




 本文介绍了用户特征分析在软件开发中的重要性,涵盖用户画像分析、RFM用户分群、聚类分析和麦肯锡八法等方法。此外,CoCode的AI工具如Co-Project和需求分析工具助力提升效率,减少开发成本。
本文介绍了用户特征分析在软件开发中的重要性,涵盖用户画像分析、RFM用户分群、聚类分析和麦肯锡八法等方法。此外,CoCode的AI工具如Co-Project和需求分析工具助力提升效率,减少开发成本。
用户特征分析直接影响需求分析、用户体验设计等软件开发的关键环节,如果不对用户特征进行科学分析,不能获得用户真实意图,这直接影响需求分析质量,对整个项目影响较大。
因此我们需要用科学的方法对目标用户进行特征分析。而常见的目标用户特征分析方法有:用户画像分析、RFM用户分群、聚类分析、麦肯锡八法。
1、用户画像分析
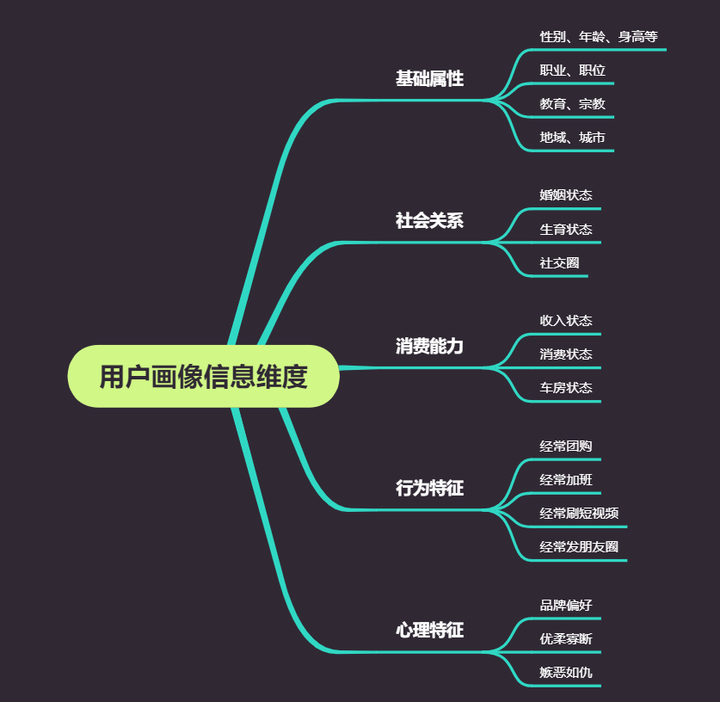
一般来说用户画像分析,分为基础属性、社会关系、消费能力、行为特征和心理特征。如基础属性包括:性别、年龄、职业、城市、教育等基础信息。
