






线性回归与softmax回归
线性回归

线性模型可以看做是单层神经网络

损失函数
损失函数能量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中最常用的损失函数是平方误差函数。

训练数据
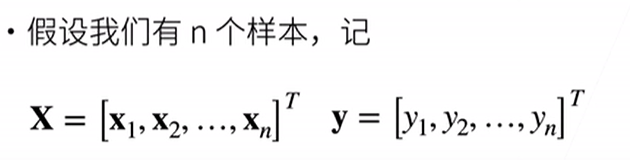
计算在训练集 n 个样本上的损失均值(也等价于求和)
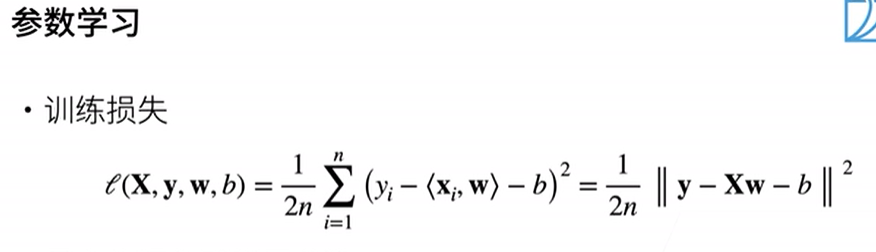
寻找一组参数(w*, b* )最小化在所有训练样本上的总损失


基础优化方法


注:选择学习率不能太小(昂贵)也不能太大(震荡,没有真正下降)。

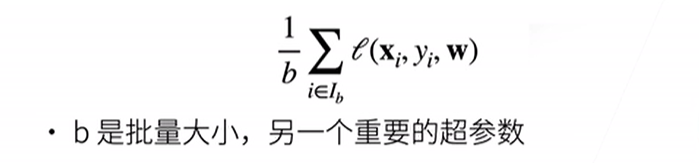
注:选择批量大小不能太小(不适合并行来最大利用计算资源),也不能太大(内存消耗增加、浪费计算)。

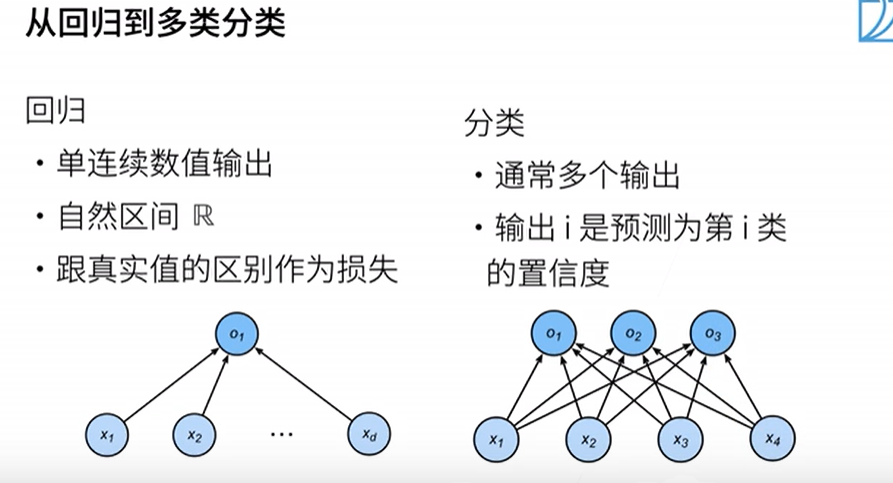
Softmax回归
回归估计一个连续值,分类预测一个离散分类。
均方损失:

无校验比例:

关于一位有效编码:若有A、B和C三类,标号则是长度为3的向量,那么可以分别表示为001、010和100。
校验比例:

