








本文字数:10477;估计阅读时间:27 分钟
审校:大平

Meetup活动
ClickHouse Shenzhen User Group第1届 Meetup 火热报名中,详见文末海报!
ClickHouse不仅支持标准聚合函数,还支持许多更高级的函数,以涵盖大多数分析用例。除了聚合函数外,ClickHouse还提供了聚合组合器,这是查询功能的强大扩展,可以满足大量需求。
组合器允许扩展和混合聚合,以解决各种数据结构的需求。这种能力使我们能够调整查询而不是表,甚至回答最复杂的问题。
在这篇博文中,我们将探讨聚合组合器,如何用它简化查询,同时避免对数据进行结构性更改的需要。
如何使用组合器
要使用组合器,我们必须做两件事。首先,选择考虑使用的聚合函数;假设我们想使用sum()函数。其次,选择案例所需的组合器;假设需要一个If组合器。要在查询中使用 if ,我们就要将将组合器添加到函数名中:
SELECT sumIf(...)更有用的特性是,我们甚至可以在一个函数中:组合任意数量的组合器:
SELECT sumArrayIf(...)在这里,我们将sum()函数与Array和If组合器组合在一起:
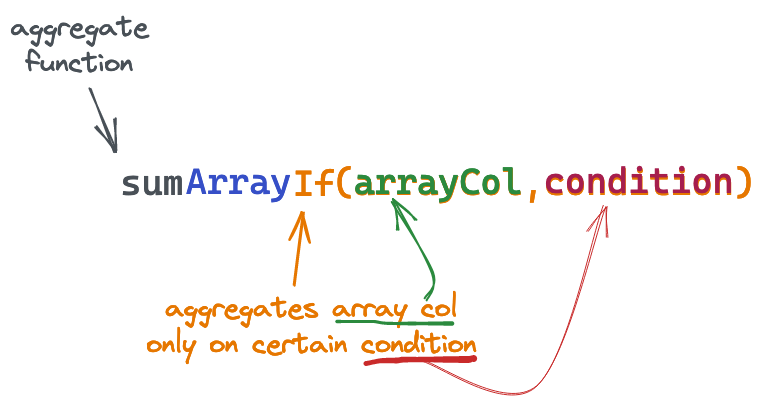
这个特定的例子说明:允许有条件地对数组列的内容进行求和。
让我们探讨一些可以使用组合器的实际案例。
在聚合中的增加条件
我们有时需要根据特定条件对数据进行聚合。我们就可以使用If组合器,并将条件指定为组合函数的最后一个参数,而不是使用WHERE子句:
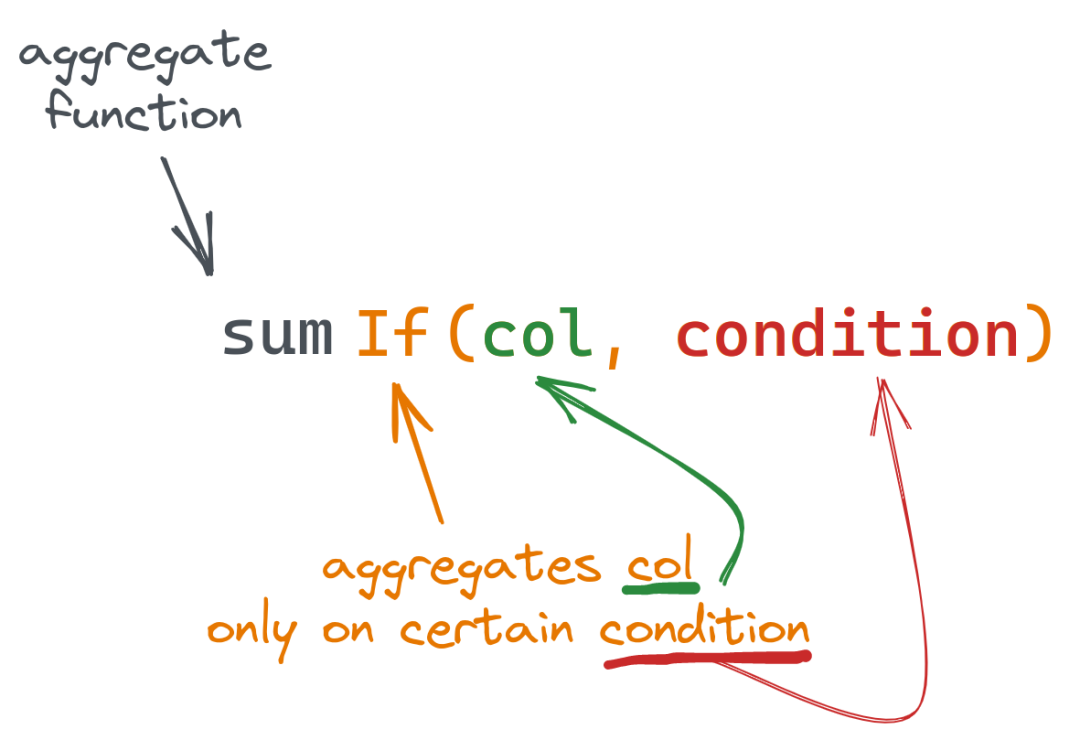
假设我们有一个用户付款表,结构如下(使用示例数据填充):
CREATE TABLE payments
(
`total_amount` Float,
`status` ENUM('declined', 'confirmed'),
`create_time` DateTime,
`confirm_time` DateTime
)
ENGINE = MergeTree
ORDER BY (status, create_time)假设我们想获得总金额,但仅当付款被确认时,即 status="confirmed":
SELECT sumIf(total_amount, status = 'confirmed') FROM payments
┌─sumIf(total_amount, equals(status, 'declined'))─┐
│ 10780.18000793457 │
└─────────────────────────────────────────────────┘我们可以使用与WHERE子句相同的语法来使用条件。让我们获取确认付款的总金额,但当confirm_time比create_time晚1分钟时:
SELECT sumIf(total_amount, (status = 'confirmed') AND (confirm_time > (create_time + toIntervalMinute(1)))) AS confirmed_and_checked
FROM payments
┌─confirmed_and_checked─┐