此方法是基于大量的数据,建立用户的属性标签体系,同时利用这种属性标签体系描述用户。比如,通过用户画像分析刻画出用户大约为18~24岁、一线城市、男性、喜欢玩游戏和看小说,这就是用户群体特征。
2、RFM用户分群
RFM模型是衡量用户价值和用户创利能力的重要工具和手段,此模型以其简单、好解释、容易上手等特点被大多数企业所接纳。
此模型涉及的3个重要变量,直接影响企业销售和利润的客户行为字段:
R(recency)最近一次消费时间;
F(frequency)用户下单频率;
M(monetary)用户消费金额
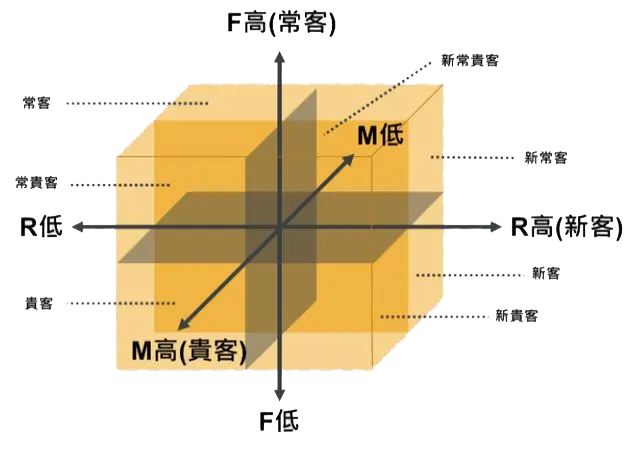
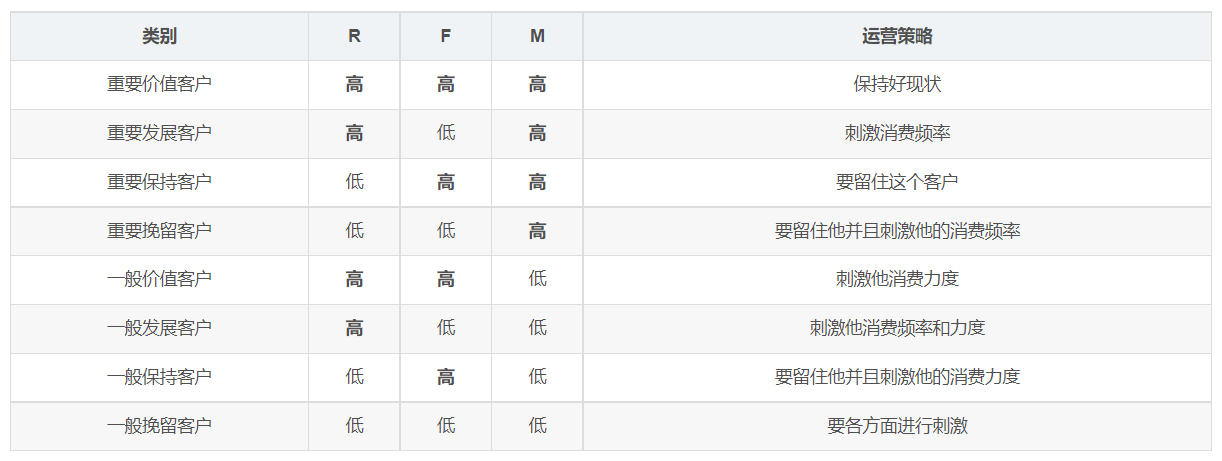
此模型根据用户近期的购买行为、购买频率、消费金额三个维度描述客户的价值状态,从而将客户划分为一般保持客户、一般发展客户、一般价值客户、一般挽留客户、重要保持客户、重要发展客户、重要价值客户、重要挽留客户等八个级别。进而根据客户级别,制定相应的运营策略。
3、聚类分析
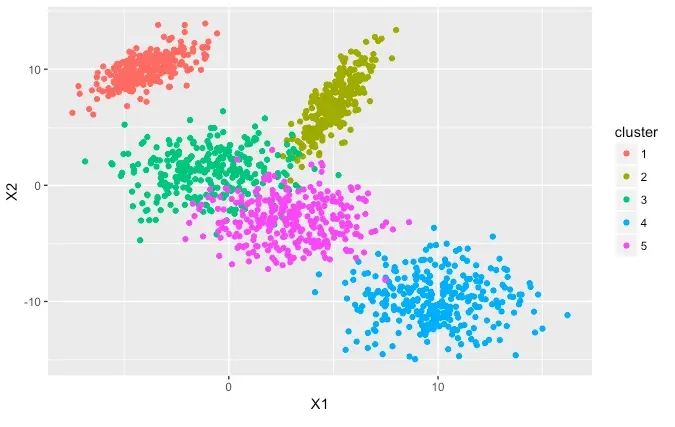