若X是矩阵,则softmax定义为:
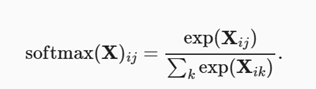



损失函数
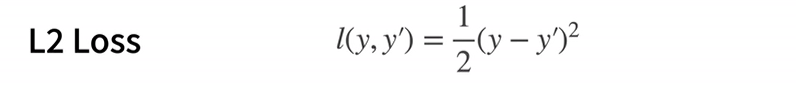
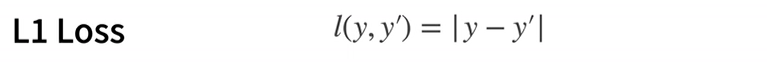
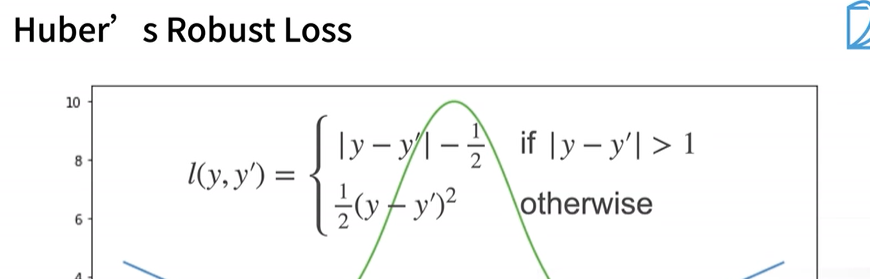
softmax代码实现
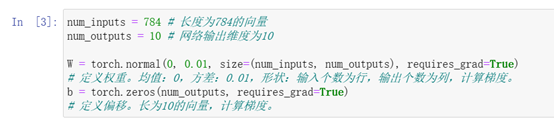
1、初始化参数模型
 2、定义softmax操作
2、定义softmax操作

注:由于使用keepdim=True,将产生形状(1, 3)的二维张量

注:运算使用广播机制
3、定义模型

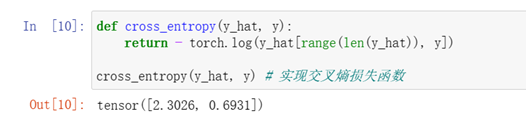
4、定义损失函数

实现交叉熵损失函数
5、分类准确率

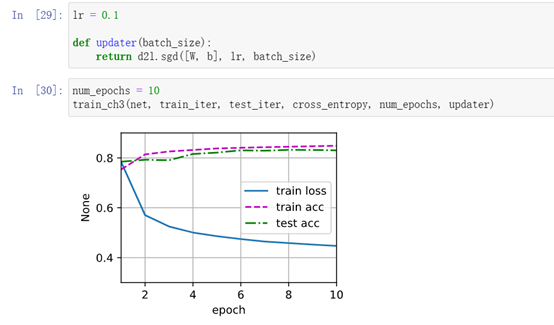
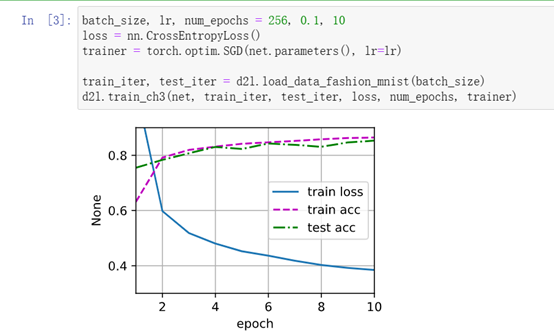
6、训练


