







环境准备
推荐按照原作者推荐的环境:代码测试云GPU环境:GPU RTX 3060、CUDA v11.2;虽然本博主没有用。
准备数据集
这里的数据集是在百度上下载的。
对于深度学习的数据集,为了避免数据的分布而影响到模型的训练,数据集应当要尽可能包含目标物体的各类场景,并且各种场景下的图像的数量尽可能相近,这样训练出来的模型才具有很好的泛化性能。数据集应该包含:
-
不同尺寸、比例的图像
-
不同拍摄环境(光照、设备、拍摄角度、遮挡、远近、大小)
-
不同形态(完整西瓜、切瓣西瓜、切块西瓜)
-
不同部位(全瓜、瓜皮、瓜瓤、瓜子)
-
不同时期(瓜秧、小瓜、大瓜)
-
不同背景(人物、菜地、抠图)
-
不同图像域(照片、漫画、剪贴画、油画)
这里的数据集存放是在
\dataset\子目录,如果需要自建自己的数据集,需要按照同样的数据结果对数据进行处理,否则可能会出现数据导入错误。
爬取数据代码
# coding:gbk
import os
import time
import requests
import urllib3
urllib3.disable_warnings()
# 进度条库
from tqdm import tqdm
cookies = {
'BDqhfp': '%E7%8B%97%E7%8B%97%26%26NaN-1undefined%26%2618880%26%2621',
'BIDUPSID': '06338E0BE23C6ADB52165ACEB972355B',
'PSTM': '1646905430',
'BAIDUID': '104BD58A7C408DABABCAC9E0A1B184B4:FG=1',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'H_PS_PSSID': '35836_35105_31254_36024_36005_34584_36142_36120_36032_35993_35984_35319_26350_35723_22160_36061',
'BDSFRCVID': '8--OJexroG0xMovDbuOS5T78igKKHJQTDYLtOwXPsp3LGJLVgaSTEG0PtjcEHMA-2ZlgogKK02OTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF': 'tJPqoKtbtDI3fP36qR3KhPt8Kpby2D62aKDs2nopBhcqEIL4QTQM5p5yQ2c7LUvtynT2KJnz3Po8MUbSj4QoDjFjXJ7RJRJbK6vwKJ5s5h5nhMJSb67JDMP0-4F8exry523ioIovQpn0MhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0D6bBjHujtT_s2TTKLPK8fCnBDP59MDTjhPrMypomWMT-0bFH_-5L-l5js56SbU5hW5LSQxQ3QhLDQNn7_JjOX-0bVIj6Wl_-etP3yarQhxQxtNRdXInjtpvhHR38MpbobUPUDa59LUvEJgcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj0DKLtD8bMC-RDjt35n-Wqxobbtof-KOhLTrJaDkWsx7Oy4oTj6DD5lrG0P6RHmb8ht59JROPSU7mhqb_3MvB-fnEbf7r-2TP_R6GBPQtqMbIQft20-DIeMtjBMJaJRCqWR7jWhk2hl72ybCMQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjHCet5DJJn4j_Dv5b-0aKRcY-tT5M-Lf5eT22-usy6Qd2hcH0KLKDh6gb4PhQKuZ5qutLTb4QTbqWKJcKfb1MRjvMPnF-tKZDb-JXtr92nuDal5TtUthSDnTDMRhXfIL04nyKMnitnr9-pnLJpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuj6tWj6j0DNRabK6aKC5bL6rJabC3b5CzXU6q2bDeQN3OW4Rq3Irt2M8aQI0WjJ3oyU7k0q0vWtvJWbbvLT7johRTWqR4enjb3MonDh83Mxb4BUrCHRrzWn3O5hvvhKoO3MA-yUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRCqVIKa3f',