│ 11195.98991394043 │
└───────────────────────┘使用条件If相对于标准WHERE子句的主要优势在于能够为不同的子句计算多个总和。我们还可以在组合函数中使用任何可用的聚合函数,如countIf()、avgIf()或quantileIf() - 任何函数。结合这些功能,我们可以在单个请求中根据多个条件和函数进行聚合:
SELECT
countIf((status = 'confirmed') AND (confirm_time > (create_time + toIntervalMinute(1)))) AS num_confirmed_checked,
sumIf(total_amount, (status = 'confirmed') AND (confirm_time > (create_time + toIntervalMinute(1)))) AS confirmed_checked_amount,
countIf(status = 'declined') AS num_declined,
sumIf(total_amount, status = 'declined') AS dec_amount,
avgIf(total_amount, status = 'declined') AS dec_average
FROM payments
┌─num_confirmed_checked─┬─confirmed_checked_amount─┬─num_declined─┬────────dec_amount─┬───────dec_average─┐
│ 39 │ 11195.98991394043 │ 50 │ 10780.18000793457 │ 215.6036001586914 │
└───────────────────────┴──────────────────────────┴──────────────┴───────────────────┴───────────────────┘仅对唯一条目进行聚合
计算唯一条目的数量是一种常见情况。ClickHouse有几种方法可以使用COUNT(DISTINCT col)(与uniqExact相同),或当估计(但更快)的值足够时,使用uniq()来执行此操作。但是,我们可能希望在不同的聚合函数中使用在列中的唯一值。为此,可以使用Distinct组合器:

一旦将Distinct添加到聚合函数中,它将忽略重复的值:
SELECT
countDistinct(toHour(create_time)) AS hours,
avgDistinct(toHour(create_time)) AS avg_hour,
avg(toHour(create_time)) AS avg_hour_all
FROM payments
┌─hours─┬─avg_hour─┬─avg_hour_all─┐
│ 2 │ 13.5 │ 13.74 │
└───────┴──────────┴──────────────┘在这里,avg_hour 将基于仅两个唯一值计算,而avg_hour_all将基于表中的所有100条记录计算。
结合 Distinct 和 If