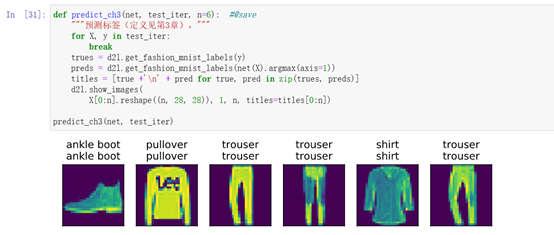
7、预测
简洁实现

感知机
感知机

二分类:-1或1
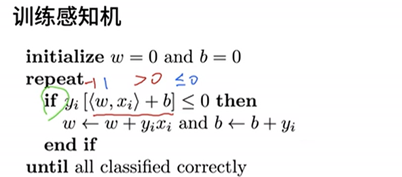


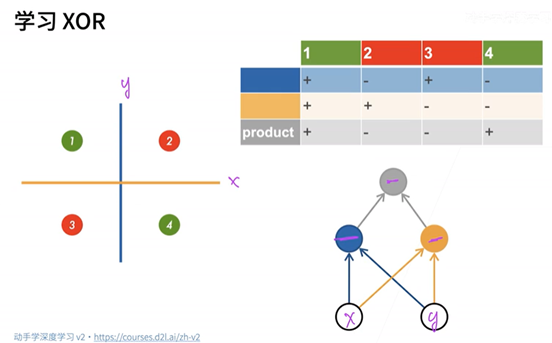
存在的问题:感知机不能拟合XOR问题,只能产生线性分割面。

多层感知机

注:激活函数一定是非线性函数,否则等价于单层感知机。
激活函数

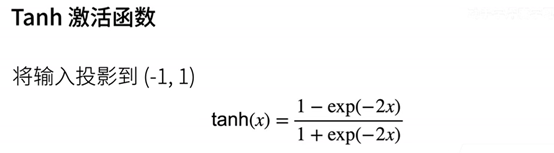
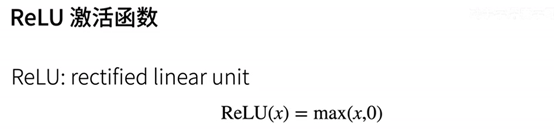
注:ReLU激活函数最为常用。
多类分类增加隐藏层,使用softmax实现。

多隐藏层:最后一层无需激活函数,激活函数目的是防止层数的塌陷。

超参数:隐藏层数、每层隐藏层的大小。

代码实现
实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元

实现ReLU激活函数

实现模型

训练
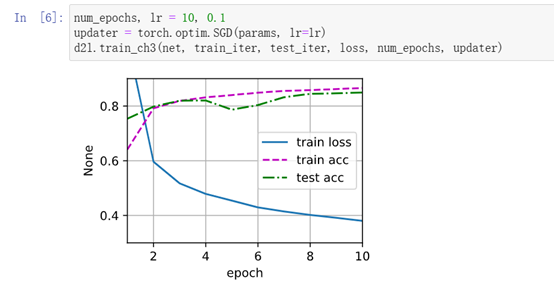
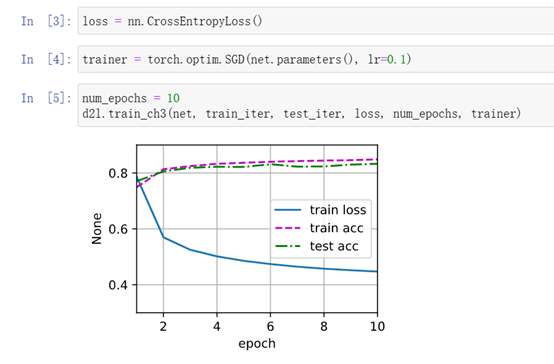
与上文对比,多层感知机损失有所降低,精度变化不大。
简洁实现

区别:增加ReLU激活函数
训练过程
问题:怎么计算多层感知机层数?图示箭头的意义?
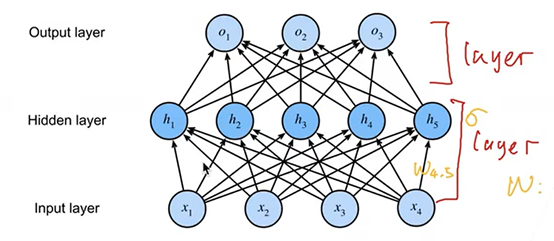
答:图中多层感知机共两层,每个箭头代表一个权重。
模型选择、欠拟合和过拟合
模型选择
训练误差和泛化误差
训练误差:模型在训练数据上的误差
泛化误差:模型在新数据上的误差
验证数据集和测试数据集
验证数据集:用来评估模型好坏的数据集
测试数据集:只用一次的数据集
K-则交叉验证
使用场景:数据量不够大时
算法:①将训练数据分割成K块(K常取5或10)
②For i=1,…,K
使用第i块作为验证数据集,其余作为训练数据集
③报告K个验证集误差的均值
欠拟合与过拟合

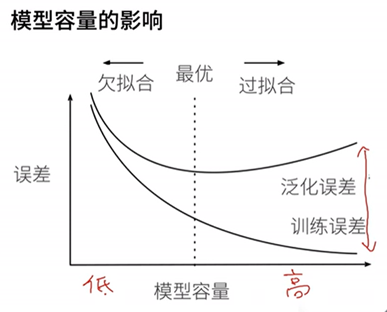
对于中等数据集,泛化误差与训练误差的差值可以衡量过拟合欠拟合程度,目的是两者差值尽可能小。
代码实现


