







这章和上一章(属性文法和语法制导翻译)是紧密联系的,共同完成了编译过程的第三步——语义分析与中间代码产生。
开篇先解释两个问题:
1. 什么是语义分析?它和之前几部分有什么不同呢?
2. 什么是中间代码?为什么需要产生中间代码?
问题一:什么是语义分析?它和之前几部分有什么不同呢?
词法分析主要完成的是标识符/算符等等定义是否符合规定。语法分析是看程序的结构是否符合文法的要求,也就是下一部分接这个对不对?语义分析就上升到概念层了,我以C语言举个例子:使用一个变量之前必须对这个变量进行定义,否则就会出现undefine的bug,检查这部分的就是语义分析。再有就是break语句必须要定义在循环体中,如果没有循环而有break,肯定是要报错的呀~还有上下无关文法无法描述整个程序语言就是因为其无法表示语义的相关分析。
问题二:什么是中间代码?为什么需要产生中间代码?
编程时写的叫做高级语言,机器运行的叫做机器语言。中间代码可以理解成一个过渡。其实汇编语言也是一种过渡,但中间代码主要强调的指明过程中数据和地址及相关操作。为什么需要产生中间代码,是因为中间代码有如下几点好处:

看完了前面的内容,希望你对于语义分析和中间代码有一个简单的了解。再继续看下面的内容。先说一下本文叙述的结构吧,大体可以分为四个部分:
1. 中间代码的表达形式(大致3种)
2. 说明语句的翻译
3. 赋值语句的翻译
4. 布尔表达式/控制语句的翻译
一、 中间代码的表达形式
中间代码的表达形式从大的角度上分可分为3种:后缀式、图表示法、三地址代码,下面简单介绍(其实主要用的还是三地址代码,前两种作为扩充知识提一下吧)
后缀式
后缀式也叫逆波兰式,是一种表达式的方法。形式化定义如下:

举个例子:
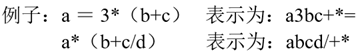
后缀式看上去有点奇怪,反倒是例子中左边的让人更直观理解。其实左边叫做中缀式,还有一种叫做前缀式(也叫做波兰式)。我们平常写的都是中缀式,但计算机识别字符串从左到右或者从右到左,无法完成中缀式的计算规则。所以在计算机里面输入中缀式,一般也会先转化成后缀式。对于后缀式的计算就需要用到数据结构中栈的相关内容啦!
图表示法
这里的图前面介绍过,就是抽象语法树。不过新增的一部分是DAG图。啥是DAG图呢?其实就是将抽象语法树中公共因子凝聚成一个节点。举个例子就过:
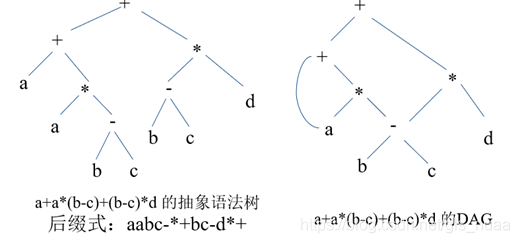
三地址代码
三地址代码是由两个运算操作数地址,一个结果操作数地址组成的。一般形式是z = x op y(op代表运算符,其实和高级语言还是挺像的)。对于三地址代码,有如下这几种类型:

三地址代码还有三种表达形式:四元式、三元式、间接三元式。因为后续内容只涉及到四元式,老师课程上也只讲了这一种。我就只介绍这一种了,剩下的如果感兴趣可以自己网上搜一搜:
四元式包含的四部分是两个源操作数,一个目的操作数再加上一个操作符,对于运算的转化形式如下:
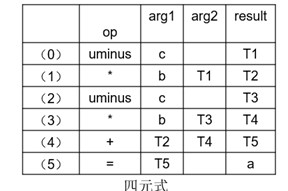
四元式有一个明显的缺点:会引入大量的临时变量(像上表中的T1,T2,T3,T4,T5)但这个问题在后续的优化过程会得到解决。
二、 说明语句的翻译
首先,什么是说明语句呢?就有点儿像变量定义的语句。那这步主要干嘛呢?提一个之前的概念:符号表(我都快忘了~)在词法分析的过程中,当我们识别到一个标识符的时候,会放在符号表中。除了标识符的名字外还有一些其他的属性,比如类型,在内存中存储位置等等。
先介绍两个概念:

作用域
每一个函数调用都会有属于它本身的作用域,每一个函数都在维护一个符号表。它们就是当前标识符的有效范围,当两个函数进行嵌套并且标识符名相同时,内层作用域属于里面定义的标识符。(这个很容易理解,就是C语言中的变量覆盖)
符号表:
制作符号表用到了下面几个函数:

如果把符号表和翻译模式加在一起,举个例子如下所示:

关于符号表有些信息:

