







作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
简书地址:https://www.jianshu.com/p/abc2acf092a3
这篇教程是翻译Peter Roelants写的神经网络教程,作者已经授权翻译,这是原文。
该教程将介绍如何入门神经网络,一共包含五部分。你可以在以下链接找到完整内容。
- (一)神经网络入门之线性回归
- Logistic分类函数
- (二)神经网络入门之Logistic回归(分类问题)
- (三)神经网络入门之隐藏层设计
- Softmax分类函数
- (四)神经网络入门之矢量化
- (五)神经网络入门之构建多层网络
Logistic分类函数
这部分教程将介绍两部分:
* Logistic函数
* 交叉熵损失函数
如果我们利用神经网络进行分类,对于二分类问题,t=1或者t=0,我们能在logistic回归中使用logistic函数。对于多分类问题,我们使用softmax函数来处理多项式logistic回归。本教程我们先解释有关logistic函数的知识,后续教程会介绍softmax函数的知识。
我们先导入教程需要使用的软件包。
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as pltLogistic函数
假设我们的目标是根据输入的z去预测分类t。概率方程P(t=1|z)表示输出y根据logisitc函数y=σ(z)得到的值。σ被定义为:
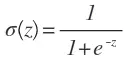
根据函数分类的概率t=1或者t=0,我们能得到以下公式:
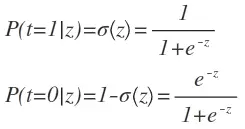
注意一下,其实z就是P(t=1|z)与P(t=0|z)的比值求对数。
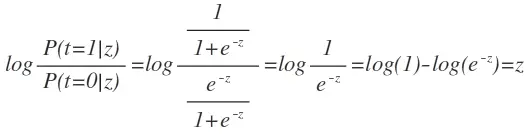
logistic函数在下面的代码中logistic(z)实现,并且可视化了logistic函数。
# Define the logistic function
def logistic(z):
return 1 / (1 + np.exp(-z))# Plot the logistic function
z = np.linspace(-6,6,100)
plt.plot(z, logistic(z), 'b-')
plt.xlabel('$z$', fontsize=15)
plt.ylabel('$\sigma(z)$', fontsize=15)
plt.title('logistic function')
plt.grid()
plt.show()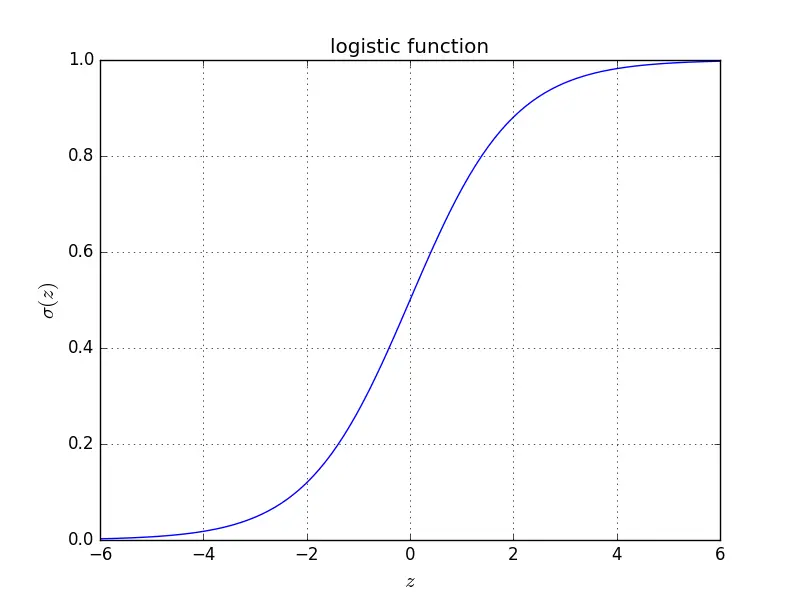
Logistic函数求导
因为神经网络一般使用梯度下降来优化,所以我们需要先求出y对于z的倒数,即∂y/∂z可以表示为:
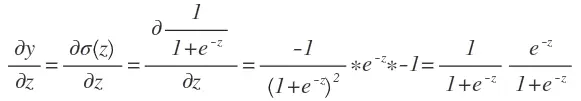
因为1−σ(z))=1−1/(1+e^−z)=e−z/(1+e^−z),所以我们又可以把上式简化为:
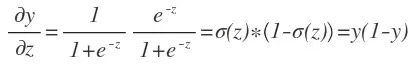
logistic_derivative(z)函数实现了Logistic函数的求导。
# Define the logistic function
def logistic_derivative(z):
return logistic(z) * (1 - logistic(z))# Plot the derivative of the logistic function
z = np.linspace(-6,6,100)
plt.plot(z, logistic_derivative(z), 'r-')
plt.xlabel('$z$', fontsize=15)
plt.ylabel('$\\frac{\\partial \\sigma(z)}{\\partial z}$', fontsize=15)
plt.title('derivative of the logistic function')
plt.grid()
plt.show()
对于logistic函数的交叉熵损失函数
模型的输出结果y=σ(z)可以被表示为一个概率y,如果t=1,或者概率1-y,如果t=0。我们把这个记为P(t=1|z)=σ(z)=y。
在神经网络中,对于给定的一组参数θ,我们可以使用最大似然估计来优化参数。参数θ将输入的样本转化成输入到Logistic函数中的参数z,即z = θ * x。最大似然估计可以写成:
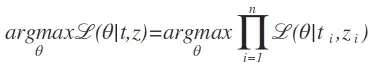
因为对于给定的参数θ,去产生t和z,根据联合概率我们又能将似然函数L(θ|t,z)改写成P(t,z|θ)。由于P(A,B) = P(A|B) ∗ P(B),我们又可以简化联合概率:
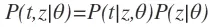
因为我们不关心有关z的概率,所以我们可以把原来的似然函数改写成:
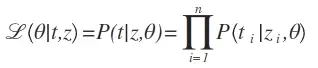
因为t服从伯努力分布,而且如果给定参数θ,那么P(t|z)=y就是一个确定的值,因此我们又可以改写概率方程:
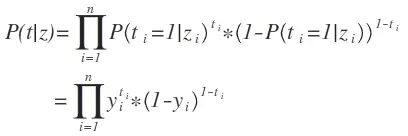
由于对数函数是单调递增函数,我们可以依此优化对数似然函数
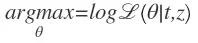
该函数的最大值和常规的似然函数的最大值一样,所以我们计算对数似然函数如下,
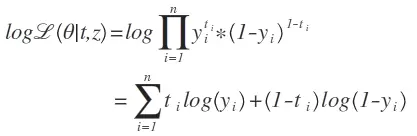
我们最小化这个负对数似然函数,等价于最大化似然函数。一个典型的误差函数可以设计为如下交叉熵误差函数:
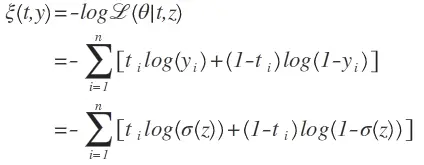
这个函数可能看起来比较复杂,但是如果我们把它拆分开来看,就会比较简单。
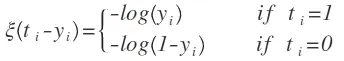
从上式中我们可以发现,如果样本被正确分类,那么损失函数L(t,y)和负对数概率函数在表达式上面是一样的,即
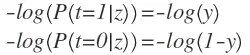
因为t只能取值0或者1,所以我们能将L(t, y)写为:
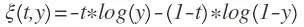
如果你要分析每一个训练数据,那么就是下式:

另一个我们使用交叉熵函数的原因是,在简单Logistic回归中,交叉熵函数是一个凸损失函数,全局最小值很容易找到。
对于logistic函数的交叉熵损失函数的求导
对于损失函数∂ξ/∂y求导,计算如下:
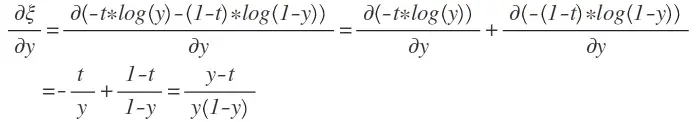
现在,我们对输入参数z进行求导将变得很容易。
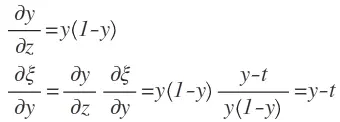
至此,完整求导完成。
作者:chen_h
微信号 & QQ:862251340
简书地址:https://www.jianshu.com/p/abc2acf092a3
CoderPai 是一个专注于算法实战的平台,从基础的算法到人工智能算法都有设计。如果你对算法实战感兴趣,请快快关注我们吧。加入AI实战微信群,AI实战QQ群,ACM算法微信群,ACM算法QQ群。长按或者扫描如下二维码,关注 “CoderPai” 微信号(coderpai)
















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









