d1bd
概念介绍
Tensor 是 Pytorch 核心的数据结构,使用过 pytorch 的同学想必都不会陌生,它可以包含 scalar type 的数据(例如 floats,ints 等),我们可以把 Pytorch 中 tensor 这一数据结构看做是包含了一些数据,并且带有描述这些数据其他信息,例如数据的 size,数据类型 dtype,数据指针在哪个设备上 device ,数据是如何摆放的 layout等。
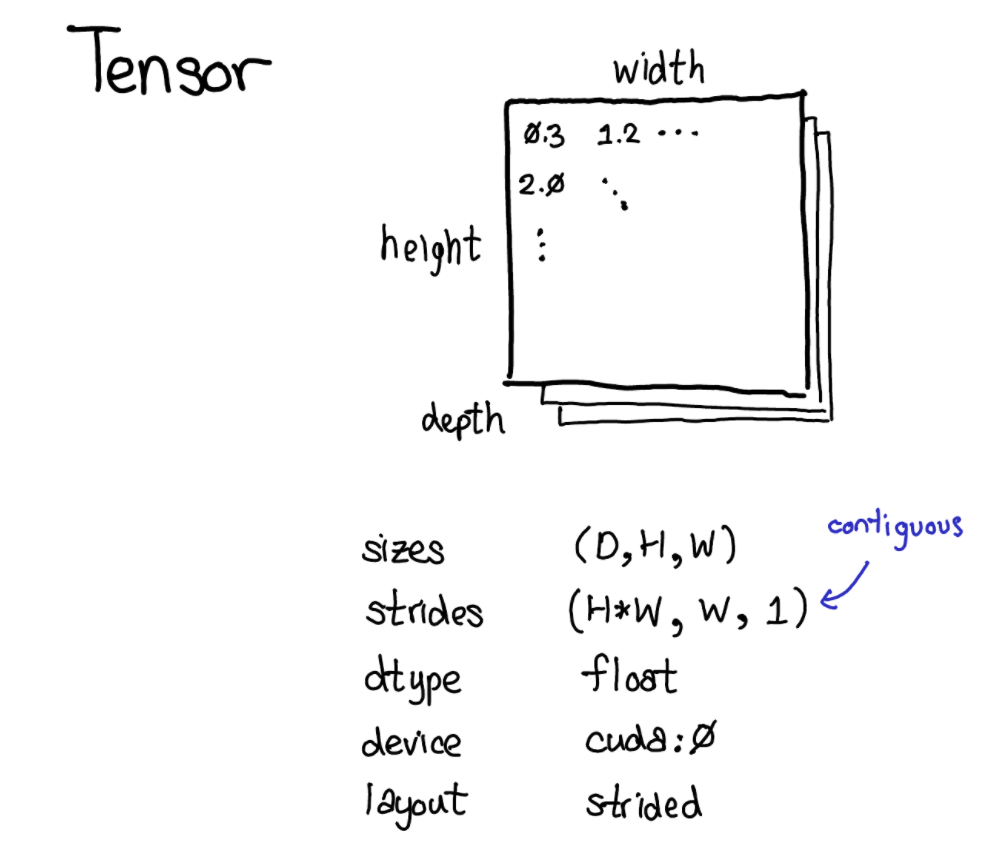
另外还包含一些我们可能不太熟悉的数据描述:Stride。
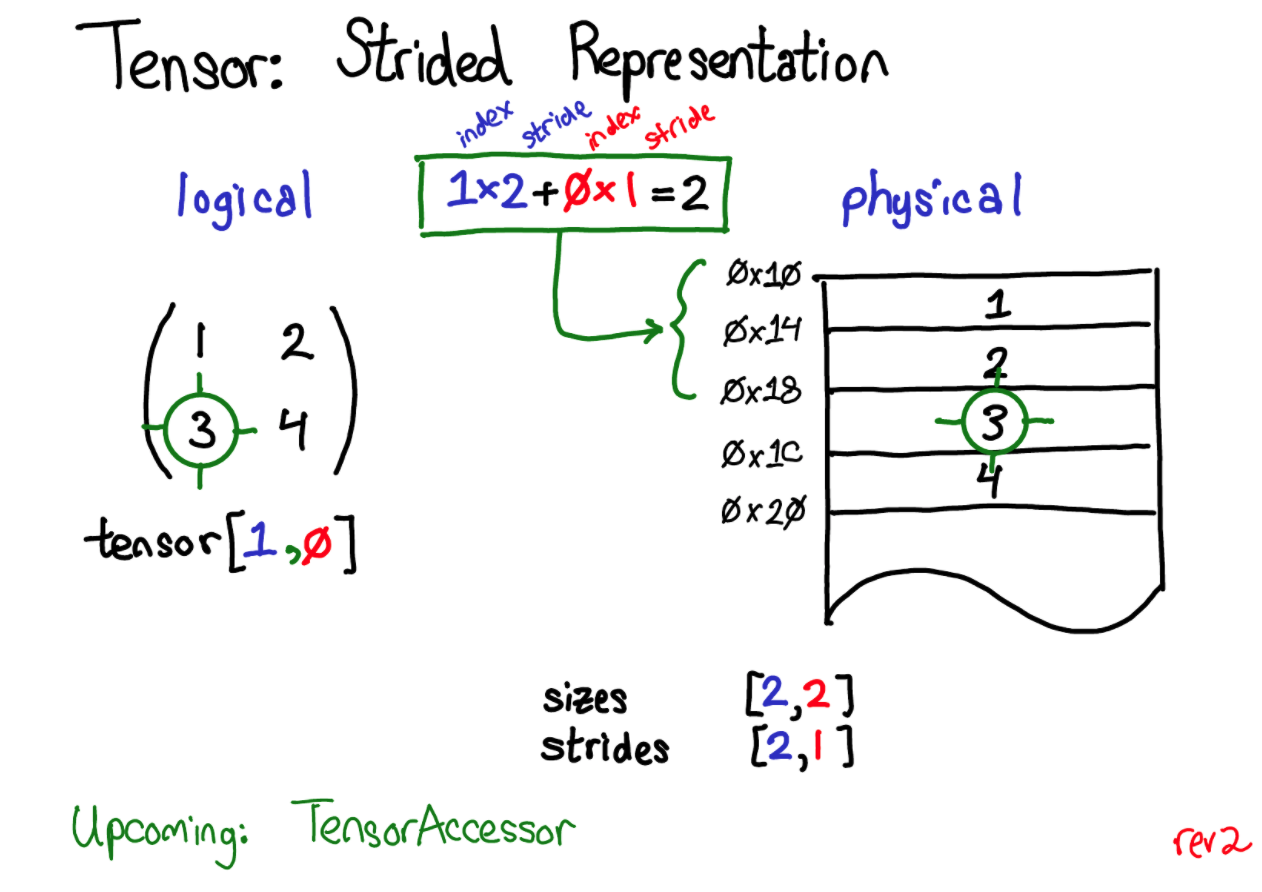
我们的 tensor 在表示上是一个多维的数组,例如 [2,2],但是在物理内存上数据却是连续摆放的,因此 Pytorch 通过 stride 这一属性来对索引进行转换,便于根据索引找到具体的数据物理地址的偏移量。就很好理解下面两种不同的情况下所对应的 stride 含义了。
 ||
|| 
通过上面的介绍可以了解到 tensor 表示数据,在逻辑上我们可以直接通过索引来对部分数据进行操作,对应到底层物理上的数据操作,而 pytorch 将逻辑上的连续和物理上的分离是用两个不同的类来表示的:
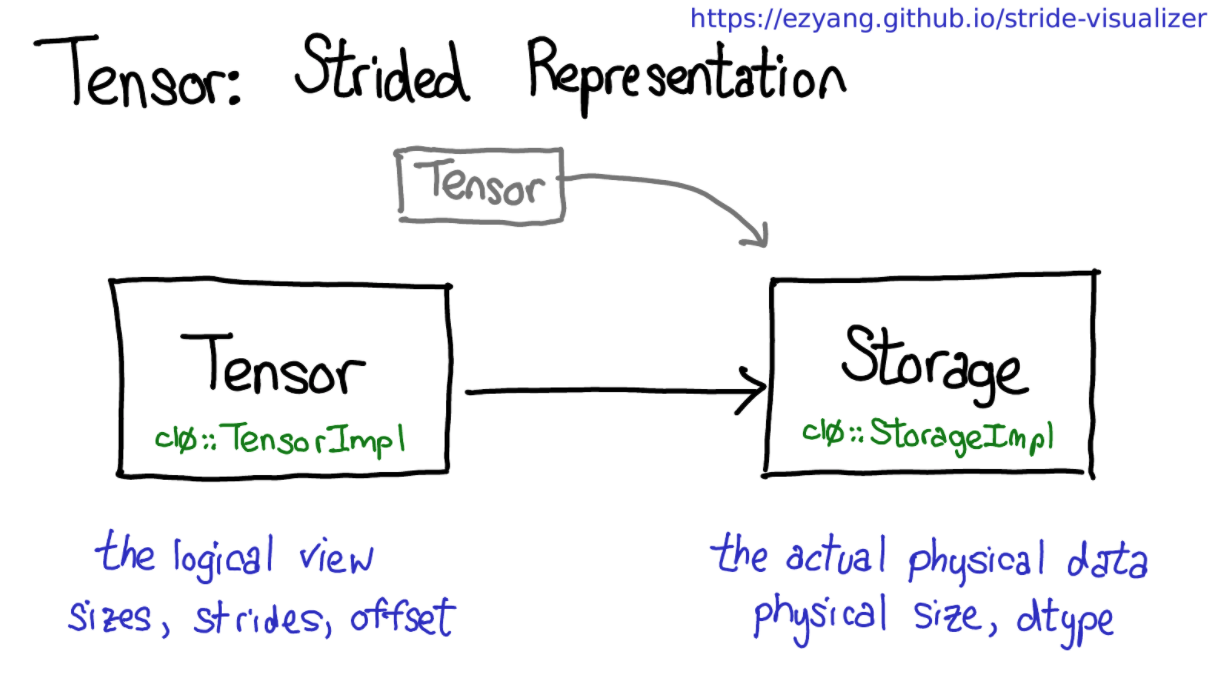
即: Tensor 类来描述数据的逻辑操作, Storage 描述实际需要的物理操作。
下面 3 个属性决定了每一个 tensor 都是独一无二的:
- device: 描述数据实际存储在哪里,是在 CPU 上还是在 GPU 上或者在其他设备上,每一个设备有自己的内存分配器。
- layout:描述了我们如何从逻辑上解释物理内存。 Stride 摆放的,还是 sparse 的。
- dtype:描述实际存储数据的类型。