举个例子,看看函数过程中的符号表是什么样子的:
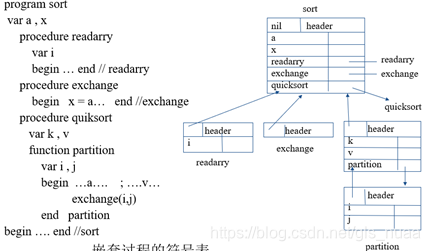
从上面可以看出,符号表表头中维护的就是各个指针。能够在指定的位置进行跳转进行操作。
三、 赋值语句的翻译
赋值语句就不用多说了,在大多数语句中赋值之前需要先进行定义。所以在赋值时查询符号表是否进行定义就是翻译的操作之一。在翻译过程中会有lookup(id.name)这样的函数完成检验操作。
举个赋值语句加翻译模式的例子:

对于赋值语句和说明语句内容比较少,课程主要的内容在后面两个,下面继续开始!
四、布尔表达式的翻译/控制流语句的翻译
布尔表达式:用布尔运算符号(and or not)作用到布尔变量或关系表达式上而组成
布尔表达式一方面可以用来进行逻辑计算,另一方面可用作判断条件。
当进行布尔运算时,存在一种优化的思想。大体是这样的对于or来说,如果你已知第一个操作数是正确的,那第二个操作数就不重要了,结果一定是true。相反,若第一个错误,则要看看第二个语句的情况。True和false的情况语句不会完全相邻,就需要一些跳转,自然就要生成一些标号。下面我列举下布尔表达式进行计算时的属性文法:

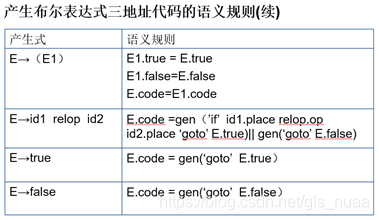
那如果是控制流语句呢?比如if,if-else,while语句中的判断条件。那对布尔表达式的翻译都需要干些啥呢?很明显就是要知道在各种情况下指令之间是怎么跳转的。对于布尔表达式的翻译内容主要可以分为两种情况:属性文法和翻译模式。
属性文法就是先定义语法动作再定义语法规则。写一个程序的属性文法是有套路的。Let me show you! 主要的方法是图解法,因为常用在循环中,我就以循环举例。对于单步的条件判断,可同理得到。
有产生式S->for(E1;E2;E3)S1,写其属性文法
先看看结果,如图所示:

那为啥会有这个结果呢?首先我们需要先画一个图从上到下按照产生式的顺序为E1,E2,E3,S1,四段代表代码段。就像这样:
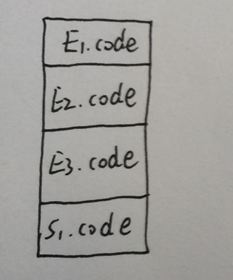
先来分析一下这个循环的执行过程:初始化E1,接着对E2进行判断,满足E2跳转S1,不满足E2跳出循环(即S),S1执行过后(或者S1中的跳转)跳转E3执行自增,E3执行跳转E2再次判断,就这样循环,循环…
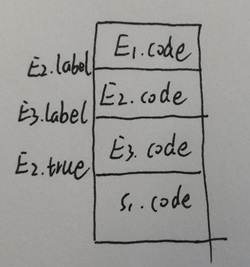
从上面一个简单的过程中可以了解到,有跳转的过程,其中包含if的跳转也包含直接的跳转。但无论哪种,都要有一个跳转的目标,也就是说要为每一个目的地建立一个标记。有一个通用的套路:为if语句建立E.true和E.false两个属性。为每一个终点建立一个标号。结合上面的例题,E2跳转S1——E2是if语句,满足条件跳转,建立一个标号,但因为也是E2.true, 之前建立过了,不需要再建了。S1跳转E3——无条件跳转,生成一个E3.label。E3跳转E2——无条件跳转,生成一个E2.label。把他们标在上面的图里就是这样:
我们再把goto语句写到代码段中,就像这样:
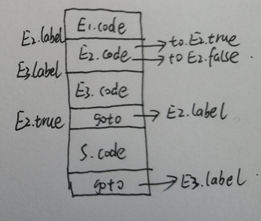
以上过程做好了前期准备,可以开始从上到下写答案了:遵循三个步骤:1.创建标号。2.连链。3.连接代码
1. 创建标号:上面过程中我们创建了3个标号,就把它们的名字写到左边,右边newlabel。例如E2.true = newlabel。
2. 连链主要是进行属性间的串联,对于E2如果不满足就要跳出去到S.next。那么就是E2.false = S.next。E3.label = S1.next(注意对于E来说只有true和false两个属性,不要再想E.next了哈!)
3. 连接代码的过程就比较直观了,连接使用||(双竖线),按照图来,碰到代码块就写上xx.code。碰到标号就gen(‘xxx’,’:’),碰到goto就gen(‘goto’, ‘xxx’)。里面的xxx就是标号吗比如E2.true,E3.label这种
经过以上的过程,相信你已经会写属性文法了。那翻译模式到底怎么写呢?二者有什么不同吗?且听我慢慢道来!
还记得翻译模式的主要工作吗?在产生式中插入动作,完成属性的计算。在前面介绍过“遍”的概念,我们追求的应该是一遍完成所有功能。但在控制流语句中,涉及到语句间的跳转。如果在扫描时,还不知道具体的跳转位置怎么办呢?为了完美的完成这个任务,就需要一项技术——回填。
回填的定义如下图:

下面列举一个回填与布尔表达式判断的例子:
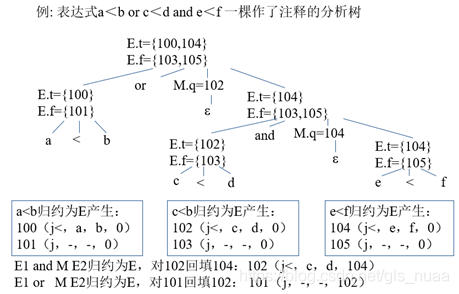
例子中包含三个布尔表达式,对于布尔表达式实际隐含if的跳转语句。同样用两个综合属性E.t和E.f去链接条件表达式为“真”的所有跳转语句和为“假”所有跳转语句。但在从左往右的执行过程中,对于or操作符来说,前面的false会跳转到后面的起始位置。但目前还不知道后面的起始位置在哪里,但我们cd和ef规约之后就可以知道这个起始位置,到了那个时候再通过链表回填即可。
同样再对产生式S->for(E1;E2;E3)S1,写其翻译模式
结果直接贴图了:

我们来分析一下这个结果是怎么来的,这就还需要用到上面那个图:
从图中可以看出有跳转,有标号。跳转的目的地一般是标号,在E2,E3,S1之前都有我们新建立的标号。按照之前翻译模式的构造方法,以M,N构造标号。即写出M->ε{M.quad=nextquad}这样的语义动作。再看下goto语句,总共有三处跳转,其中一个是布尔跳转,另外两个是goto跳转。前文提到跳转需要回填技术。在进行回填时,以M2.next去回填s1.nextlist(goto跳转)。以N.next去回填E2.truelist(if跳转),对于E2.falselist没有明确的回填目标。但已知触发E2.falselist会跳出循环,执行S后的语句,即S.nextlist。所以将S.nextlist与E2.falselist进行绑定。出现关于S.nextlist的赋值语句。下面还剩下一个goto语句,即E3后面的goto语句,目标地址E2(标号为M1)。对于goto语句总会有nextlist这个属性,从表达式和图中的对应位置来看,goto语句对应于N标记符号。说明它不仅承担标记的作用,还要完成跳转。所以把nextlist属性放到N上。按照回填的思路,用M1去回填N.nextlist。当写N的产生式时,一方面要提供标号即N.quad=nextquad,也要指定跳转,N.nextlist相当于我们自己加入的所以需要创建一个链表,即makelist。下面是跳转指令j,目标地址不确定。(可能这里会有人有疑惑,我们都知道N跳转的地址是M1,后面马上就要回填,这里怎么还能不知道跳到哪里呢?原因是这样的语句从左到右执行,回填语句发生在末尾。对于N来说,是一个独立的产生式,所有的语义动作都发生在N完全定义后。N只知道它前面的一些信息,而不知道后面的语义动作是如何规范它的。这也是我们留存一个链表的原因)。别忘记S1之后也有goto语句,emit产生一句即可。按照翻译模式的顺序,先emit动作再回填再连链,就完成了这个循环体的翻译模式书写。
通过以上的举例,应该可以明白属性文法和翻译模式怎么写了吧,这就是语义分析的整个过程。
存在这样一种情况,函数调用了另一个函数,或者调用结束后需要返回,那需要做些什么呢?


对于第七章语义分析和中间代码产生写的时间非常长,不知从何下笔。究其原因,是对于属性文法和翻译模式的理解不到位(哦,第六章白写了!)同时对于布尔表达式的理解也有问题。
现在回过头来看属性文法和翻译模式有了不一样的感觉。两者都是语义分析的方式,旨在赋予符号意义的同时分析意义是否符合我们的要求。翻译模式作为特定的一种属性文法,其表现形式有很多,诸如三地址代码形式、抽象语法树形式。以自下而上的规约过程为基础。回填技术的添加是为了满足一遍翻译的需求。
惭愧的是,在写的时候,脑中大多是一些解题方法,而对于执行过程并没有一个想象的动态图。看来是理解不够,后续仍要继续加强完善!
感谢编译原理课程谢老师对本文的认真修改,由于作者水平有限,如有错误之处请在下方评论区指正,谢谢!















 2339
2339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









