




研究对象
数据集: 乳腺癌数据集 breast cancer 的原型是一组病灶造影图片,数据集提供者从每张图片中提取了30个特征,一共569个样本,其中阳性样本357,阴性样本212。
数据集特征名称、目标类别、数据集大小如下

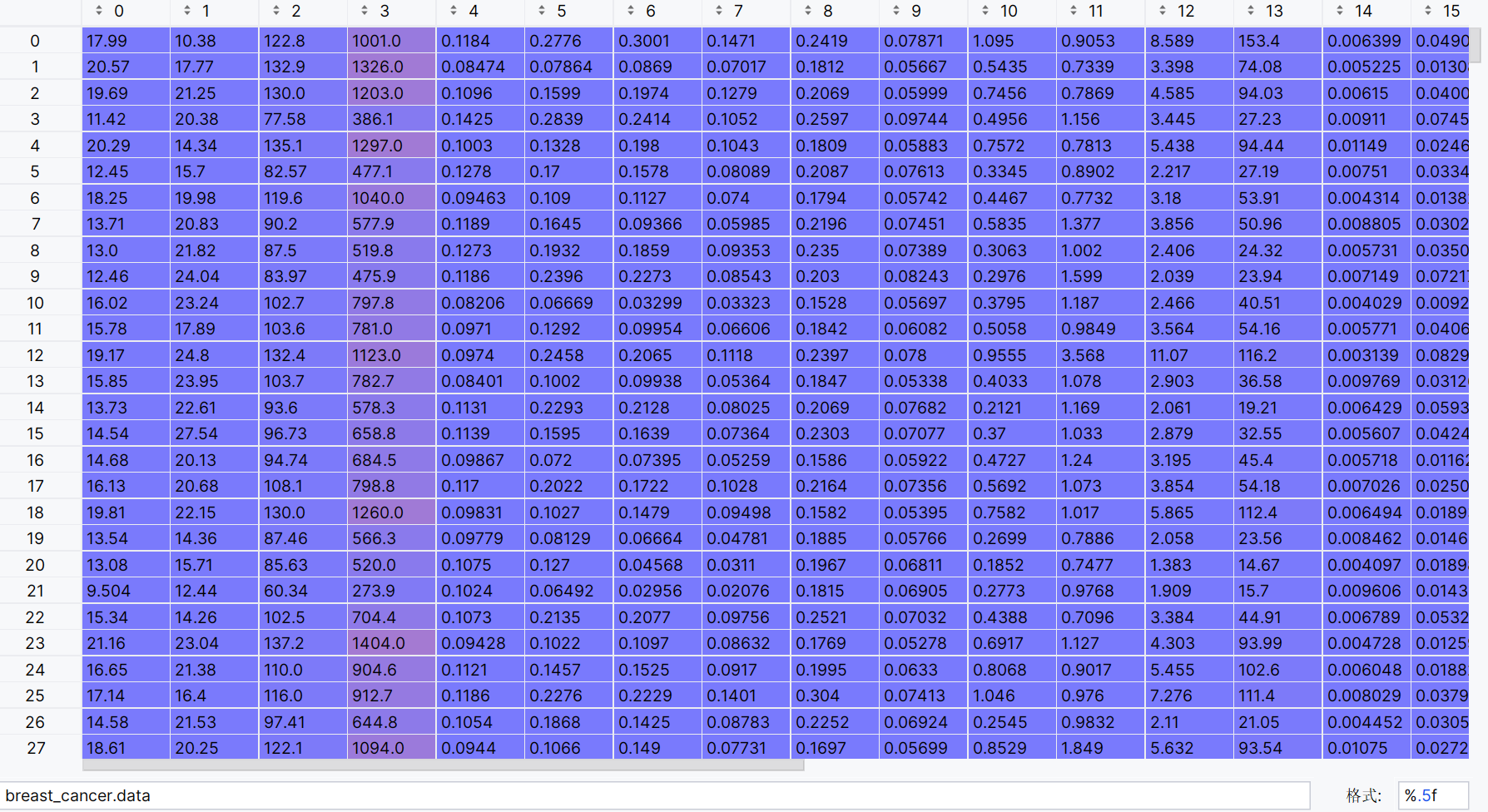
数据如下:
逻辑分类概念
原理
逻辑回归(Logistic Regression)是一种用于二分类问题的分类算法。它的原理基于线性回归和逻辑函数(也称为Sigmoid函数)的组合。逻辑回归的目标是根据输入特征的线性组合来预测样本属于某个类别的概率。
假设存在一组输入特征 x = (x₁, x₂, …, xₙ),并且每个特征都与一个权重参数 w = (w₁, w₂, …, wₙ) 相关联。
将输入特征与权重参数的线性组合表示为 z = w₁x₁ + w₂x₂ + … + wₙxₙ + b,其中 b 是偏置项。
将线性组合 z 输入到逻辑函数(Sigmoid函数)中,用于将线性输出转换为概率值。Sigmoid函数的公式为:σ(z) = 1 / (1 + exp(-z))。
得到的概率值表示样本属于正类的概率,而 1 减去该概率则表示样本属于负类的概率。
训练逻辑回归模型的目标是最大化似然函数(或最小化对数损失函数),通过调整权重参数 w 和偏置项 b 来实现。常用的方法是使用梯度下降算法或其变种来优化损失函数。
- 使用梯度下降法来训练w的值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









