







编译原理期末复习题(第二部分)
1.期末试卷题型
全部为解答题,共11道!
无选择、判断、填空题
2.考点集锦
第三章 语法分析
1.语法分析的任务、方法、分析依据
2.形式语言分类
3.文法、语言、句型、句子
4.短语、直接短语、素短语、句柄,语法树
5.规范推导、规范规约
6.项目和项目集规范族
7.文法二义性的判定
8. 消除文法的左递归和回溯
9. 构造文法的递归下降分析程序
10. LL(1)分析法(构造FIRST集和FOLLOW 集、构造分析表、LL(1)文法的判定、分析过程)
11. LR分析法(LR(0),SLR(1)分析表的构造, SLR(1)文法的判定、分析过程)
第四章 语义分析与中间代码生成
1.语义分析的任务、方法、分析依据
2.语法制导翻译,语义规则,带注释的语法分析树
3.文法符号的属性分类、四元式
4.算数表达式、布尔表达式的翻译
5.控制语句的翻译(if-else、while、for,依据代码结构图给出四元式序列)
第五章 代码优化
1.代码优化的含义、目的、种类
2.基本块的定义、划分方法(入口、出口)
3.基本块的DAG优化方法
3.各章例题集锦
第三章
——> 题型一:计算First/Follow集
1.计算下列文法的FIRST和FOLLOW集合
G[S]: S→S ( S ) S | ε
答:修改文法为:
G’[S]: S→S’
S’→ ( S ) SS’ | ε
First(S)= {ε,(}