由于组合器可以互相结合,可以使用前面的组合器和avgDistinctIf函数来处理更高级的逻辑:
SELECT avgDistinctIf(toHour(create_time), total_amount > 400) AS avg_hour
FROM payments
┌─avg_hour─┐
│ 13 │
└──────────┘这将计算总金额值大于400的记录的不同小时的平均值。
将数据分组后进行聚合
与最小/最大分析不同,我们可能希望在聚合之前将数据分成组,并针对每个组分别计算数据。这可以通过Resample组合器来解决。
它接受一个列、范围(开始/结束)和您希望使用的分割数据的步长。然后,它为每个组返回一个聚合值:
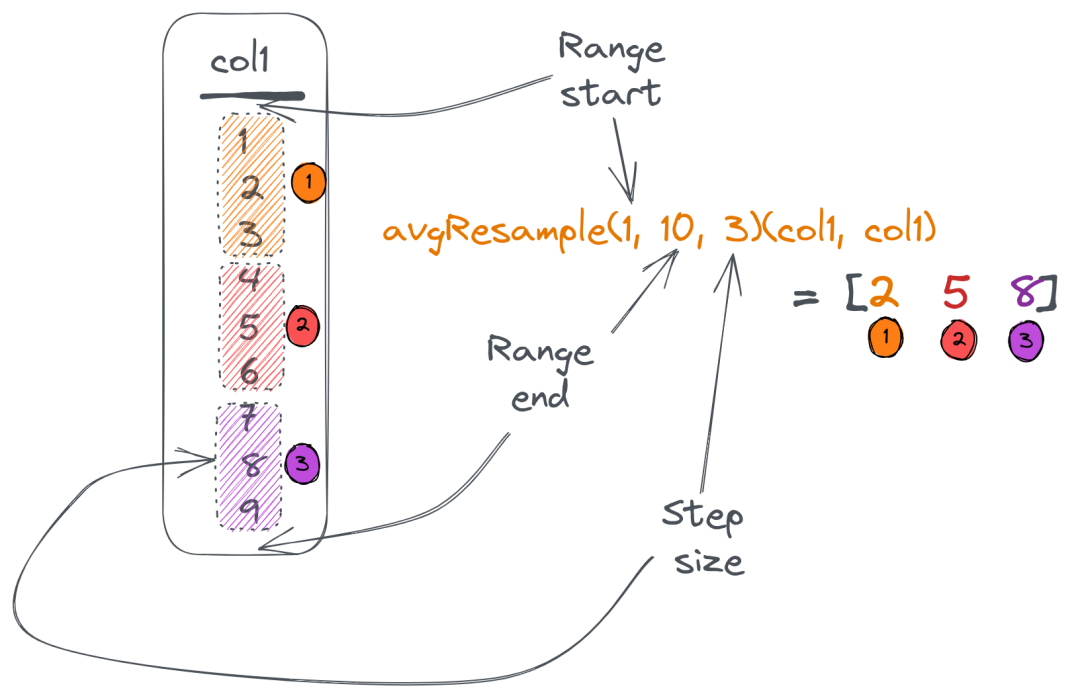
假设我们想根据total_amount从0(最小值)到500(最大值)以100的步长拆分我们的payments表数据。然后,我们想知道每个组中有多少条目以各组的平均总和:
SELECT
countResample(0, 500, 100)(toInt16(total_amount)) AS group_entries,
avgResample(0, 500, 100)(total_amount, toInt16(total_amount)) AS group_totals
FROM payments
FORMAT Vertical
Row 1:
──────
group_entries: [21,20,24,31,4]
group_totals: [50.21238123802912,157.32600135803222,246.1433334350586,356.2583834740423,415.2425003051758]在这里,countResample()函数计算每个组中的条目数,avgResample()函数计算每个组的total_amount的平均值。Resample组合器接受要基于的列名作为组合函数的最后一个参数。
请注意,countResample()函数只有一个参数(因为count()根本不需要参数),avgResample()有两个参数(第一个是要计算平均值的列)。最后,由于Resample组合器需要,我们必须使用toInt16将total_amount转换为整数。
为了在表格布局中获取Resample()组合器的输出,我们可以使用arrayZip()和arrayJoin()函数:
SELECT
round(tp.2, 2) AS avg_total,
tp.1 AS entries
FROM
(
SELECT
arrayJoin(arrayZip(countResample(0, 500, 100)(toInt16(total_amount)),
avgResample(0, 500, 100)(total_amount, toInt16(total_amount)))) AS tp
FROM payments
)
┌─avg_total─┬─entries─┐
│ 50.21 │ 21 │
│ 157.33 │ 20 │
│ 246.14 │ 24 │
│ 356.26 │ 31 │
│ 415.24 │ 4 │
