






一、报错内容:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 32.00 MiB. GPU 0 has a total capacity of 6.00 GiB of which 0 bytes is free. Of the allocated memory 5.26 GiB is allocated by PyTorch, and 60.93 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 32.00 MiB. GPU 0 has a total capacity of 6.00 GiB of which 0 bytes is free. Of the allocated memory 5.26 GiB is allocated by PyTorch, and 60.93 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management 以上报错内容表示GPU内存不够用来运行模型,实践探究后,发现有以下的原因:
①模型太深太复杂了,建议简化一下模型;
②输入的图像太大了,与上一条联动起来就会报错。可以修改一下batch_size或者resize一下输入的图像,但这可能会影响结果的。
二、解决方案
1、充分利用GPU内存
一般显卡内存都会分为专用内存和共享内存。通过观察,如果不经过设置,训练模型时是不会动用共享GPU内存的。

具体设置方式:
①首先,先将英伟达驱动更新到536版本以上,进入以下网址,选择设备显卡的基本信息,就会自动推荐给你下载了,下载完之后点开就能自动下载了,这一步很简单,不多说。
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
②打开"NVIDIA控制面板",点开"管理3D设置",右边有个功能叫"CUDA - 系统内存回退政策",设置为"偏好系统内存回退",如下图所示,这个设置不同电脑可能不一样,我的是笔记本电脑的3060,灵活设置就好了。
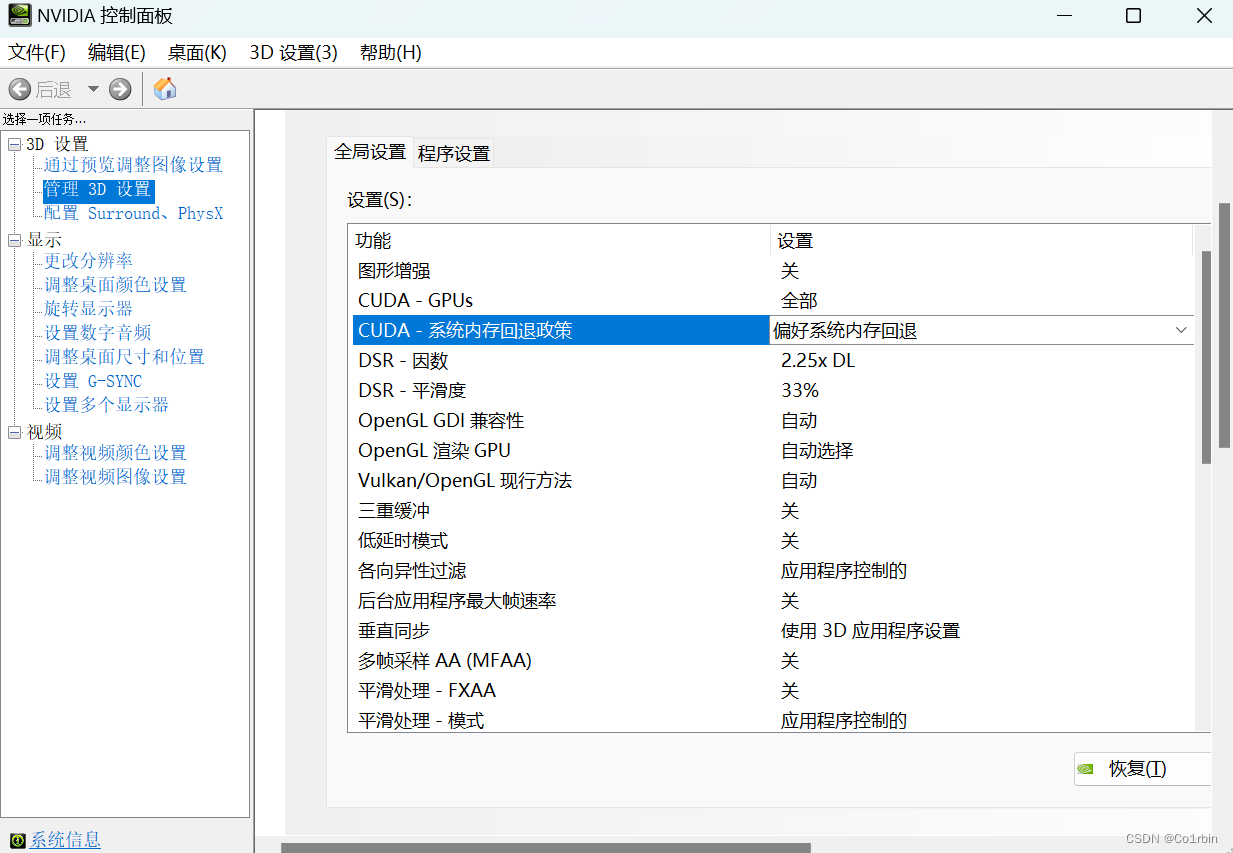
设置完之后训练模型时就能自动使用共享GPU内存了,但是缺点就是运行速度会受到影响。
2、及时清空显存
torch.cuda.empty_cache()将该代码放在循环训练代码结尾处。
3、检查点存储(亲测最有效)
使用"torch.utils.checkpoint",可以在每次前向传播的过程中重新计算编码器和解码器层的输出,节省一些显存,但缺点就是会消耗更多计算时间。
from torch.utils.checkpoint import checkpoint
# 使用检查点存储
def checkpointed_forward(module, *inputs):
def custom_forward(*inputs):
return module(*inputs)
return checkpoint(custom_forward, *inputs)
#以UNET为例
##############################################
#假如定义层的代码如下(这里的代码别放进去,只是示范用)
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.layer1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.layer2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.layer3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.layer4 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.layer5 = nn.Conv2d(512, 1024, kernel_size=3, padding=1)
##############################################
class checkpoint_UNet(UNet):
def forward(self, x):
x = checkpointed_forward(self.layer1, x)
x = checkpointed_forward(self.layer2, x)
x = checkpointed_forward(self.layer3, x)
x = checkpointed_forward(self.layer4, x)
x = checkpointed_forward(self.layer5, x)
return x
4、使用混合精度
可以减少显存使用,同时加快计算速度。
#这是参考代码,从自己的代码中截取下来的,不完整,只是提供理解,有问题可以评论区评论
from torch.cuda.amp import autocast, GradScaler
accumulation_steps = 4 # 定义累积步数
scaler = torch.cuda.amp.GradScaler() # 混合精度训练的梯度缩放器
epoch = 0
while epoch < 10:
for i, (image, segment_image) in enumerate(tqdm.tqdm(data_loader)):
image, segment_image = image.to(device), segment_image.to(device)
with torch.cuda.amp.autocast(): # 使用自动混合精度
out_image = net(image)
train_loss = loss_fun(out_image, segment_image.long())
train_loss = train_loss / accumulation_steps
scaler.scale(train_loss).backward()
if (i + 1) % accumulation_steps == 0:
scaler.step(opt)
scaler.update()
opt.zero_grad()
插一嘴,这里定义的累计步数是梯度累积操作,可以模拟更大的批次大小的同时不增加显存的使用。
三、总结
这个问题研究了好久,我也是刚接触到,肯定会有纰漏,请各位进行指正,并且有问题的话可以提在评论区一起学习成长。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