First(S’)= {ε,(}
Follow(S)= {#,(,)}
Follow(S’)= {#,(,)}
——> 题型二:LL(1)——自顶向下分析法
2.为下面的文法设计一个预测分析器,给出预测分析表。
bexpr → bexpr or bterm | bterm
bterm → bterm and bfactor | bfactor
bfactor → not bfactor | (bexpr) | true | false
答:
修改文法为:
bexpr → bterm A
A → or bterm A | ε
bterm → bfactor B
B → and bfactor B | ε
bfactor → not bfactor | (bexpr) | true | false
则文法的FIRST和FOLLOW集合如下:
First(bexpr)= { not,) ,true,false }
First(A)= { ε,or }
First(bterm)= { not,) ,true,false }
First(B)= { ε,and }
First(bfactor)= { not,) ,true,false }
Follow(bexpr)= { #,) }
Follow(A)= { #,) }
Follow(bterm)= { #,or,) }
Follow(B)= { #,or ,) }
Follow(bfactor)= { #,or,) ,and }
则文法的预测分析表(LL(1))如下:
| 项目 | and | or | not | ( | ) | true | false | # |
|---|---|---|---|---|---|---|---|---|
| bexpr | → bterm A | → bterm A | → bterm A | → bterm A | ||||
| A | → or bterm A | → ε | → ε | |||||
| bterm | → bfactor B | → bfactor B | → bfactor B | → bfactor B | ||||
| B | → and bfactor B | → ε | → ε | → ε | ||||
| bfactor | → not bfactor | → (bexpr) | → true | → false |
——> 题型三:规范推导,语法树,二义性等
3.考虑上下文无关文法:
S→S S+|S S |a
以及串 aa+a
1)给出这个串的规范推导。
2)给出这个串的语法分析树。
3)这个文法是否为二义性的?证明你的回答。
4)描述这个文法生成的语言。
答:
1)
最左推导:
S→ SS*
→ SS+S*
→ aS+S*
→ aa+S*
→ aa+a*
最右推导:
S→ SS*
→ Sa*
→ SS+a*
→ Sa+a*
→ aa+a*
2)给出这个串的一棵语法分析树。