└───────────┴─────────┘在这里,我们将两个数组的相应值组合成元组,并使用arrayJoin()函数将结果数组展开成表格:
控制空结果的聚合值
聚合函数对结果集不包含数据的情况有不同的反应。例如,count()将返回0,而avg()将产生nan值。
我们可以使用OrDefault()和OrNull()组合器来控制此行为。两者都会更改在数据集为空时使用的聚合函数的返回值:
-
OrDefault()将返回函数的默认值而不是nan,
-
OrNull()将返回NULL(并且还将更改返回类型为Nullable)。
考虑以下示例:
SELECT
count(),
countOrNull(),
avg(total_amount),
avgOrDefault(total_amount),
sumOrNull(total_amount)
FROM payments
WHERE total_amount > 1000
┌─count()─┬─countOrNull()─┬─avg(total_amount)─┬─avgOrDefault(total_amount)─┬─sumOrNull(total_amount)─┐
│ 0 │ ᴺᵁᴸᴸ │ nan │ 0 │ ᴺᵁᴸᴸ │
└─────────┴───────────────┴───────────────────┴────────────────────────────┴─────────────────────────┘正如我们在第一列中看到的,没有返回任何行。请注意,countOrNull()将返回NULL而不是0,avgOrDefault()会返回0而不是nan。
与其他组合器一起使用
与所有其他组合器一样,OrNull()和OrDefault()可以与不同的组合器一起使用以进行更高级的逻辑:
SELECT
sumIfOrNull(total_amount, status = 'declined') AS declined,
countIfDistinctOrNull(total_amount, status = 'confirmed') AS confirmed_distinct
FROM payments
WHERE total_amount > 420
┌─declined─┬─confirmed_distinct─┐
│ ᴺᵁᴸᴸ │ 1 │
└──────────┴────────────────────┘我们使用了sumIfOrNull()组合函数来仅计算被拒绝的付款,并在空集上返回NULL。countIfDistinctOrNull()函数计算不同的total_amount值,但仅适用于满足指定条件的行。
聚合数组
ClickHouse的Array类型在其用户中很受欢迎,因为它为表结构带来了很多灵活性。为了有效地操作Array列,ClickHouse提供了一组数组函数。为了简化对Array类型的聚合,ClickHouse提供了Array()组合器。这些将给定的聚合函数应用于数组列中的所有值,而不是数组本身:
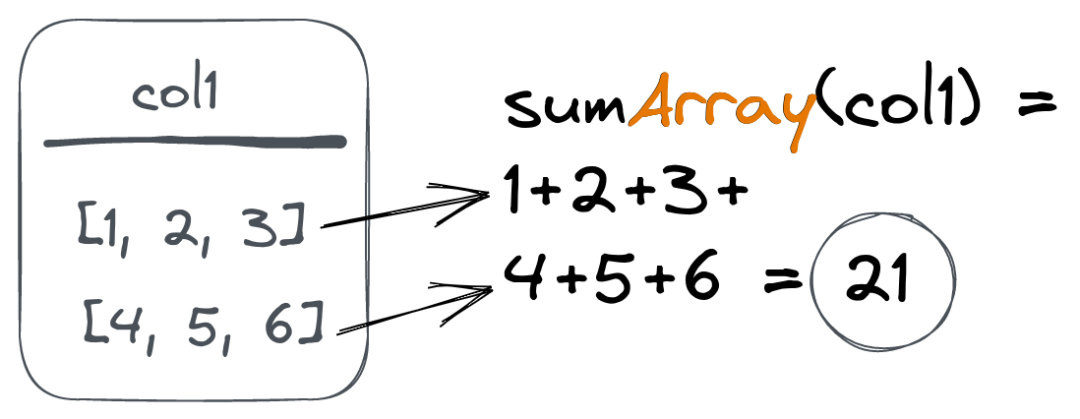
假设我们有以下表格(用示例数据填充):
CREATE TABLE article_reads
(
`time` DateTime,
