









相信很多小伙伴目前跑深度学习用的不是实验室主机,而是自己的游戏本/轻薄本/台式主机,同时又只有单卡,导致训练速率慢、常常容易爆显存等情况。本文对于采用CPU/LAPTOP-GPU/普通的台式主机如何加快训练进程,会有较为明确的描述和解决方法,如果目前你存在设备算力差等类似情况的话,相信参考本文的步骤进行尝试是能够解决的。
基本报错情况如下:
RuntimeError: CUDA out of memory| 系统及版本 | Windows10 |
| 示例电脑 | 联想小新2021酷睿版(轻薄本) 联想拯救者R7000电脑(游戏本) i7-10700+RTX4000(台式机) |
| 适用人群 | ALL |
一、内存/显存不足?速度慢?
1.调整参数
要解决内存/显存不足的问题,一般的方法是调整自己的参数--batchsize和--workers,降低它们,能节约许多内存、防止爆显存。这么做的缺点就是导致训练速度会降低,对于CPU训练,尤其是非服务器CPU,这么做并没有很大影响,但对于GPU训练,则会导致速度降低很多。同时,较低的batchsize会有很大可能影响训练的精度。此外,还可以通过降低图像尺寸的输入大小,越大占用资源越大,反之则相反。
2.关闭不必要的应用程序
很多时候小伙伴在训练的时候,在训练的时候自己打开了一些占用内存或显存的程序,结果训练程序无端断开显示内存/显存不足。这是因为训练时程序占用了大部分资源,而训练对资源的占用并不是一条直线,而是忽高忽低的,因此导致以上问题。
因此,在训练时尽量关闭一切无用的程序,不进行多余的操作。这也能一定程度上加快训练的速度、防止爆显存。
3.处理数据集
某些训练工作在训练时对输入的图像分辨率通常没有要求很高,往往最简单的方式可以通过调整图片后缀来减小图片的大小,这对于稍大一些的数据集具有显著的效果。
笔者在进行CV训练的时候,有采用16G内存的I5-11代CPU训练过一个700M,标签数量大于一万的数据集,能发现训练的时候速度十分慢,且笔者即使不用任何操作,也会每隔固定几个epoch显示爆内存。当这种问题出现的时候,笔者进行了如下操作成功解决。
我们知道,JPEG格式采用有损压缩,可以在保持相对较高图像质量的同时,大幅度减小文件大小,特别适合于摄影图像或写实图像。相反,PNG格式虽然支持无损压缩,但通常会产生比JPEG更大的文件,尤其是当图片颜色复杂或含有透明度时。
此时我们可以对于图片的格式进行保留副本的测试性修改,比如将图片从png格式转换为jpeg格式等。测试该操作前、后的几个epoch的数据,在固定随机数种子的情况下进行数据的对比,若数据没有改变,说明此举是可以的。
4.更换优化器
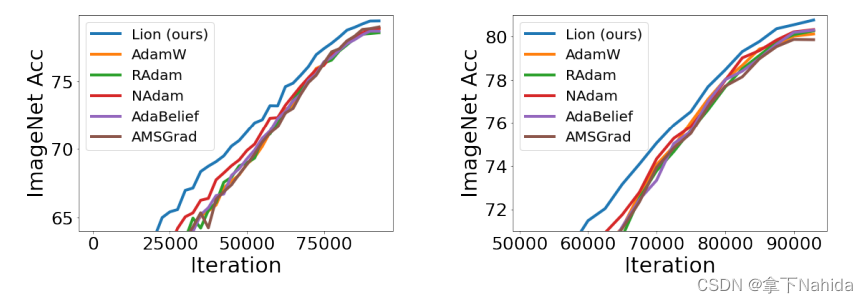
对同一数据集,采用AdamW和Adam、SGD、以及Lion等优化器训练时花费的时间不同,且很多时候采用SGD花费的显存/内存低。
Adam由于需要存储并更新梯度的第一阶和第二阶矩估计值,通常比SGD需要更多的计算资源。但在实践中,Adam通常比SGD更快地收敛,因为它能够更智能地更新权重。今年来,新颖的Lion优化器据称在许多方面击败了Adam,且训练速度也比Adam略快。因此,选择何种优化器作为Baseline需要读者自己根据需要选择。
5.采用不同的算法进行测试,选择符合能够自己实验目的的算法
比如对于目标检测实验。有YOLO系列、SSD系列、Faster-RCNN系列、DETR系列等多种系列算法。显然,采用不同的算法作为Baseline时,可以显著改善显存/内存不足的问题。而具体采用什么样的算法,通常需要读者自己根据需要选择。
6.实验方向尽量偏向轻量级网络的创新与测试
比如当你采用目标检测的YOLO系列时,可以更换更小、速度更快的卷积快。比如新颖的PConv。
采用更小的主干是一般主流的选择。比如近年新颖的Mobilenet系列、PP-LCNet主干等。关于这些,我的博客一般有详细的方法手把手教你如何改进。
比如以下主干改进
【YOLOv5/v7改进系列】替换骨干网络为MobileNetv3-CSDN博客
【YOLOv5/v7改进系列】替换骨干网络为VanillaNet-CSDN博客
比如采用较小的检测头,如采用Detect与YOLOX的解耦合头对比,解耦合头就不是很好的选择。
综上所述,采用对内存/显存要求小的模块/组件,是不错的选择。若实验时发现采用轻量级的模块也能提高整体的效率,则其对于该任务的先进性则可见一斑。
7.如何探寻方法使得自己的模型更早趋向拟合?