实现一个函数来评估模型在给定数据集上的损失

定义训练函数
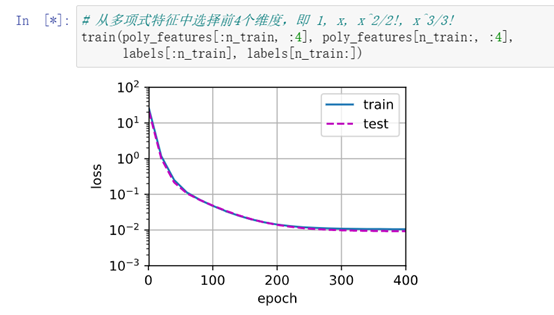
注:模型复杂度较高,但数据不全或数据量过小时,易欠拟合;数据量很大导致过度学习误差上升时,为过拟合。
权重衰减、DropOut
权重衰退


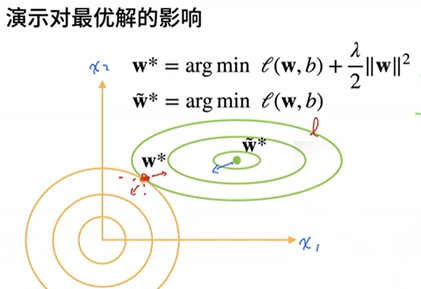


代码实现

 初始化参数模型
初始化参数模型

定义 L2范数惩罚(核心)

训练

忽略正则化直接训练 ,明显过拟合
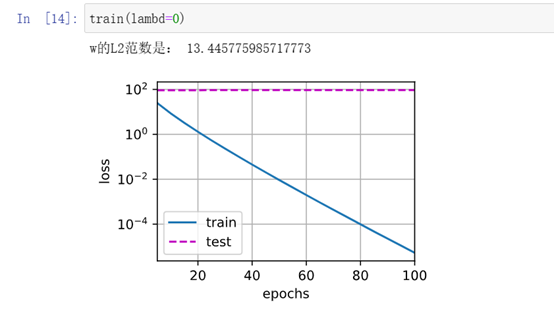 使用权重衰减,有好转训练误差增大,但测试误差减小
使用权重衰减,有好转训练误差增大,但测试误差减小
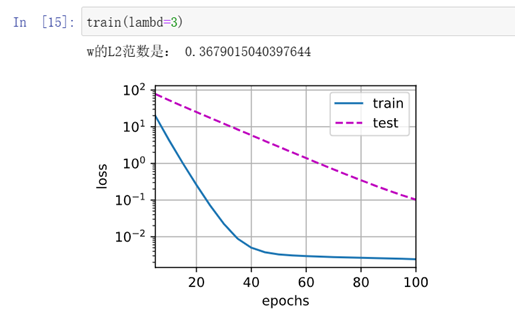 简洁实现
简洁实现
区别:‘weight_decay’: wd

对比:若修改L2范数为:

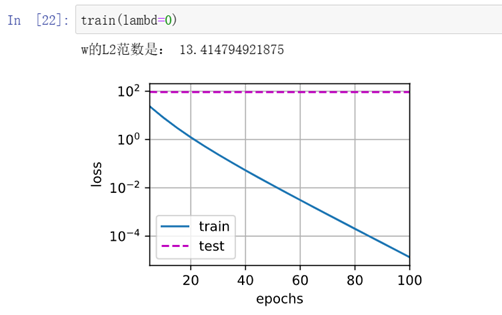
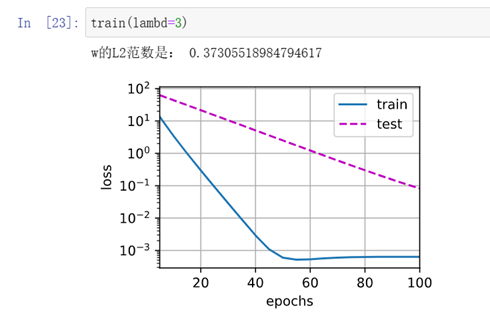
对比实验结果,训练数据集损失曲线平滑度降低。
DropOut
动机:一个好的模型需要对输入数据的扰动鲁棒。丢弃法即在层中之间加入噪音。