常见的聚类分析方法有K-means聚类算法,通过k-means算法可以对用户行为进行聚类,比如,针对用户在淘宝商城买东西的频次、价格、浏览的时长,可以进行聚类分析。
需要注意的是:k-means算法对噪声和异常值非常敏感,这些异常的个别数据对平均值的影响很大;数据标准化是聚类分析中必不可少的一个环节;在聚类分析中,参与聚类的特征不能太多。
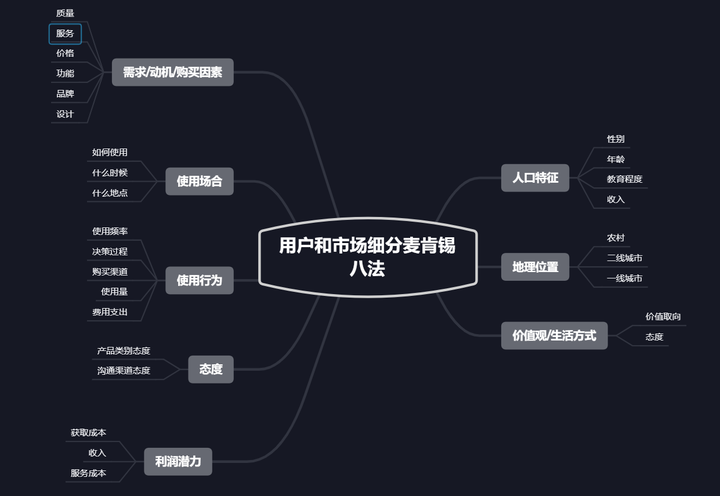
4、用户和市场细分麦肯锡八法
此方法主要是从如下几个维度进行分析:需求/动机/购买因素、使用场合、使用行为、态度、利润潜力、人口特征、地理位置、价值观/生活方式。如需求/动机/购买因素包括:质量、服务、价格、功能、品牌和设计。
另外,为了进一步提高用户需求分析的效率和准确性,减轻产品经理的工作量,CoCode的Co-Project智能项目管理工具,近期推出了需求条目化功能,使用AI能够将用户需求自动生成标准用户故事,这让我们无需再手动一一录入需求,大大减轻了工作量。