A.寻找合适的算法
一般来说,不同算法在不同参数条件下趋向拟合的速度不同,比如YOLO一般需要300epoch,RT-DETR则100左右即拟合。因此,寻找不同的算法作为自己的Baseline对于加速训练进程是至关重要的的。
B.采用预训练权重
同时,除了不同算法外,可以发现当你采用预训练权重时,对许多较难拟合的模型有一定的帮助。
C.建立相似的训练条件
设一算法在150epoch曲线趋向拟合,先跑epoch=(30,60,120)的对照实验,若发现曲线斜率相似的(其实大部分时候肉眼观察就可以),以此为暂时可对照的baseline排列组合炼丹。当然此方法对于baseline值较低的有奇效,但对于初始值已达较高值的则没有很大效果。
D.从数据集角度出发
可以先从数据集出发,假设数据集有1000张同类别图像(当然不同类别也可以),按等比例抽取一定量的图片训练,和选取好的baseline作比较,若曲线上身趋势一致,则可作为暂时的可参照实验排列组合炼丹。
同学们可发现在一定情况下图像越多训练的每一个step图像上升是很平稳的,这也是依据趋势进行观察的一个原因所在。
8.启用AMP算法
在深度学习领域,AMP通常指的是自动混合精度训练,这是一种优化技术,旨在加速神经网络的训练过程同时尽可能减少内存使用。传统的深度学习模型训练通常使用单精度浮点数(float32)进行所有计算,而自动混合精度训练则智能地在单精度和半精度(float16)之间切换,具体如下:
- 半精度(FP16):用于大多数权重和梯度的存储及计算,因为许多矩阵运算对精度要求不高,半精度可以显著减少所需的内存带宽和存储空间,同时利用现代GPU的Tensor Cores加速计算。
- 单精度(FP32):保留用于关键操作,比如损失函数计算、更新梯度步骤等,以确保数值稳定性,避免因精度降低导致的模型性能退化。
通过这种策略,AMP能够在不牺牲模型最终精度的情况下,显著加快训练速度并减少GPU内存占用,这对于大型模型或资源受限的环境尤其有利。
AMP加快深度学习训练速度的原因
- 减少内存占用:使用半精度浮点数可以将内存需求减半,使得更大规模的模型能够放入有限的GPU内存中训练。
- 增加计算效率:现代GPU硬件支持半精度的并行计算,尤其是在使用Tensor Cores时,可以实现远超单精度的计算速度。
- 减少数据传输时间:内存带宽是训练过程中的瓶颈之一,半精度数据需要较少的带宽,降低了数据传输时间。
- 智能管理精度:混合精度训练策略自动确定哪些部分的计算需要更高精度,避免了不必要的精度损失,保持了模型性能。
9.更换激活函数
确定了自己的训练需求后,若需要进一步改进加速、防止爆显存,换用激活函数也是一种不错的选择。它虽然没有显著降低参数量,但由于其本身特性,如ReLU,相较于SiLU通常训练、检测速度更快。当然,若是发论文的同学,选择你的baseline算法,仍需参考该算法论文或其开源的项目中运用的激活函数作为base。
二、虚拟内存不足?