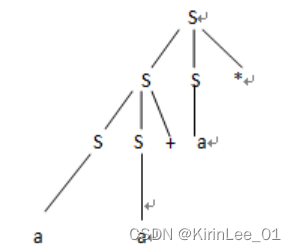
3)这个文法是否为二义性的?证明。
没有二义性 。因为最左推导和最右推导只能画出一颗语法分析树。
4)描述这个文法生成的语言。
只含+或*,操作数均为a,的表达式的后序遍历。
{a,aa+,aa*,aaa+,aaa*,aa+aa*+,aaaa+,...}
——> 题型四:规范推导,语法树,二义性等
4.已知文法G(S):
S—>a|(T)
T—>T,S|S
①给出句子(a,(a,a))的最左推导并画出语法树;
②给出句型(T,a,(T))所有的短语、直接短语、素短语、最左素短语、句柄和活前缀。
答:
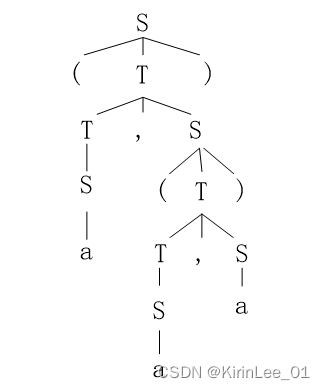
(1)最左推导:
S→(T)
→(T,S)
→(S,S)
→(a,S)
→(a,(T))
→(a,(T,S))
→(a,(S,S))
→(a,(a, S))
→(a,(a,a))
语法树如下:
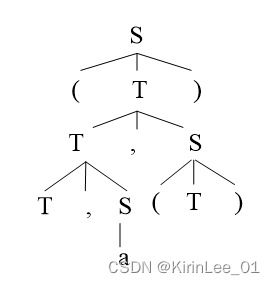
(2)句型(T, a, (T))的短语、直接短语、素短语、最左素短语、句柄、活前缀。
短语:a || T , a || (T) || T , a , (T) || (T , a , (T))
直接短语:a || (T)
素短语:a || (T)
最左素短语:a
句柄:a
活前缀: || ( || (T || (T , || (T , a
语法树如下:
