






本篇来总结一些分布式训练的知识,还是按照面经的形式给出,希望能给到大家一些帮助。
题目
1 训练一个LLM,需要的显存规模跟参数的关系是什么?
2. 如果有N张显存足够大的显卡,怎么加速训练?
3. 如果有N张显卡,但每个显卡显存都不足以装下一个完整的模型,应该怎么办?
4. PP推理时是串行的,1个GPU计算但其他空闲,有什么其他的优化方式?
5. DP、TP、PP这3种并行方式可以叠加吗?
6. 3D并行或者直接上多机多卡的ZeRO的条件是什么?
答案
1. 训练一个LLM,需要的显存跟参数的关系是什么?
主要公式是 模型本身占用显存 + 多个batch数据运算的存储 , 跟实际精度,模型大小、中间变量计算以及batch邮官
2. 如果有N张显存足够大的显卡,怎么加速训练?
数据并行(DP),充分利用多张显卡的算力。
3. 如果有N张显卡,但每个显卡显存都不足以装下一个完整的模型,应该怎么办?
PP,流水线并行,需要分层加载,把不同的层加载到不同的GPU上(accelerate的device_map)
4. PP推理时是串行的,1个GPU计算但其他空闲,有什么其他的优化方式?
- 流水线并行(PP), 横向切分,也就是分层加载到不同的显卡上
- 张量并行(TP),纵向切分,在 DeepSpeed 里叫模型并行(MP)
下面来简单梳理一下DP,PP,TP,ZeRO以及其中MP的关系。
- DP Data parallelism
数据并行算法在多个设备上都拷贝一份完整的模型参数,彼此之间可以独立计算,所以每个设备传入的输入数据不一样,这也是为什么叫数据并行。
只不过每隔一段时间(比如一个batch或者若干个batch)后需要彼此之间同步模型权重的梯度。
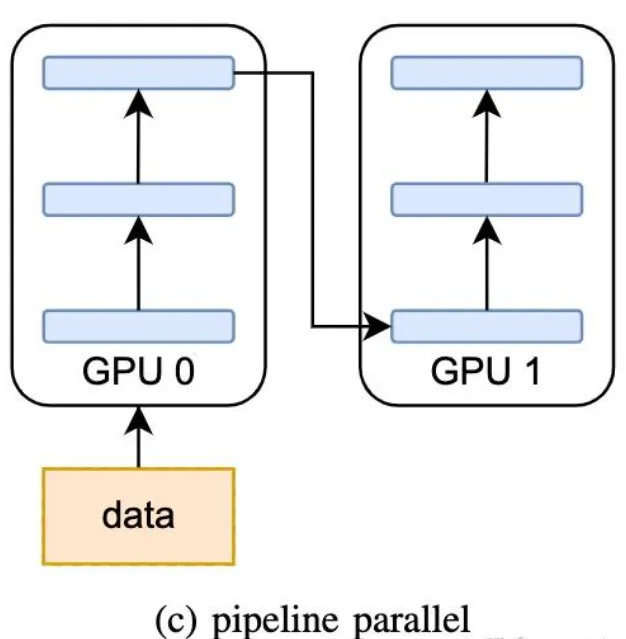
- PP Pipeline Parallelism
属于 Model Parallelism (MP), 模型并行算法,它是模型做层间划分,即inter-layer parallelism。
以下图为例,如果模型原本有6层,你想在2个GPU之间运行pipeline,那么每个GPU只要按照先后顺序存3层模型即可。
- TP Tensor Parallelism
Tensor Parallelism就是对模型层内做划分,也叫inter-layer parallelism。
就是把一个变量分散到多个设备并共同完成某个或多个计算操作。对于单个 Tensor/Op 很大 或者模型很大(如GPT3, chatGPT等)的情况,Tensor parallelism 的重要性非常明显。
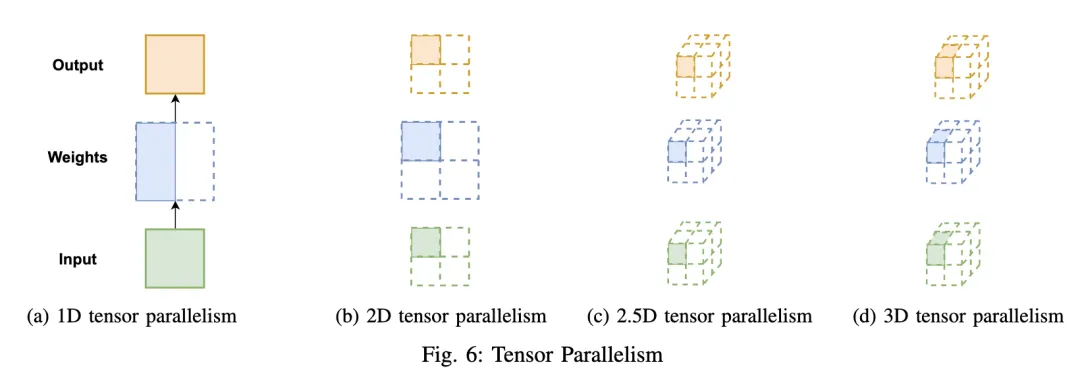
TP最好带入到不同的模型中去学习。
- ZeRO
5. DP、TP、PP这3种并行方式可以叠加吗?
可以,DP+TP+PP,这就是3D并行。
如果真有1个超大模型需要预训练,3D并行是必不可少的。
单卡80g,可以完整加载小于40B的模型,但是训练时需要加上梯度和优化器状态,5B模型就是上限了,更别说 activation的参数也要占显存,batch size还得大。而现在100亿以下(10B以下)的LLM只能叫small LLM。
6. 3D并行或者直接上多机多卡的ZeRO的条件是什么?
3D并行的基础是,节点内显卡间NVLINK超高速连接才能上TP。显卡有没有NVLINK都是个问题。
Zero3 需要满足通信量,假设当65B模型用Zero3,每一个step的每一张卡上需要的通信量是195GB(3倍参数量),也就 是1560Gb。万兆网下每步也要156s的通信时间,非常不现实。
有需要全套的AI大模型面试题及答案解析资料的小伙伴,可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