然后再实际的 tensor 操作中,根据 tensor 的属性不同还要涉及到 dispatch(函数分发)这一概念:
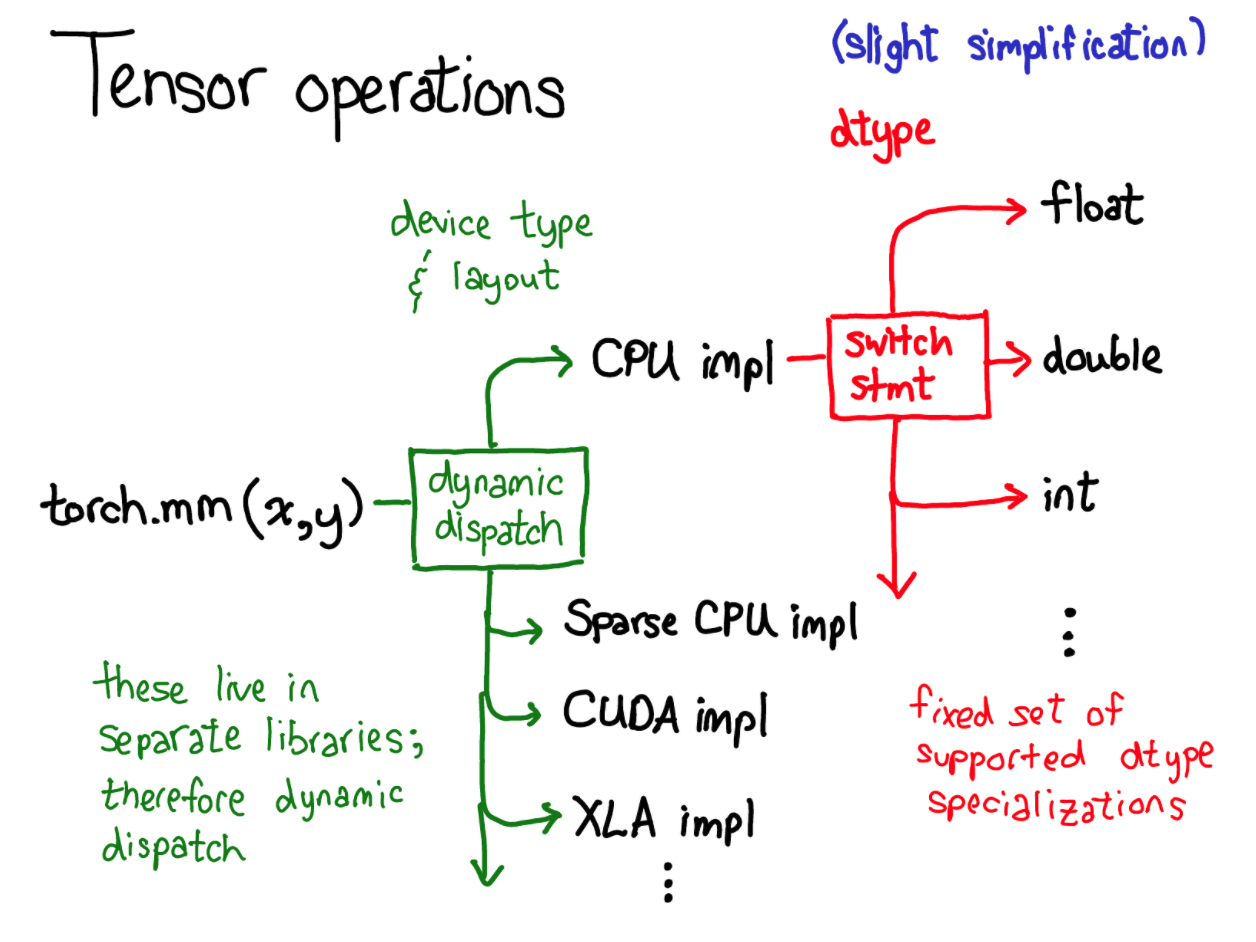
上面是这一过程的简化版。以 torch.mm 矩阵乘为例,根据 device 和 layout 先动态分发到对应的实现函数,因为不同设备及不同存储实现起来必然不一样,然后在对应的实现函数中又根据基本的数据类型来再次分发,对 float 的实现和对 int 的实现肯定也是不同的,dispatch 也是 Pytorch 的一大特性,后面值得学习一番。
接下来我们就从代码的层面上看一下 Pytorch 的 tensor 这一概念。结合对相关概念的描述来看下面的源码可能会更加有方向一些,因为一些类很庞大,这里就只罗列处了部分成员变量/函数,感兴趣的读者还是建议沿着本文脉络去看完整的源码,下面也都给出了代码所在路径。
源码分析
intrusive_ptr 类
在具体介绍 tensor 相关源码之前需要先介绍一下实现它们的基础,c10::intrusive_ptr 类,其就是 Pytorch 管理自己数据的智能指针类。首先要介绍 intrusive_ptr_target 类,其定义了用来管理智能指针的引用计数变量等,作为外部需要使用智能指针 intrusive_ptr 类的父类。
// c10/util/intrusive_ptr.h
class C10_API intrusive_ptr_target {
mutable std::atomic<size_t> refcount_; // 原子特性,引用计数
mutable std::atomic<size_t> weakcount_; // 弱引用计数,为了防止循环引用
// 声明友元使得能指针访问 refcount_ 等
template <typename T, typename NullType>