'BDSFRCVID_BFESS': '8--OJexroG0xMovDbuOS5T78igKKHJQTDYLtOwXPsp3LGJLVgaSTEG0PtjcEHMA-2ZlgogKK02OTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF_BFESS': 'tJPqoKtbtDI3fP36qR3KhPt8Kpby2D62aKDs2nopBhcqEIL4QTQM5p5yQ2c7LUvtynT2KJnz3Po8MUbSj4QoDjFjXJ7RJRJbK6vwKJ5s5h5nhMJSb67JDMP0-4F8exry523ioIovQpn0MhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0D6bBjHujtT_s2TTKLPK8fCnBDP59MDTjhPrMypomWMT-0bFH_-5L-l5js56SbU5hW5LSQxQ3QhLDQNn7_JjOX-0bVIj6Wl_-etP3yarQhxQxtNRdXInjtpvhHR38MpbobUPUDa59LUvEJgcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj0DKLtD8bMC-RDjt35n-Wqxobbtof-KOhLTrJaDkWsx7Oy4oTj6DD5lrG0P6RHmb8ht59JROPSU7mhqb_3MvB-fnEbf7r-2TP_R6GBPQtqMbIQft20-DIeMtjBMJaJRCqWR7jWhk2hl72ybCMQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjHCet5DJJn4j_Dv5b-0aKRcY-tT5M-Lf5eT22-usy6Qd2hcH0KLKDh6gb4PhQKuZ5qutLTb4QTbqWKJcKfb1MRjvMPnF-tKZDb-JXtr92nuDal5TtUthSDnTDMRhXfIL04nyKMnitnr9-pnLJpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuj6tWj6j0DNRabK6aKC5bL6rJabC3b5CzXU6q2bDeQN3OW4Rq3Irt2M8aQI0WjJ3oyU7k0q0vWtvJWbbvLT7johRTWqR4enjb3MonDh83Mxb4BUrCHRrzWn3O5hvvhKoO3MA-yUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRCqVIKa3f',
'indexPageSugList': '%5B%22%E7%8B%97%E7%8B%97%22%5D',
'cleanHistoryStatus': '0',
'BAIDUID_BFESS': '104BD58A7C408DABABCAC9E0A1B184B4:FG=1',
'BDRCVFR[dG2JNJb_ajR]': 'mk3SLVN4HKm',
'BDRCVFR[-pGxjrCMryR]': 'mk3SLVN4HKm',
'ab_sr': '1.0.1_Y2YxZDkwMWZkMmY2MzA4MGU0OTNhMzVlNTcwMmM2MWE4YWU4OTc1ZjZmZDM2N2RjYmVkMzFiY2NjNWM4Nzk4NzBlZTliYWU0ZTAyODkzNDA3YzNiMTVjMTllMzQ0MGJlZjAwYzk5MDdjNWM0MzJmMDdhOWNhYTZhMjIwODc5MDMxN2QyMmE1YTFmN2QyY2M1M2VmZDkzMjMyOThiYmNhZA==',
'delPer': '0',
'PSINO': '2',
'BA_HECTOR': '8h24a024042g05alup1h3g0aq0q',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'Accept': 'text/plain, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1647837998851_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=MCwzLDIsNiwxLDUsNCw4LDcsOQ%3D%3D&ie=utf-8&sid=&word=%E7%8B%97%E7%8B%97',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