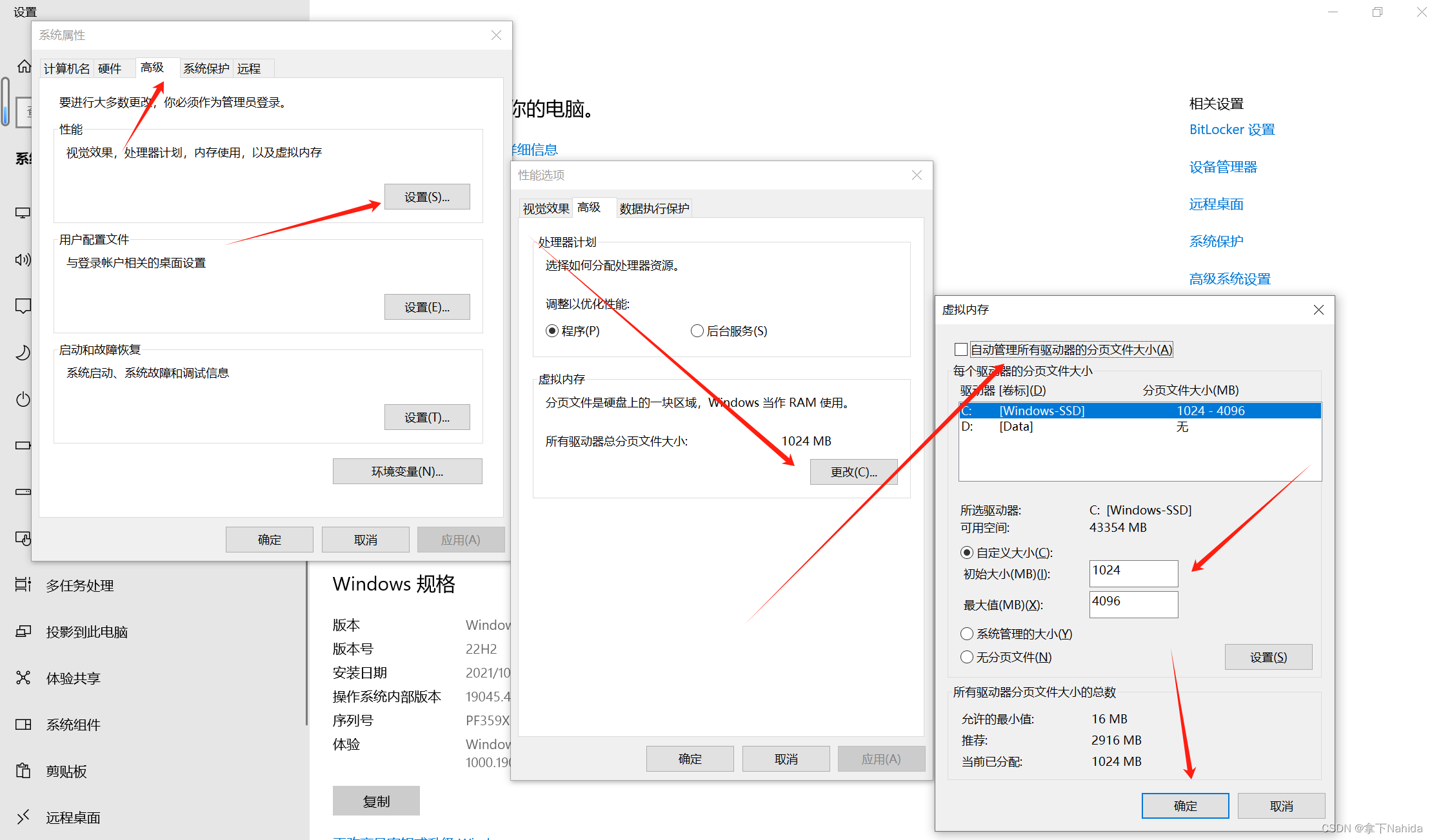
当训练时显示“OSError: [WinError 1455] 页面文件太小,无法完成操作”时,说明虚拟内存不足。一般在YOLOv3/v5等训练时,很经常会弹出这个错误,这个时候要解决需要做的就是在你设置虚拟环境的盘增加虚拟内存的值。
具体解决方式是:此电脑右键——属性——高级系统设置——高级——性能——设置——高级——更改——在你设置虚拟环境的盘增加虚拟内存的值。
这么做会解决这个错误,但也会占用你在硬盘对应分区中设置好的虚拟内存值。
三、设置良好的实验计划
笔者在初涉实验时,常常会犯错误,比如没有对应情况就测baseline,测好baseline又没有保护好文件导致丢失重测,torch版本无意识更新了导致环境不一样等令人窒息的操作,笔者是软件工程专业的,深知软件的开发过程其实和深度学习很像,是一个循序渐进的过程,当我们提前制定好正确的计划的时候,对训练的加速是事半功倍的。或者说,你本应可能犯的错,却没有犯,或你能降低犯错的概率,利用有限的资源得到更高的收益,这就能达到我们做计划的目的。
对于如何找到创新点,可以关注我的博客。
【保姆级零基础教程】哪些创新点可以快速改进提升YOLO?-CSDN博客
【零基础保姆级教程】零基础如何快速进入YOLOv5/v7的科研状态?-CSDN博客
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!



















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