`article_id` UInt32,
`sections` Array(UInt16),
`times` Array(UInt16),
`user_id` UInt32
)
ENGINE = MergeTree
ORDER BY (article_id, time)
┌────────────────time─┬─article_id─┬─sections─────────────────────┬─times────────────────────────────────┬─user_id─┐
│ 2023-01-18 23:44:17 │ 10 │ [16,18,7,21,23,22,11,19,9,8] │ [82,96,294,253,292,66,44,256,222,86] │ 424 │
│ 2023-01-20 22:53:00 │ 10 │ [21,8] │ [30,176] │ 271 │
│ 2023-01-21 03:05:19 │ 10 │ [24,11,23,9] │ [178,177,172,105] │ 536 │
...这个表用于存储文章里各个片段的阅读数据。当用户阅读一篇文章时,我们将阅读的片段保存到sections数组列中,并将相关的阅读时间保存到times列中。
让我们使用uniqArray()函数计算每篇文章阅读的唯一片段(section)数量,再使用avgArray()得到每个 片段的平均时间:
SELECT
article_id,
uniqArray(sections) sections_read,
round(avgArray(times)) time_per_section
FROM article_reads
GROUP BY article_id
┌─article_id─┬─sections_read─┬─time_per_section─┐
│ 14 │ 22 │ 175 │
│ 18 │ 25 │ 159 │
...
│ 17 │ 25 │ 170 │
└────────────┴───────────────┴──────────────────┘我们可以使用minArray()和maxArray()函数获取所有文章的最小和最大阅读时间:
SELECT
minArray(times),
maxArray(times)
FROM article_reads
┌─minArray(times)─┬─maxArray(times)─┐
│ 30 │ 300 │
└─────────────────┴─────────────────┘我们还可以使用groupUniqArray()函数与Array()组合器获取每篇文章的阅读部分列表:
SELECT
article_id,
groupUniqArrayArray(sections)
FROM article_reads
GROUP BY article_id
┌─article_id─┬─groupUniqArrayArray(sections)───────────────────────────────────────┐
│ 14 │ [16,13,24,8,10,3,9,19,23,14,7,25,2,1,21,18,12,17,22,4,6,5] │
...