——> 题型五:SLR(0)——自低向上分析法
1.以下文法是SLR文法吗?若是给出分析表,若不是说明理由。
S→ SS+ | SS* | a
答:
文法扩展为:
S→ S’
S’→ SS+
S’→ SS*
S’→ a
写出项目集规范簇,然后画出DFA(略),这是一个SLR文法。
最后写出SLR(0)分析表,如下:
| 状态 | a | * | + | # | S |
|---|---|---|---|---|---|
| 0 | S2 | 1 | |||
| 1 | S2 | acc | 3 | ||
| 2 | r3 | r3 | r3 | r3 | |
| 3 | S4 | S5 | 3 | ||
| 4 | r1 | r1 | r1 | r1 | |
| 5 | r2 | r2 | r2 | r2 |
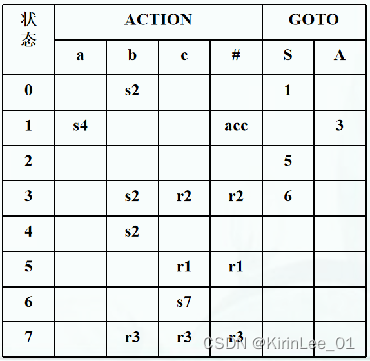
2.构造该文法的SLR(1) 分析表:
G[S]:S→bAS | bA
A→aSc
答:
拓广文法为:
G’[S’]:(0) S’→S
(1) S→bAS
(2) S→bA
(3) A→aSc
FOLLOW(S’) ={#};
FOLLOW(A) ={b};
FOLLOW(S) ={c};
FOLLOW(S) ={c, #};
FOLLOW(A) ={b, c, #}。
项目集规范簇构成的DFA如下:
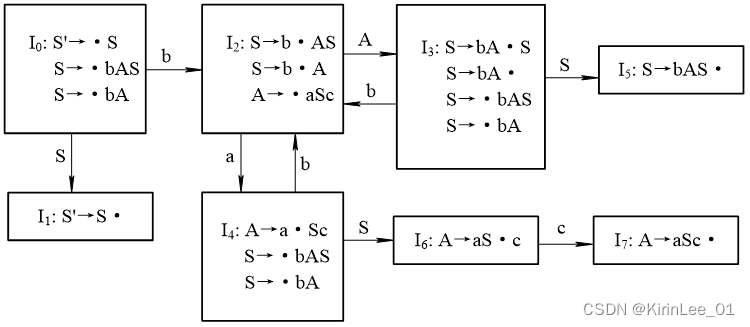