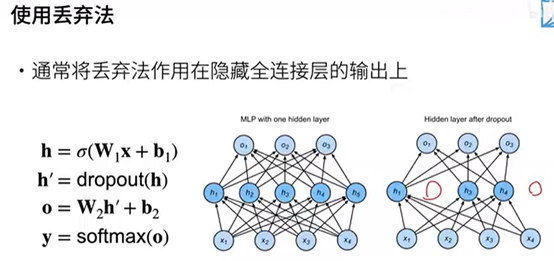


代码实现
实现 dropout_layer 函数,该函数以dropout的概率丢弃张量输入X中的元素

测试dropout_layer函数

定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
定义模型
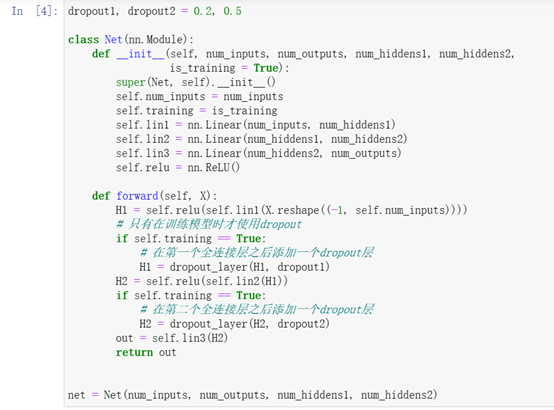
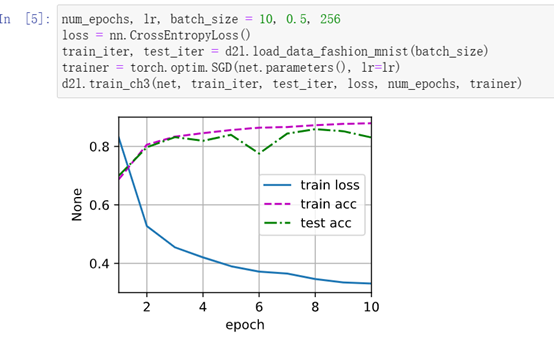
训练和测试
(双隐藏层,大小为256,训练模型相对数据集复杂度较大,dropout起较大作用)
对比:dropout=0
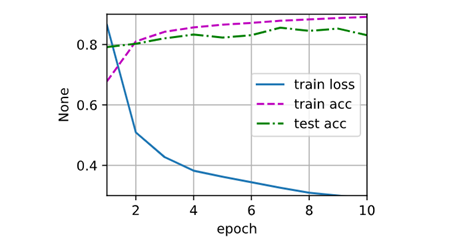
简洁实现

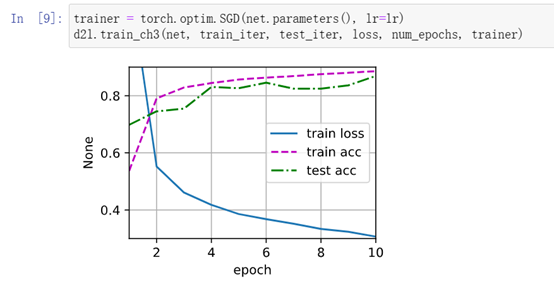
数值稳定性、模型初始化和激活函数
数值稳定性

数值稳定性常见的两个问题:梯度爆炸和梯度消失。



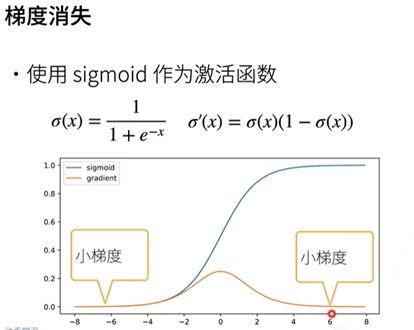
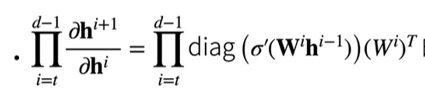







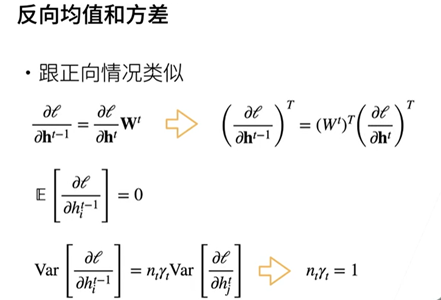




问题与感想
问题
最后一节与概率论有关的计算推理比较吃力,需要多回顾理解;实验上还不够深入,目前做的复现以及简单对比还远不够。
感想
本周学习内容,对多层感知机及其常用策略有了了解,对之后学习更复杂的网络结构打下理论基础。当然,借用李沐老师书上的一句话“纸上得来终觉浅,绝知此事要躬行”,之后应该更合理地规划学习节奏,多动手多实践。














 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