friend class intrusive_ptr;
friend inline void raw::intrusive_ptr::incref(intrusive_ptr_target* self);
template <typename T, typename NullType>
friend class weak_intrusive_ptr;
friend inline void raw::weak_intrusive_ptr::incref(
intrusive_ptr_target* self);
protected:
// 隐藏析构函数,防止直接析构对象
virtual ~intrusive_ptr_target() {
// check refcount_ 和 weakcount_ 是否都为 0
}
// 如果初始化的 refcount_>0,weakcount_>0 会
constexpr intrusive_ptr_target() noexcept : refcount_(0), weakcount_(0) {}
// 支持复制和移动操作,但是并不会改变引用计数,只有 TTarget* 的指针被复制/移动
// 移动构造
intrusive_ptr_target(intrusive_ptr_target&& other) noexcept
: intrusive_ptr_target() {}
// 移动赋值
intrusive_ptr_target& operator=(intrusive_ptr_target&& other) noexcept {
return *this;
}
// 拷贝构造
intrusive_ptr_target(const intrusive_ptr_target& other) noexcept
: intrusive_ptr_target() {}
// 拷贝赋值
intrusive_ptr_target& operator=(const intrusive_ptr_target& other) noexcept {
return *this;
}
private:
// 释放相关资源
virtual void release_resources() {}
};
如果自定义的类 T 想使用 c10::intrusive_ptr<T> 就必须继承自 intrusive_ptr_target 类。下面是源码中随处可见的 c10::intrusive_ptr 类:
// c10/util/intrusive_ptr.h
template <
class TTarget,
class NullType = detail::intrusive_target_default_null_type<TTarget>>
class intrusive_ptr final {
private:
TTarget* target_; // 被引用对象的普通指针
public:
using element_type = TTarget;
intrusive_ptr() noexcept
: intrusive_ptr(NullType::singleton(), raw::DontIncreaseRefcount{}) {}
// 构造函数,这里省略了检查 refcount_ 和 weakcount_ 是否都为 0 的部分
explicit intrusive_ptr(TTarget* target)
: intrusive_ptr(target, raw::DontIncreaseRefcount{}) {
target_->refcount_.store(1, std::memory_order_relaxed); // ++refcount_
target_->weakcount_.store(1, std::memory_order_relaxed); // ++weakcount_
}
}
// 移动构造
intrusive_ptr(intrusive_ptr&& rhs) noexcept : target_(rhs.target_) {
rhs.target_ = NullType::singleton(); // 先初始化 target_, set rhs to null
}
// 拷贝构造
intrusive_ptr(const intrusive_ptr& rhs) : target_(rhs.target_) {
retain_(); // 被拷贝,引用计数加1,++target_ -> refcount_
}
// make_intrusive 用的就是这个接口,在初始化中完成了引用计数+1 的操作
template <class... Args>
static intrusive_ptr make(Args&&... args) {
return intrusive_ptr(new TTarget(std::forward<Args>(args)...));
}
// intrusive_ptr 转化为普通指针
TTarget* release() noexcept {
// NOLINTNEXTLINE(clang-analyzer-core.uninitialized.Assign)
TTarget* result = target_;
target_ = NullType::singleton();
return result;
}
// 普通指针转化为 intrusive_ptr,但是不增加引用计数
static intrusive_ptr reclaim(TTarget* owning_ptr) {
return intrusive_ptr(owning_ptr, raw::DontIncreaseRefcount{});
}
// 还有其余一些操作符重载,支持正常指针计算,
...