SLR(0)分析表如下:
第四章
——> 题型一:根据语法制导翻译,写出带注释的语法分析树
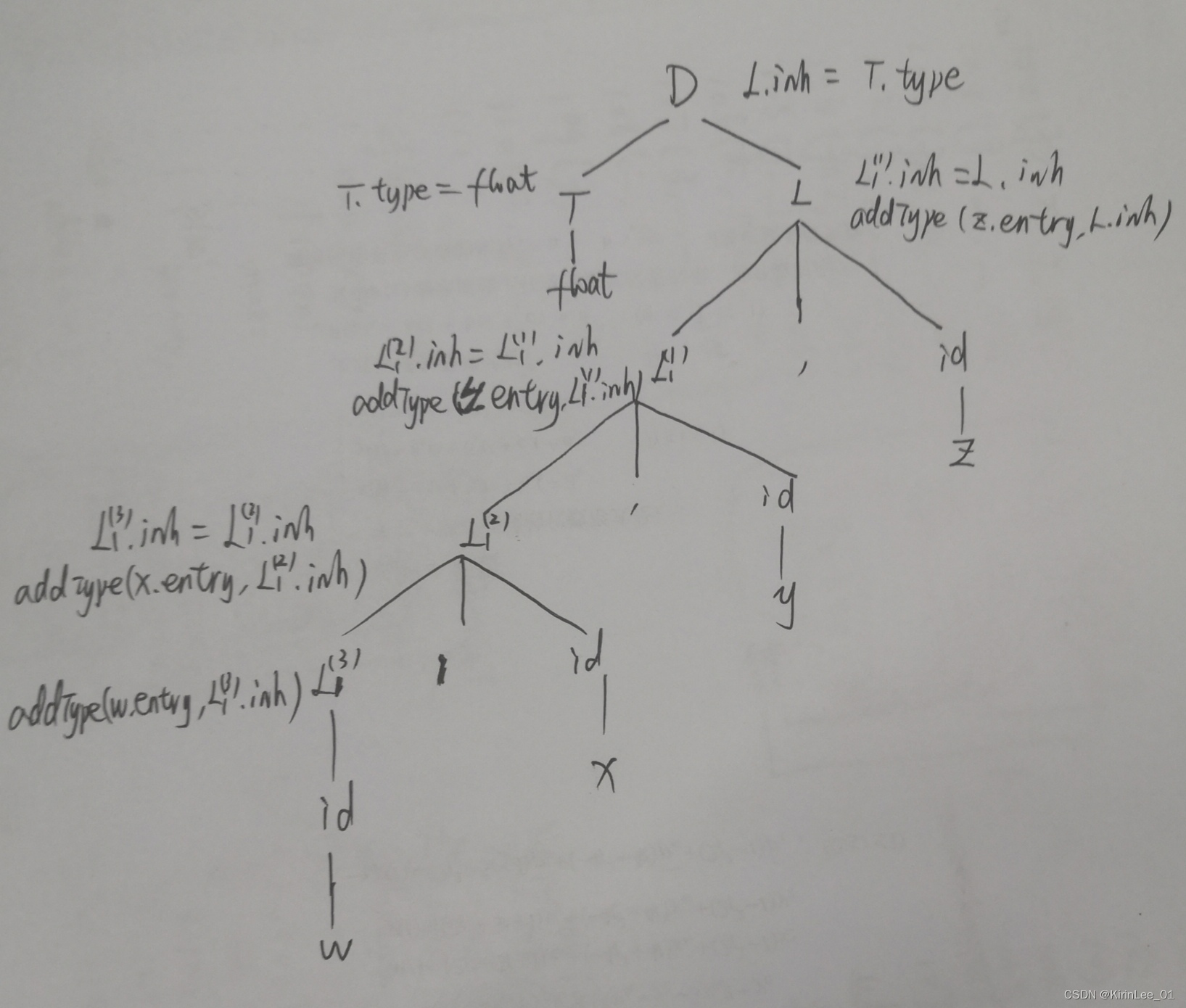
1.对于下图的语法制导定义,给出对应的带注释语法分析树。

(1) int a,b,c
(2) float w, x, y, z
答:带注释的语法分析树如下:
(1) int a,b,c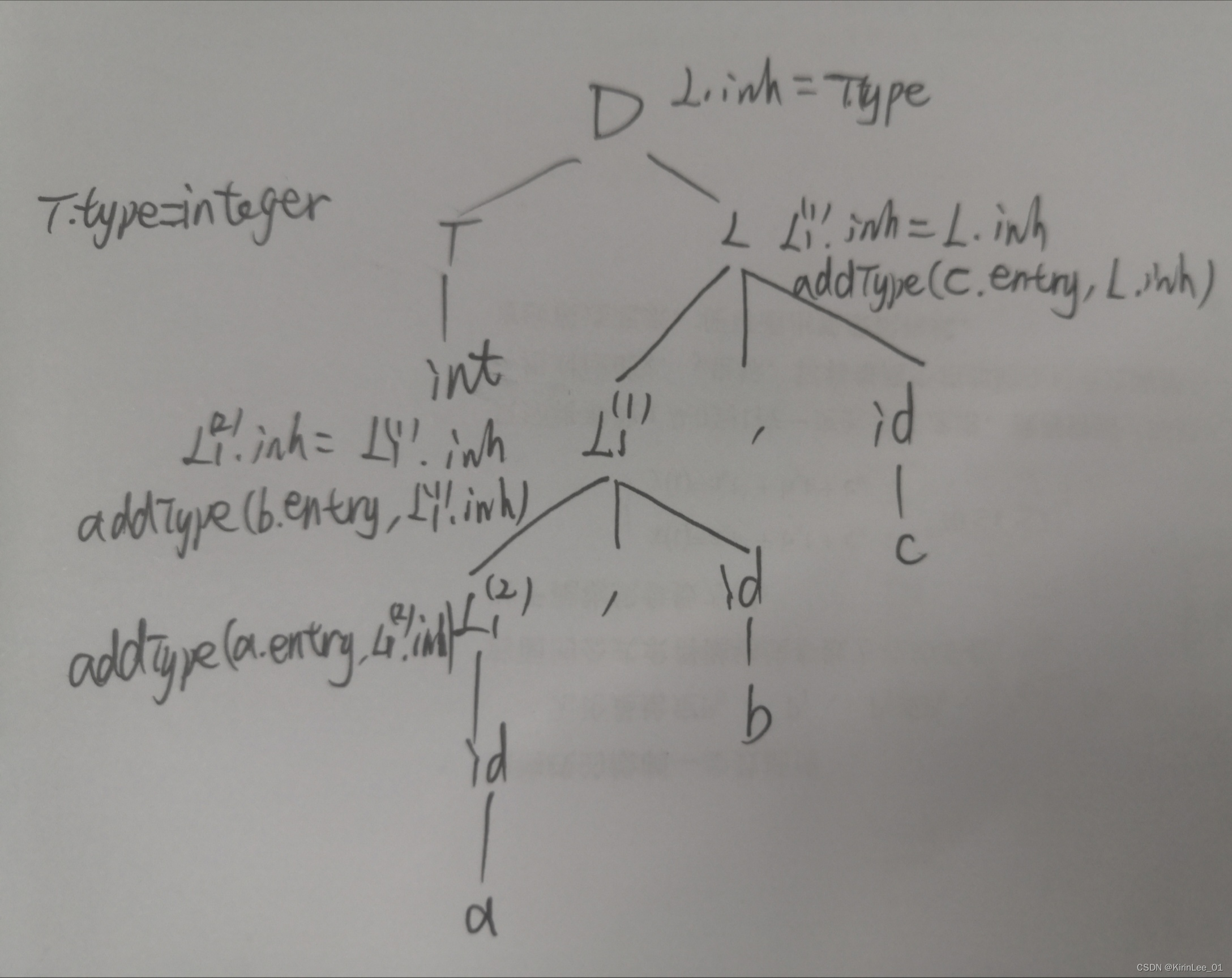
(2)float w, x, y, z
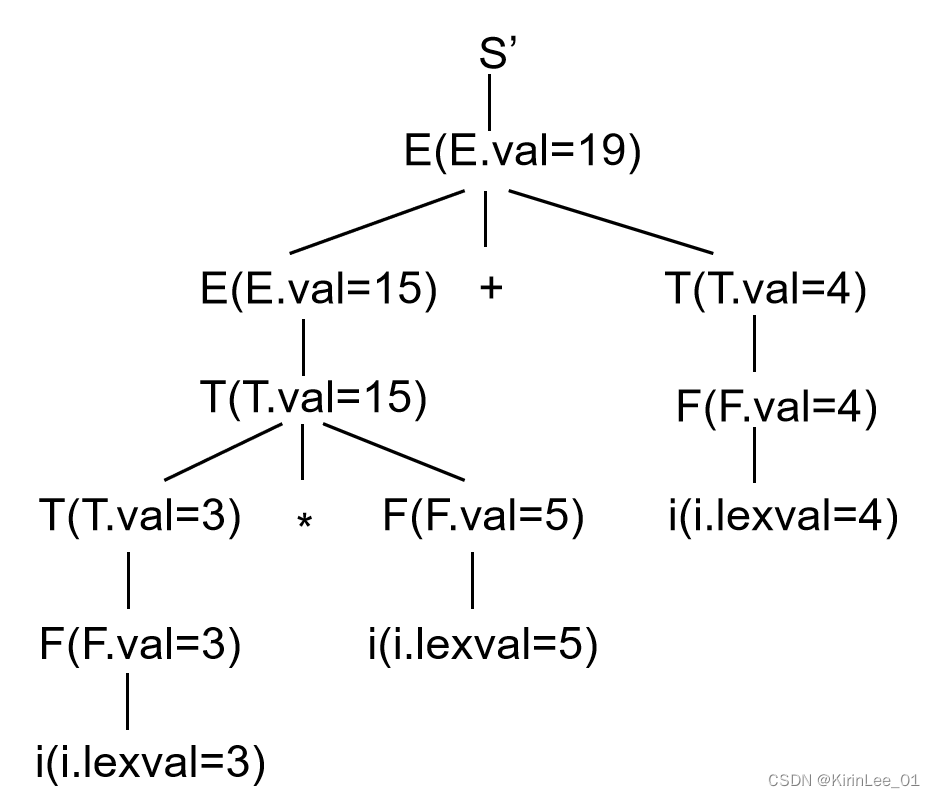
2.输入串 3*5+4# 的带注释语法树,语法制导如下图

答:
带注释的语法分析树如下:
——> 题型二:高级语言翻译为四元式
1.将下面的语句翻译成四元式:if(x>y) if(a∧b) m=m+1; else m=m-1; else x=y;
答:
代码结构图如下:
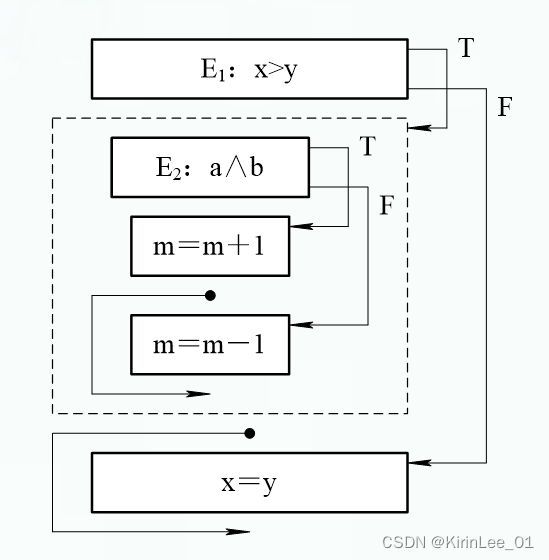
四元式如下:
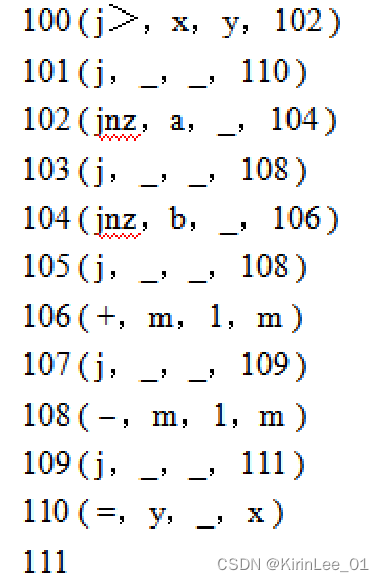
2.将下面的语句翻译成四元式:
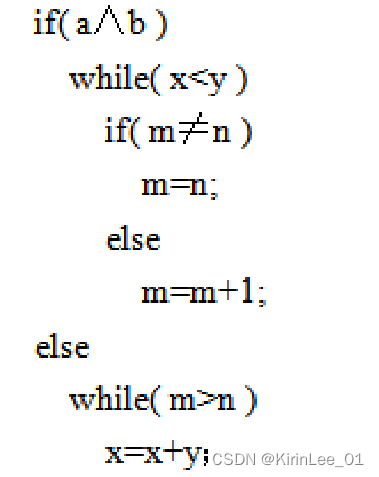
答:
代码结构图如下:
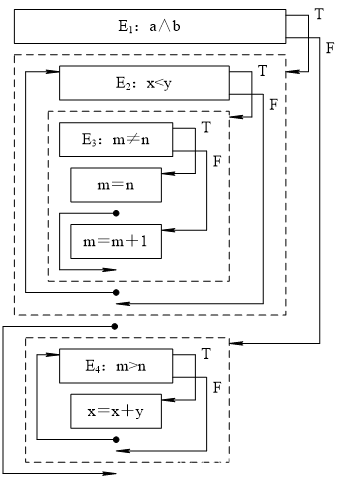
四元式如下:
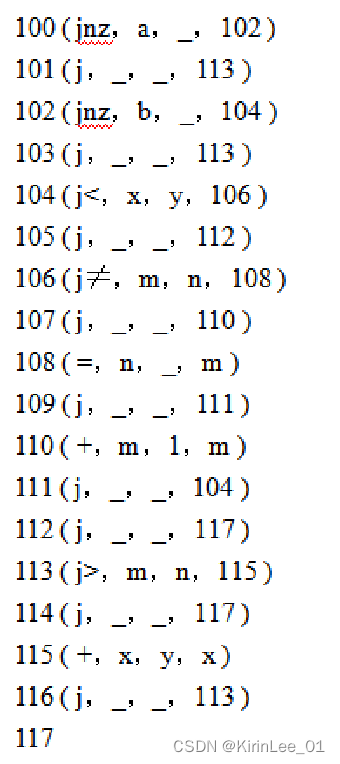
3.将下面的语句翻译成四元式。要求:给出语句的代码结构图及四元式序列,假设该四元式序列从100开始编号。
n=1;
s=1;
for ( i=2; i<=64; i++)
{
n=n*2;
if(a∧b∨c>d))
s=s+n+1;
}
答:
代码结构图如下:

四元式如下:

第五章
——> 题型一:划分基本块,构造流程图
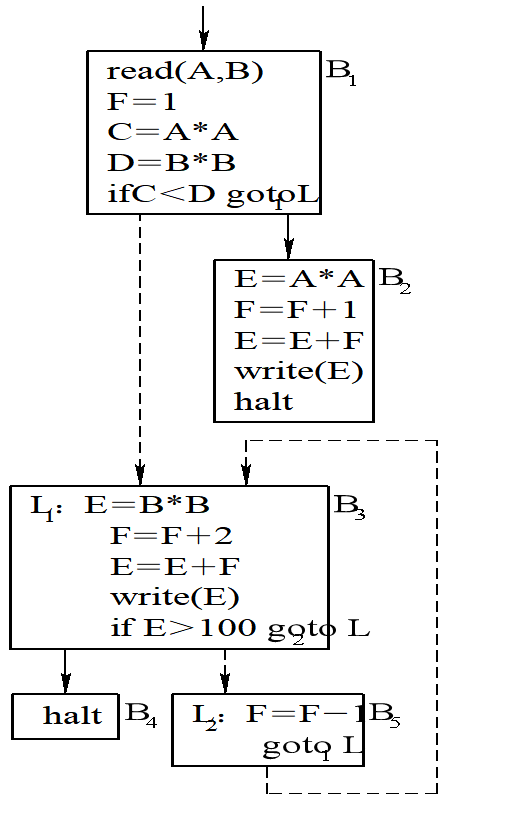
1.将下面程序划分为基本块并作出其程序流图。
read(A,B)
F=1
C=A * A
D=B * B
if C<D goto L1
E=A * A
F=F+1
E=E+F
write(E)
halt
L1: E=B * B
F=F+2
E=E+F
write(E)
if E >100 goto L2
halt
L2: F=F-1
goto L1
答:
划分的基本块如下:
read(A,B)
F=1
C=A * A
D=B * B
if C<D goto L1
——————
E=A * A
F=F+1
E=E+F
write(E)
halt
——————
L1: E=B * B
F=F+2
E=E+F
write(E)
if E >100 goto L2
——————
halt
——————
L2: F=F-1
goto L1
流程图如下:
——> 题型二:利用DAG图优化代码段