# 爬取图像并且保存到本地中
def craw_single_data(keyword,DOWNLOAD_NUM=200):
"""
keyword:参数,表示要爬取的数据的关键词;
DOWNLOAD_NUM:参数,表示要爬取的数据的数量;
返回值:无;
爬取的数据会保存在当前文件的同一层目录喜爱的 dataset/keyword 目录中,本函数调用一次可以和生成一个keyword的数据
"""
if os.path.exists('dataset/'+keyword):
print('文件夹 dataset/{} 已经存在,之后爬取的数据将直接保存在该文件夹中'.format(keyword))
else:
os.makedirs('dataset/{}'.format(keyword))
print('新建文件夹 dataset/{}'.format(keyword))
count=1
with tqdm(total=DOWNLOAD_NUM,position=0,leave=True) as pbar:
# 爬取第几张
num=0
# 是否继续爬取
FLAG=True
while FLAG:
page=30*count
params=(
('tn', 'resultjson_com'),
('logid', '12508239107856075440'),
('ipn', 'rj'),
('ct', '201326592'),
('is', ''),
('fp', 'result'),
('fr', ''),
('word', f'{keyword}'),
('queryWord', f'{keyword}'),
('cl', '2'),
('lm', '-1'),
('ie', 'utf-8'),
('oe', 'utf-8'),
('adpicid', ''),
('st', '-1'),
('z', ''),
('ic', ''),
('hd', ''),
('latest', ''),
('copyright', ''),
('s', ''),
('se', ''),
('tab', ''),
('width', ''),
('height', ''),
('face', '0'),
('istype', '2'),
('qc', ''),
('nc', '1'),
('expermode', ''),
('nojc', ''),
('isAsync', ''),
('pn', f'{page}'),
('rn', '30'),
('gsm', '1e'),
('1647838001666', ''),
)
# 关闭SSL验证
response = requests.get('https://image.baidu.com/search/acjson', headers=headers, params=params, cookies=cookies,verify=False)
if response.status_code==200:
try:
json_data=response.json().get("data")
if json_data:
for x in json_data:
type=x.get('type')
if type not in ['gif']:
img=x.get('thumbURL')
fromPageTitleEnc=x.get('fromPageTitleEnc')
try:
resp=requests.get(url=img,verify=False)
time.sleep(1)
# 保存到文件夹中
file_save_path=f'dataset/{keyword}/{num}.{type}'
with open(file_save_path,'wb') as f:
f.write(resp.content)
f.flush()
num+=1
# 更新进度条
pbar.update(1)
if num>DOWNLOAD_NUM:
FLAG=False
print('{}张图像爬取完毕'.format(num))
break
except Exception:
pass
except Exception:
pass
else:
break
count+=1
# 调用测试
# class_list=['黄瓜','南瓜']
# for each in class_list:
# craw_single_data(each,DOWNLOAD_NUM=5)
测试结果:\dataset\

删除多余的文件