│ 17 │ [16,11,13,8,24,10,3,9,23,19,14,7,25,20,2,1,15,21,6,5,12,22,4,17,18] │
└────────────┴─────────────────────────────────────────────────────────────────────┘另一个流行的函数是any(),它在聚合下返回任何列值,并且还可以与Array组合:
SELECT
article_id,
anyArray(sections)
FROM article_reads
GROUP BY article_id
┌─article_id─┬─anyArray(sections)─┐
│ 14 │ 19 │
│ 18 │ 6 │
│ 19 │ 25 │
│ 15 │ 15 │
│ 20 │ 1 │
│ 16 │ 23 │
│ 12 │ 16 │
│ 11 │ 2 │
│ 10 │ 16 │
│ 13 │ 9 │
│ 17 │ 20 │
└────────────┴────────────────────┘使用Array与其他组合器
Array组合器可以与任何其他组合器一起使用:
SELECT
article_id,
sumArrayIfOrNull(times, length(sections) > 8)
FROM article_reads
GROUP BY article_id
┌─article_id─┬─sumArrayOrNullIf(times, greater(length(sections), 8))─┐
│ 14 │ 4779 │
│ 18 │ 3001 │
│ 19 │ NULL │
...
│ 17 │ 14424 │
└────────────┴───────────────────────────────────────────────────────┘我们使用sumArrayIfOrNull()函数来计算阅读了超过八个部分的文章的总时间。请注意,对于阅读了零个超过八个部分的文章,将返回NULL,因为我们还使用了OrNull()组合器。
如果我们将array函数与组合器一起使用,我们甚至可以处理更高级的情况:
SELECT
article_id,
countArray(arrayFilter(x -> (x > 120), times)) AS sections_engaged
FROM article_reads
GROUP BY article_id
┌─article_id─┬─sections_engaged─┐
│ 14 │ 26 │
│ 18 │ 44 │
...
│ 17 │ 98 │
└────────────┴──────────────────┘在这里,我们首先使用arrayFilter函数过滤times数组,以删除所有小于120秒的值。然后,我们使用countArray来计算每篇文章的过滤时间(在我们的情况下是参与阅读)。
聚合映射
ClickHouse中另一种强大的类型是Map。与数组一样,我们可以使用Map()组合器将聚合应用于此类型。
假设我们有一个包含Map列类型的以下表:
CREATE TABLE page_loads
(
`time` DateTime,
`url` String,
`params` Map(String, UInt32)
)
ENGINE = MergeTree
ORDER BY (url, time)
┌────────────────time─┬─url─┬─params───────────────────────────────┐