2.试构造以下基本块的DAG:
(1) T0=3.14
(2) T1=2* T0
(3) T2=R+r
(4) A=T1* T2
(5) B=A
(6) T3=2* T0
(7) T4=R+r
(8) T5=T3* T4
(9) T6=R−r
(10) B= T5* T6
答:按照算法顺序处理每一四元式后构造出的DAG如图所示,其中每一子图(1)、(2)、…、(10)分别对应四元式(1)~(10)的DAG构造。
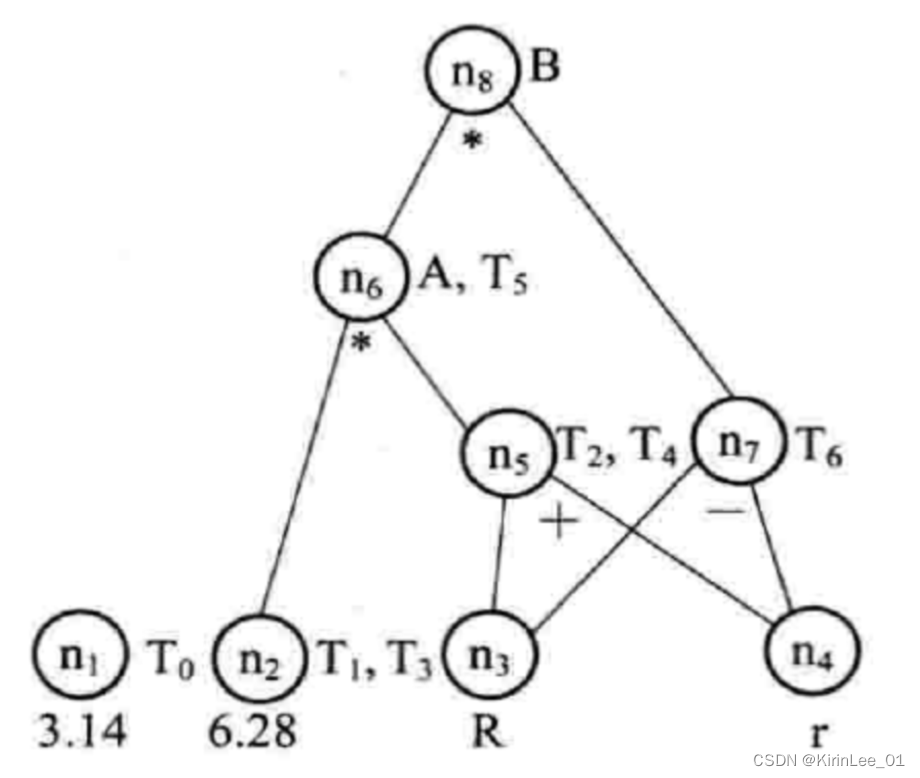
假设图中T0、T1、T2、T3、T4、T5和T6在基本块后都不会被引用,则图中的DAG就可重写为如下的四元式序列:
(1) S1=R+r / * S1、S2为存放中间结果的临时变量 * /
(2) A=6.28* S1
(3) S2=R−r
(4) B=A* S2
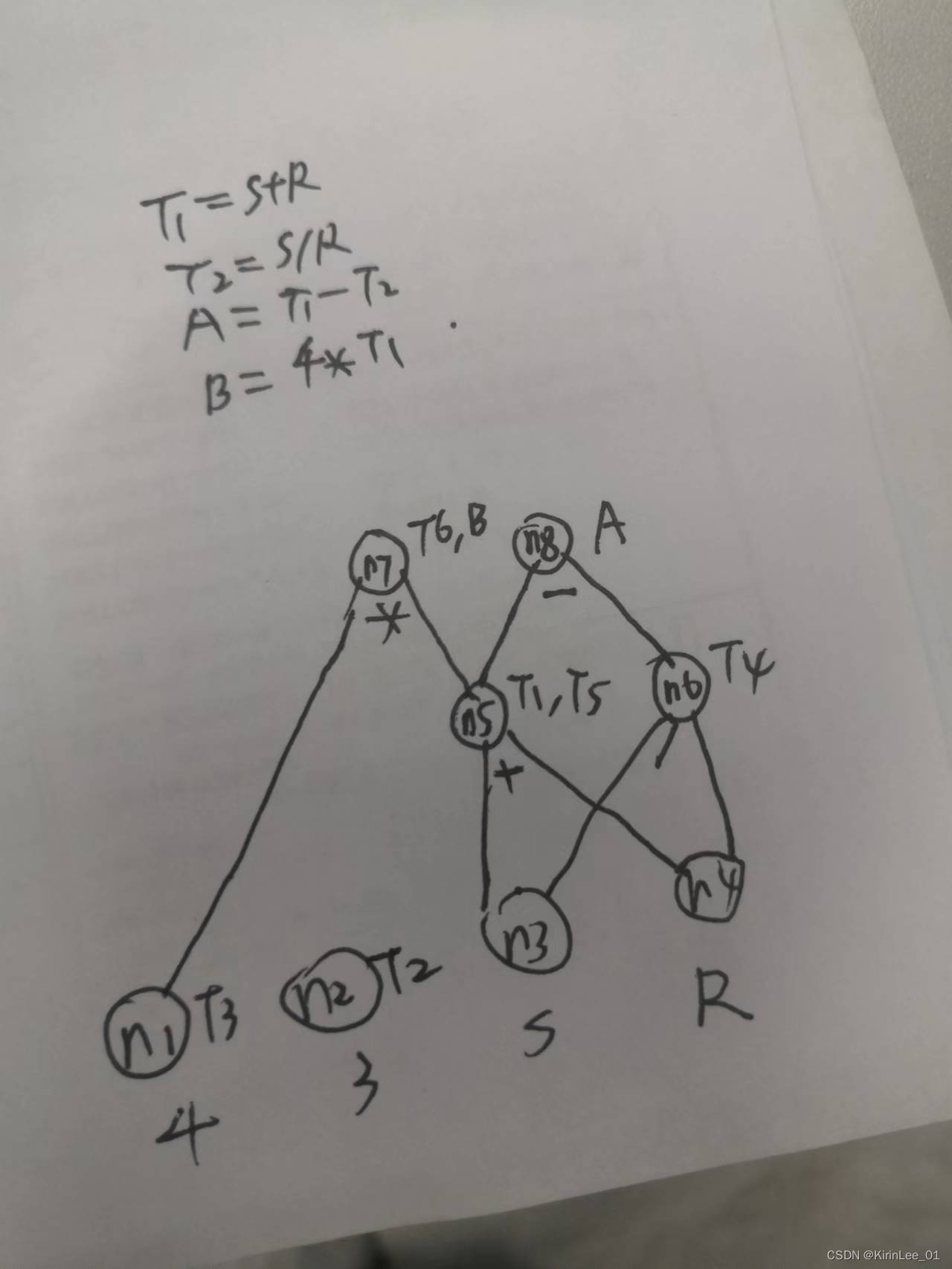
2.设有基本块如下:
T1:=S+R
T2:= 3
T3:= 12/T2
T4:=S/R
A:=T1-T4
T5:=S+R
B:=T5
T6:=T5* T3
B:=T6
(1)画出DAG图;
(2)设A,B是出基本块后的活跃变量,请给出优化后的四元式序列。
答:
















 2969
2969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