因为模型训练时是直接导入\dataset\下所有的子文件的,所以如果\dataset\以及它的子文件下有其他非法的文件,会导致训练出错,所以可以检查下 dataset 下有没有其他非法文件已经其子文件内有无非法文件。原作者有给出相应的代码,博主这里不太需要就省略了。
fruit81水果数据图像分类数据集下载
其他数据集请查看github。
统计图像的尺寸和比例分布代码
这里可视化图像尺寸分布使用了散点密度图(主要用来计算样本点的出现次数,即密度)。
# coding:gbk
from ctypes.wintypes import PLARGE_INTEGER
from logging import warning
import os
import numpy as np
import cv2
from tqdm import tqdm
import pandas as pd
from scipy.stats import gaussian_kde
from matplotlib.colors import LogNorm
import matplotlib.pyplot as plt
# %matplotlib inline # plt.show()
def visual_dimensions_and_proportions(dataset_path):
"""
dataset_path:参数,表示原始数据的路径;
返回值:无;
本函数会生成原始数据集的图像宽和高的分布。
可能遇到一个警告“ibpng warning: iCCP: known incorrect sRGB profile”
"""
os.chdir(dataset_path)
list=os.listdir()
# 输出数据集下的子文件
print(list)
# 遍历图像
df=pd.DataFrame()
# 遍历每个类别
# tqdm是快速可扩展的python进度条,可以在python长循环中添加一个进度提示信息,用户只需要封装任意的迭代器
for fruit in tqdm(list):
os.chdir(fruit)
# 遍历每一张图像
for file in os.listdir():
try:
img=cv2.imread(file)
df=df.append({'类别':fruit,'文件名':file,'图像宽':img.shape[1],'图像高':img.shape[0]},ignore_index=True)
except:
print(os.path.join(fruit,file),'读取错误')
os.chdir('../')
os.chdir('../')
# 打印信息
print(df)
# 可视化图像尺寸分布:散点密度图(主要用来计算样本点的出现次数,即密度)
x=df['图像宽']
y=df['图像高']
# 一组一组(x,y)
xy=np.vstack([x,y])
# 通过gaussian_kde估计x和y的联合分布,得到数据点的密度z
z=gaussian_kde(xy)(xy)
# 按照密度排序,将密度最大的点排到最后
idx=z.argsort()
x,y,z=x[idx],y[idx],z[idx]
plt.figure(figsize=(10,10))
# s绘制点的大小,c绘制点的颜色,默认是蓝色,marker表示标记的样式,camp是浮点数数组时候使用
plt.scatter(x,y,c=z,s=5,cmap='Spectral_r')
plt.tick_params(labelsize=15)
xy_max=max(max(df['图像宽']),max(df['图像高']))
plt.xlim(xmin=0,xmax=xy_max)
plt.ylim(ymin=0,ymax=xy_max)
plt.xlabel('width',fontsize=25)
plt.ylabel('height',fontsize=25)
# 保存
plt.savefig('图像尺寸分布.pdf',dpi=120,bbox_inches='tight')
# 显示
plt.show()
# 测试用例
# 指定数据集路径
# dataset_path='fruit81_full'
# visual_dimensions_and_proportions(dataset_path)
运行结果:
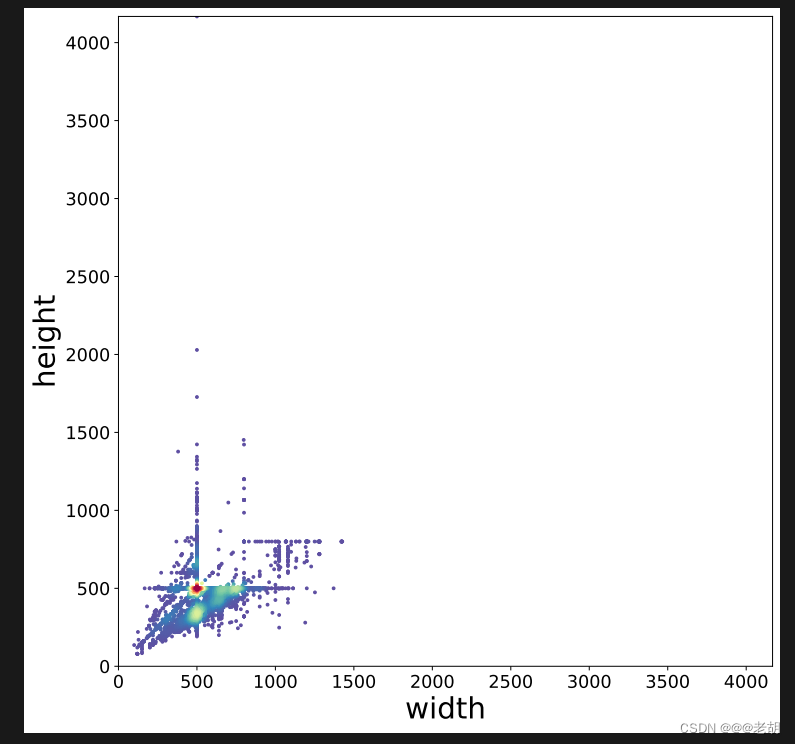
划分训练集和数据集代码
# coding:gbk
from email.mime import image
from multiprocessing.spawn import old_main_modules