};
// make_intrusive
template <
class TTarget,
class NullType = detail::intrusive_target_default_null_type<TTarget>,
class... Args>
inline intrusive_ptr<TTarget, NullType> make_intrusive(Args&&... args) {
return intrusive_ptr<TTarget, NullType>::make(std::forward<Args>(args)...);
}
由上面的 make_intrusive 的过程:
- 首先完美转发所有的参数来构建 intrusive_ptr
- 用这些参数 new 一个新的 TTarget 类型的对象
- 用新的 TTarget 对象构造一个 intrusive_ptr
- 构造 intrusive_ptr 的同时对 refcount_ 和 weakcount_ 都加 1,如果是默认构造,则两个引用计数都默认为 0,根据这个可以将通过 make_intrusive 构造的指针与堆栈上的会被自动析构的情况分开, 用来确保内存是我们自己分配的。
还要一个类似的智能指针 weak_intrusive_ptr 类基本实现同上。
TensorImpl 类
// torch/include/c10/core/TensorImpl.h
struct C10_API TensorImpl : public c10::intrusive_ptr_target {
TensorImpl() = delete;
// 对应上面的概念分析,device, layout,dtype
TensorImpl(
Storage&& storage, // 传入数据存储类
DispatchKey dispatch_key, // 分发的 key ,决定调用哪些实现函数
const caffe2::TypeMeta data_type)
: TensorImpl(
std::move(storage),
DispatchKeySet(dispatch_key),
data_type) {}
TensorImpl(DispatchKey dispatch_key, const caffe2::TypeMeta data_type, c10::optional<c10::Device> device_opt)
: TensorImpl(DispatchKeySet(dispatch_key), data_type, device_opt) {}
public:
TensorImpl(const TensorImpl&) = delete;
TensorImpl& operator=(const TensorImpl&) = delete;
TensorImpl(TensorImpl&&) = default;
TensorImpl& operator=(TensorImpl&&) = default;
// 返回 tensor 对应的分发键值决定需要分发时,调用哪些实现函数
DispatchKeySet key_set() const { return key_set_; }
virtual IntArrayRef strides() const; // stride 属性
// 返回 Tensor 底层的 storage 类,多个 tensor 可能共享同一个 storage
virtual const Storage& storage() const;
// 返回总的数据个数,例如 [n,c,h,w],返回 n*c*h*w
TENSORIMPL_MAYBE_VIRTUAL int64_t numel() const {
return numel_;
}
// 返回数据维度信息
TENSORIMPL_MAYBE_VIRTUAL IntArrayRef sizes() const {
return sizes_and_strides_.sizes_arrayref();
}
// 设备
Device device() const {
TORCH_CHECK(
device_opt_.has_value(),
"tensor does not have a device");
// See NOTE [c10::optional operator usage in CUDA]
return *device_opt_;
}
// layout 信息
Layout layout() const {
// NB: This method is not virtual and avoid dispatches for perf.