│ 2023-01-25 17:44:26 │ / │ {'load_speed':100,'scroll_depth':59} │
│ 2023-01-25 17:44:37 │ / │ {'load_speed':400,'scroll_depth':12} │
└─────────────────────┴─────┴──────────────────────────────────────┘我们可以使用Map()组合器来进行sum()和avg()函数,以获得总加载时间和平均滚动深度:
SELECT
sumMap(params)['load_speed'] AS total_load_time,
avgMap(params)['scroll_depth'] AS average_scroll
FROM page_loads
┌─total_load_time─┬─average_scroll─┐
│ 500 │ 35.5 │
└─────────────────┴────────────────┘Map()组合器还可以与其他组合器一起使用:
SELECT sumMapIf(params, url = '/404')['scroll_depth'] AS average_scroll FROM page_loads聚合相应数组值
处理数组列的另一种方法是从两个数组中聚合相应的值。这将导致另一个数组。这可以用于矢量化数据(如矢量或矩阵),通过ForEach()组合器实现:
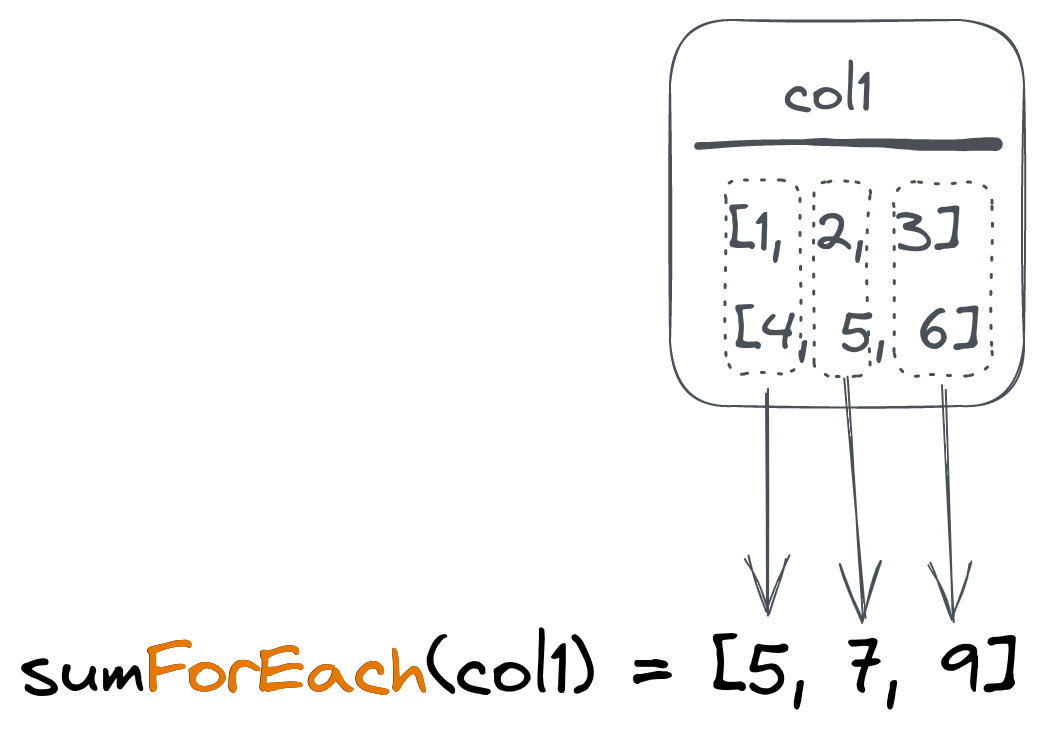
假设我们有以下包含向量的表格:
SELECT * FROM vectors
┌─title──┬─coordinates─┐
│ first │ [1,2,3] │
│ second │ [2,2,2] │
│ third │ [0,2,1] │
└────────┴─────────────┘为了计算坐标数组(向量)的平均值,我们可以使用avgForEach()组合函数:
SELECT avgForEach(coordinates) FROM vectors
┌─avgForEach(coordinates)─┐
│ [1,2,2] │
└─────────────────────────┘这将要求ClickHouse计算所有坐标数组的第一个元素的平均值,并将其放入结果数组的第一个元素中。然后对第二个和第三个元素重复相同的操作。
当然,还支持与其他组合器一起使用:
SELECT avgForEachIf(coordinates, title != 'second') FROM vectors
┌─avgForEachIf(coordinates, notEquals(title, 'second'))─┐
│ [0.5,2,2] │
└───────────────────────────────────────────────────────┘使用聚合状态
ClickHouse允许使用中间聚合状态而不是结果值。假设我们需要计算唯一值的计数,但我们不想保存值本身(因为它占用空间)。在这种情况下,我们可以使用uniq()函数的State()组合器来保存中间聚合状态,然后使用Merge()组合器来计算实际值:
SELECT uniqMerge(u)
FROM
(
SELECT uniqState(number) AS u FROM numbers(5)
UNION ALL