import os
import shutil
import random
import pandas as pd
def split_data(dataset_path,dataset_name='dataset',test_frac=0.2):
"""
dataset_path:需要划分训练集和测试集的原始数据路径;
dataset_name:划分数据后的数据集命名;
test_frac:测试集的比例;
返回值:无;
本函数用来分割训练集和测试集。
"""
# 随机种子,便于复现
random.seed(123)
# 创建各类目录
li=os.listdir(dataset_path)
# 创建train目录
os.mkdir(os.path.join(dataset_path,'train'))
# 常见test目录
os.mkdir(os.path.join(dataset_path,'test'))
# 在训练集和测试集中分别创建各类的子文件夹
for fruit in li:
os.mkdir(os.path.join(dataset_path,'train',fruit))
os.mkdir(os.path.join(dataset_path,'test',fruit))
# 划分数据集
df=pd.DataFrame()
print('{:^18} {:^18} {:^18}'.format('类别','训练集数据个数','测试集数据个数'))
for fruit in li:
# 读取该类别下的所有图像文件名
old_dir=os.path.join(dataset_path,fruit)
images_filename=os.listdir(old_dir)
# 随机打乱
random.shuffle(images_filename)
# 划分训练集和测试集
# 测试集的数量
testset_numer=int(len(images_filename)*test_frac)
# 需要移动到测试集的图像名字
testset_images=images_filename[:testset_numer]
# 需要移动到测试集的图像名字
trainset_images=images_filename[testset_numer:]
# 移动数据集到test
for image in testset_images:
old_img_path=os.path.join(dataset_path,fruit,image)
new_img_path=os.path.join(dataset_path,'test',fruit,image)
shutil.move(old_img_path,new_img_path)
# 移动数据集到train
for image in trainset_images:
old_img_path=os.path.join(dataset_path,fruit,image)
new_img_path=os.path.join(dataset_path,'train',fruit,image)
shutil.move(old_img_path,new_img_path)
# 删除旧目录
# 确保旧文件夹中的所有图像均被移走
assert len(os.listdir(old_dir))==0
# 删除文件夹
shutil.rmtree(old_dir)
# 输出每一个类别中数据的个数
print('{:^18} {:^18} {:^18}'.format(fruit,len(trainset_images),len(testset_images)))
# 保存到表格中
df=df.append({'class':fruit,'trainset':len(trainset_images),'testset':len(testset_images)},ignore_index=True)
# 重命名
shutil.move(dataset_path,dataset_name)
df['total']=df['trainset']+df['testset']
df.to_csv('数据量统计.csv',index=False)
# 简单测试
# 指定数据集路径
dataset_path='fruit81_full'
dataset_name='dataset'
# 测试集的比例
test_frac=0.2
split_data(dataset_path,dataset_name,test_frac)
运行结果:

可视化图像代码