if (is_sparse()) {
return kSparse;
} else if (is_mkldnn()) {
return kMkldnn;
} else {
return kStrided;
}
}
// 返回描述数据
const caffe2::TypeMeta dtype() const {
return data_type_;
}
// 可以直接访问 tensor 中的 scalar 数据
template <typename T>
inline T * data() const {
// 这里省略了一些条件检查
return storage_.unsafe_data<T>() + storage_offset_;
}
// 这里是与 python 交互的 PyObject 对象
inline PyObject* pyobj() const noexcept {
return pyobj_;
}
// 还包含了很多其他一些关于 tensor 的相关函数, 函数浅拷贝,reshape,resize 等
};
StorageImpl 类
// torch/include/c10/core/StorageImpl.h
// 这里为了简便,只罗列处了部分函数
struct C10_API StorageImpl final : public c10::intrusive_ptr_target {
public:
struct use_byte_size_t {};
StorageImpl(
use_byte_size_t use_byte_size,
size_t size_bytes,
at::DataPtr data_ptr,
at::Allocator* allocator,
bool resizable)
: data_ptr_(std::move(data_ptr)),
size_bytes_(size_bytes),
resizable_(resizable),
received_cuda_(false),
allocator_(allocator) {
if (resizable) {
TORCH_INTERNAL_ASSERT(
allocator_, "For resizable storage, allocator must be provided");
}
}
StorageImpl(
use_byte_size_t use_byte_size,
size_t size_bytes,
at::Allocator* allocator,
bool resizable)
: StorageImpl(
use_byte_size_t(),
size_bytes,
allocator->allocate(size_bytes),
allocator,
resizable) {}
// 相关构造函数的设置
StorageImpl& operator=(StorageImpl&& other) = default;
StorageImpl& operator=(const StorageImpl&) = delete;
StorageImpl() = delete;
StorageImpl(StorageImpl&& other) = default;
StorageImpl(const StorageImpl&) = delete;
~StorageImpl() = default;
// 重置
void reset() {
data_ptr_.clear();
size_bytes_ = 0;
}
// 直接返回底层数据指针
template <typename T>
inline T* data() const {
return unsafe_data<T>();
}
template <typename T>
inline T* unsafe_data() const {
return static_cast<T*>(this->data_ptr_.get());
}
// 释放资源
void release_resources() override {
data_ptr_.clear();
}
// 返回数据占用空间
size_t nbytes() const {
return size_bytes_;
}
at::DataPtr& data_ptr() {
return data_ptr_;
};
// Returns the previous data_ptr
at::DataPtr set_data_ptr(at::DataPtr&& data_ptr) {
std::swap(data_ptr_, data_ptr);
return std::move(data_ptr);
};
void* data() {
return data_ptr_.get();
}
// 返回空间配置器
at::Allocator* allocator() {
return allocator_;
}
// 返回数据指针所在的设备类型
Device device() const {
return data_ptr_.device();
}
private:
DataPtr data_ptr_; // 数据指针
size_t size_bytes_; // 数据占用大小
bool resizable_;
// Identifies that Storage was received from another process and doesn't have
// local to process cuda memory allocation
bool received_cuda_;
Allocator* allocator_; // 空间配置器
};
// torch/include/c10/core/Storage.h
// storage 就是
struct C10_API Storage {
public:
struct use_byte_size_t {};
Storage() {}
// 构造函数
Storage(c10::intrusive_ptr<StorageImpl> ptr) : storage_impl_(std::move(ptr)) {}
// 其他成员函数均是对 StorageImpl 类的一层简单调用
...
protected:
c10::intrusive_ptr<StorageImpl> storage_impl_;
};
总结
这里对上面的类之间的关系做一个小结,了解了上述内容,不仅使 tensor 这一概念更加立体了,并且在日常使用的过程中,尤其 libtorch,C++ 对 pytorch 进行开发时,可以更有方向性的查看相关类的接口是否可以满足自己的需求。

c10::intrusive_ptr 的初始化需要 intrusive_ptr_target 或者其子类。
TensorImpl 和 StorageImpl 两个类分别为intrusive_ptr_target 的子类,然后StorageImpl 主要负责 tensor 的实际物理内存相关的操作,设置空间配置器,获取数据指针,以及占用物理空间大小等; Storage 仅仅是对 StorageImpl 直接包了一下,直接调用的是 StorageImpl 的相关成员函数。TensorImpl 是 Tensor 类实现的主要依赖类,,其初始化就需要依赖 Storage 类,所以上面说:Tensor = TensorImpl + StorgaeImpl。
tensor 相关概念的参考主要是下面这篇博客,写的很好,建议阅读一下:
http://blog.ezyang.com/2019/05/pytorch-internals/















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