SELECT uniqState(number + 1) AS u FROM numbers(5)
)
┌─uniqMerge(u)─┐
│ 6 │
└──────────────┘在这里,第一个嵌套查询将返回1...5数字的唯一计数的状态。第二个嵌套查询为2...6数字返回相同的内容。然后,父查询使用uniqMerge()函数来合并我们的状态并获得我们看到的所有唯一数字的计数:
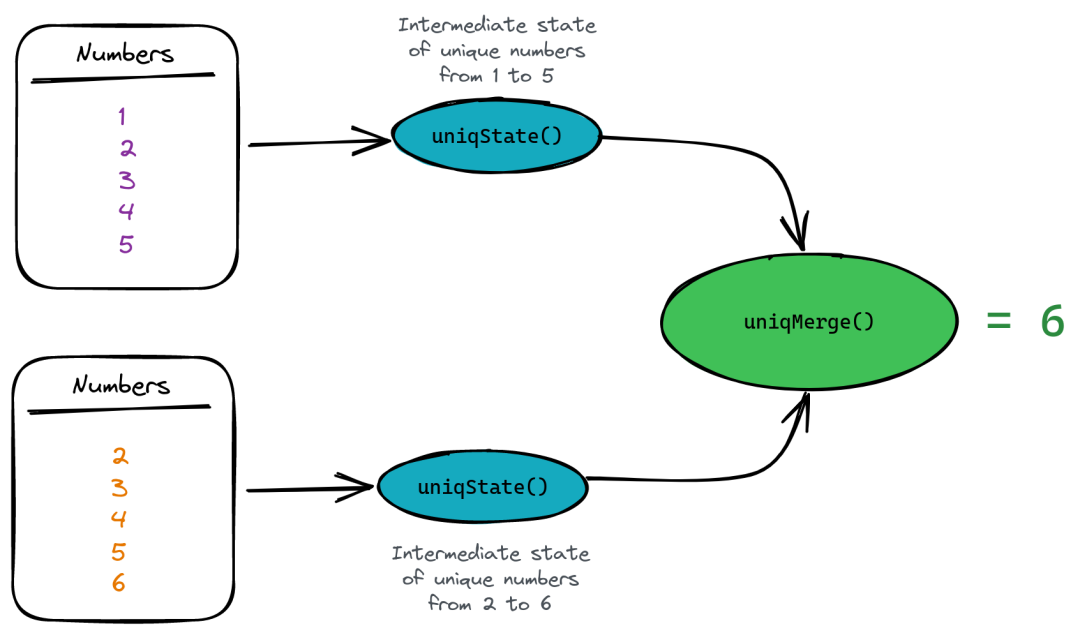
为什么我们要这样做?简单地因为聚合状态比原始数据占用的空间要小得多。当我们想将此状态存储在磁盘上时,这尤其重要。例如,uniqState()数据占用的空间比100万个整数数字小15倍:
SELECT
table,
formatReadableSize(total_bytes) AS size
FROM system.tables
WHERE table LIKE 'numbers%'
┌─table─────────┬─size───────┐
│ numbers │ 3.82 MiB │ <- we saved 1 million ints here
│ numbers_state │ 245.62 KiB │ <- we save uniqState for 1m ints here
└───────────────┴────────────┘ClickHouse为存储聚合状态,并在主键上自动合并它们提供了一个AggregatingMergeTree表引擎。让我们创建一个表,以存储先前示例中每日付款的聚合数据:
CREATE TABLE payments_totals
(
`date` Date,
`total_amount` AggregateFunction(sum, Float)
)
ENGINE = AggregatingMergeTree
ORDER BY date我们使用AggregateFunction类型,让ClickHouse知道我们将存储聚合的总状态而不是标量值。在插入时,我们需要使用sumState函数插入聚合状态:
INSERT INTO payments_totals SELECT
date(create_time) AS date,
sumState(total_amount)
FROM payments
WHERE status = 'confirmed'
GROUP BY date最后,我们需要使用sumMerge()函数获取结果值:
┌─sumMerge(total_amount)─┐
│ 12033.219916582108 │
└────────────────────────┘请注意,ClickHouse提供了一种简便的方法,可以使用基于物化视图的聚合表引擎。ClickHouse还提供了一个SimpleState组合器作为某些聚合函数(如'sum'或'min')的优化版本。
总结
在ClickHouse中,聚合函数组合器为对任何数据结构进行分析查询提供了几乎无限的可能性。我们可以向聚合添加条件,对数组元素应用函数,或者获取中间状态以聚合形式存储数据,但仍可用于查询。
Meetup 活动报名通知
好消息:ClickHouse Shenzhen User Group第1届 Meetup 已经开放报名了,将于2024年1月6日在深圳南山区海天二路33号腾讯滨海大厦举行,扫码免费报名


联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