# coding:gbk
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from mpl_toolkits.axes_grid1 import ImageGrid
import numpy as np
import math
import os
import cv2
def visual_dataset(path,N=36):
"""
path:需要可视化的文件路径;
N:可视化的图像的数量;
本函数用来对图像进行可视化。
"""
# n行n列
n=math.floor(np.sqrt(N))
# 读取文件夹中所有图像
images=[]
for img in os.listdir(path)[:N]:
img_path=os.path.join(path,img)
# 解决中文路径的问题
img_bgr = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8),-1)
# cv2读取的顺序为bgr,需要转换为正常的rgb
img_rgb=cv2.cvtColor(img_bgr,cv2.COLOR_BGR2RGB)
images.append(img_rgb)
# 画图
fig=plt.figure(figsize=(10,10))
grid=ImageGrid(fig,111,# 绘制子图
nrows_ncols=(n,n),# 创建n行n列的axes网格
axes_pad=0.02,# 网格间距
share_all=True)
# 遍历每张图像
for ax,im in zip(grid,images):
ax.imshow(im)
ax.axis('off')
plt.tight_layout()
plt.show()
# 简单测试
path='dataset/train'
li=os.listdir(path)
for item in li:
file_path=os.path.join(path,item)
l=len(os.listdir(file_path))
N=36 if 36<l else l
visual_dataset(file_path,N)
运行结果(诸如此类):
统计各类别的数量
# coding:gbk
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
def visual_quantity(path):
"""
path:需要显示数据分布的表;
本函数用来显示数据的分布。
"""
# 中文字体
matplotlib.rc('font',family='SimHei')
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
# 导入表格
df=pd.read_csv(path)
print(df.shape)
# 指定可视化的特征
# feature='total'
# df=df.sort_values(by=feature,ascending=False)
plt.figure(figsize=(22,7))
x=df['class']
y1=df['testset']
y2=df['trainset']
# 柱状图宽度
width=0.55
# 横轴文字旋转
plt.xticks(rotation=90)
plt.bar(x,y1,width,label='测试集')
plt.bar(x,y2,width,label='训练集',bottom=y1)
plt.xlabel('类别',fontsize=20)
plt.ylabel('图像数量',fontsize=20)
# 设置坐标文字大小
plt.tick_params(labelsize=13)
# 图例
plt.legend(fontsize=16)
# 保存
plt.savefig('各类别图像数量.pdf',dpi=120,bbox_inches='tight')
plt.show()
# 简单测试
path='数据量统计.csv'
visual_quantity(path)
运行结果:
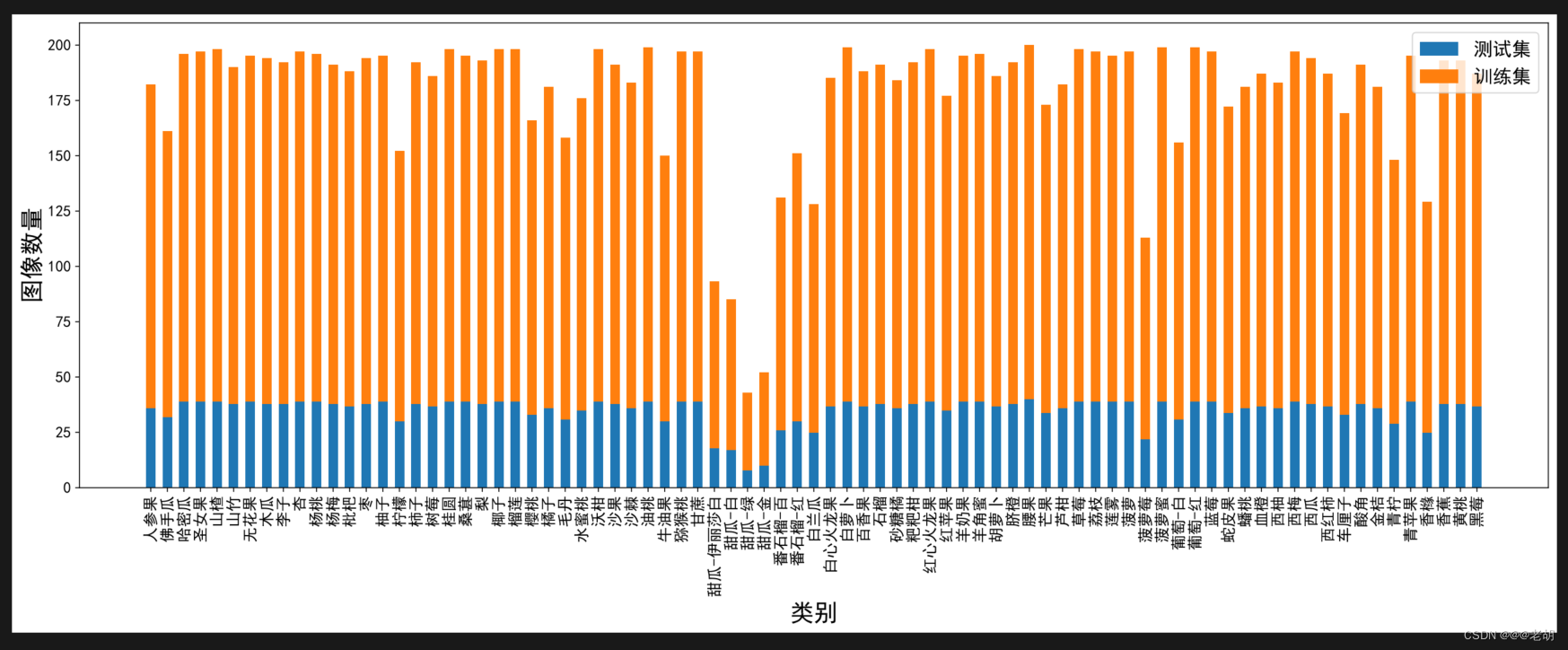
这里的代码与github上可能有一丢丢不同,大家想看全面点还是要看github上原版的代码以及原作者的视频讲解,博主这里只是博主按需学习的一些经验哦!
声明:这里只是做一个图像分类任务,不作为商业用途,不涉及任何利益交易,甚至不作为毕业设计。侵权可以删哦!














 2903
2903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