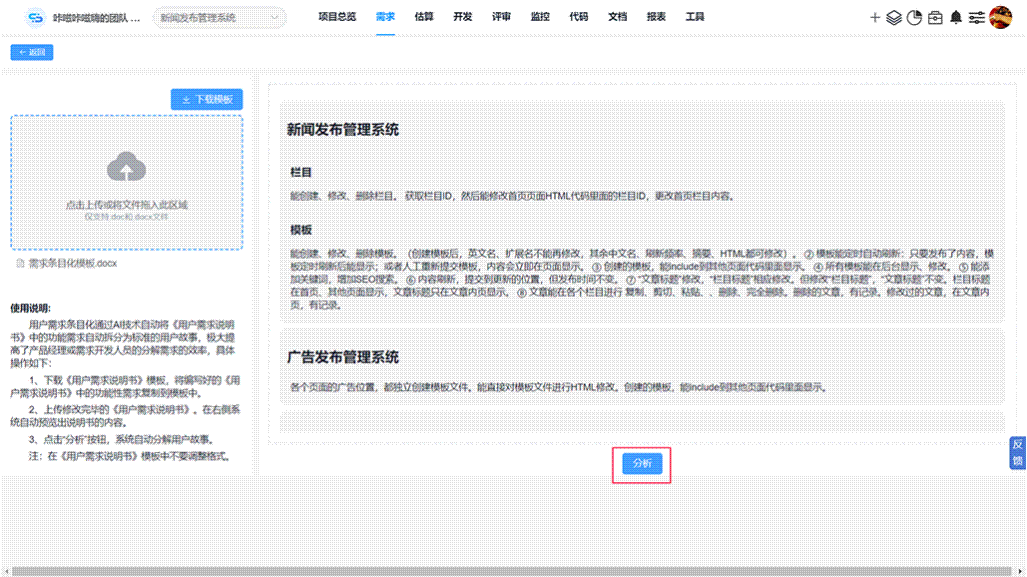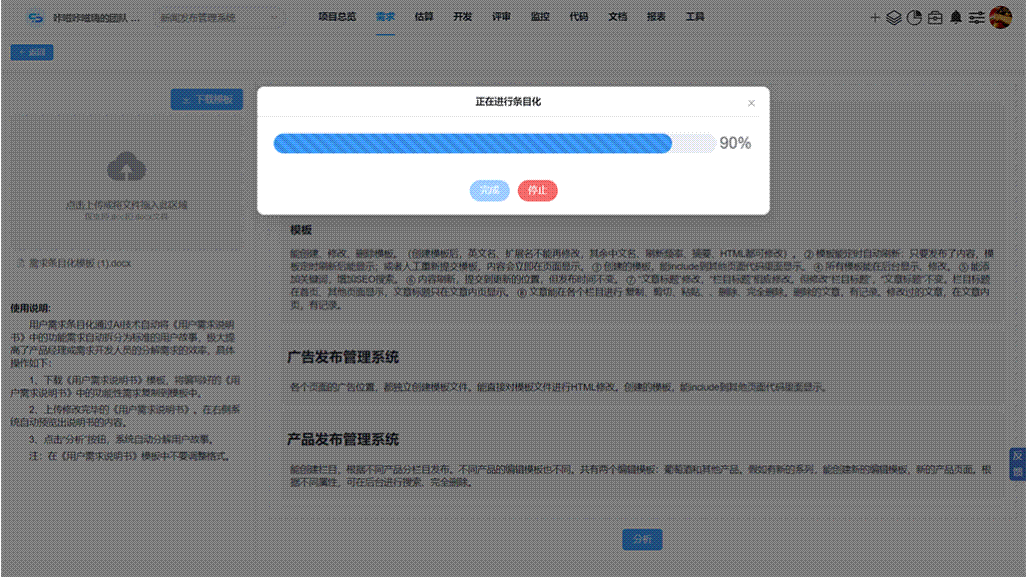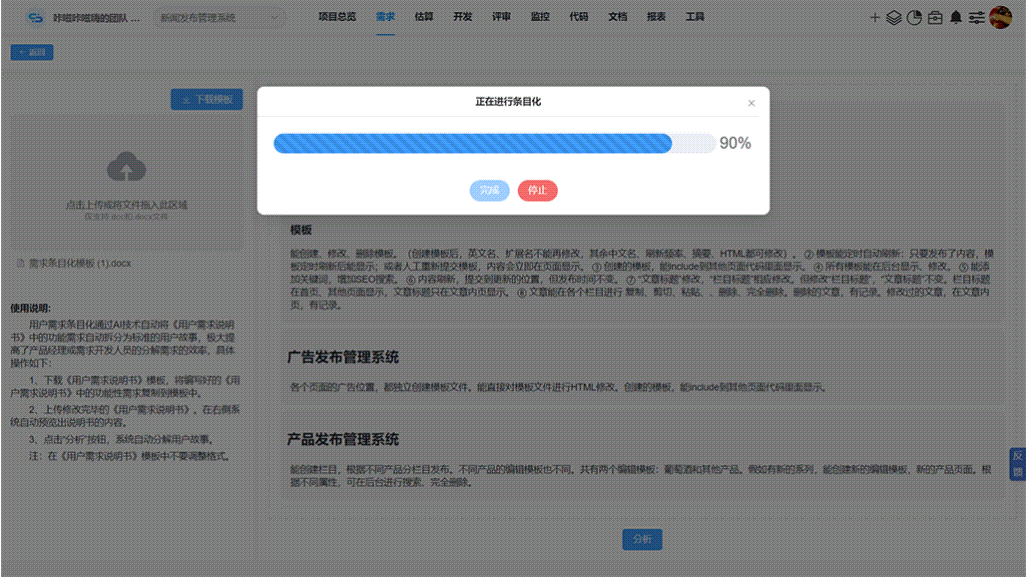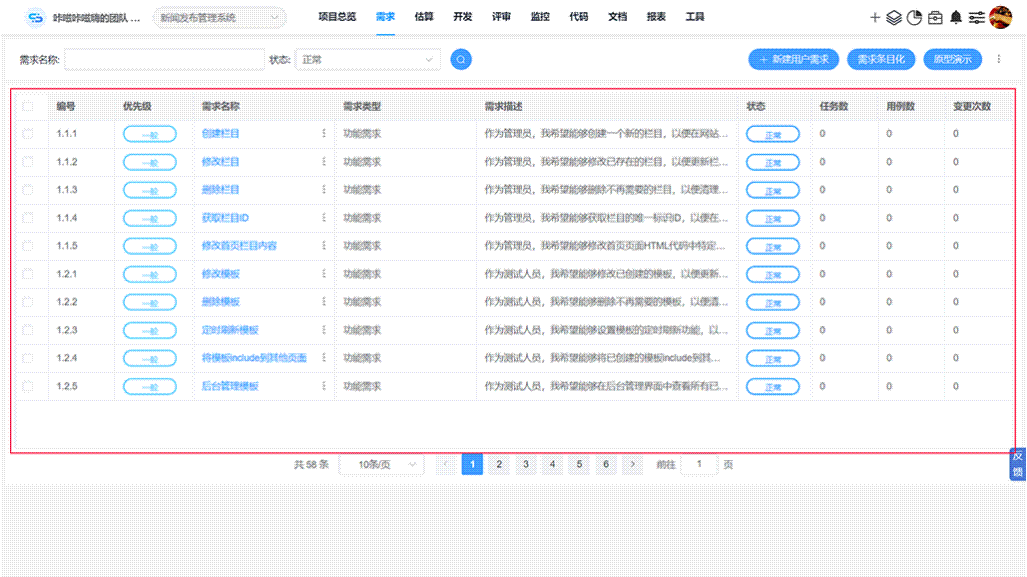
而需求分析工具,使用AI精准锁定和快速修复需求缺陷,提高需求分析质量;工具使用快速功能点估算方法,通过调整功能点值(复杂度、修改类型、重用程度)和设置计算调整因子(系统特征因子、工作量因子、费用调整因子),多角度多层级地调整影响因子,从而能够更精准地自动估算项目规模、工作量和产品报价,使用此工具能够节省15-25%的开发成本。
CoCode发布一系列AI开发工具:Co-Project智能项目管理工具(需求条目化、自动生成测试用例)、需求分析工具、评审分析工具。CMMI落地工具上线,全面支持CMMI3-5级高效落地。


















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









