







一,基础概念
散列表,英文名是hash table,又叫哈希表。
散列表通常使用顺序表来存储集合元素,集合元素以一种很分散的分布方式存储在顺序表中。
散列表是一个键值对(key-item)的组合,由键(key)和元素值(item)组成。键和它对应的元素值基于散列函数(hash function)进行一对一的映射,基于键查找到的元素值也可以称为散列值,查找公式:item = hash(key)。其中item可以是具体的值,也可以是具体的值对应的内存地址,也可以是链表或者链表的指针。
注意,有的教程里面喜欢把键值对称为(key, item),有的教程里面喜欢把键值对称为(index, value),其实是相同的意思。
散列表和数组相似的地方在于,都可以基于下标快速的访问数据,数组的下标是索引,散列表的下标是键。
散列表结构在生活中的抽象模型:一个班级所有学生的姓名和对应的学号。
二,散列表的图示结构
图一,key -> hash function -> hash table(key, item)

图二,哈希函数:item = key % 10

三,关于散列函数
最常见的散列函数:
除数留余法:item = (key + 5) % 10
例如:key=50, item = 5。key = 44, item = 9
好的散列函数具有以下特性:
函数的设计不过于复杂。
大部分情况下,使用相同的键只会查找到同一个值。
键和元素值要均匀随机分布。
基于键查找每个元素值的时间是近似的,而不是查找有的值耗时很长,查找有的值耗时很短。
发生散列冲突的概率极低。
四,散列冲突处理
所谓散列冲突,是指不同的键映射到了相同的散列值。
例如,对于”item = key % 10“的哈希函数,key为12或者22得到的散列值都是2。

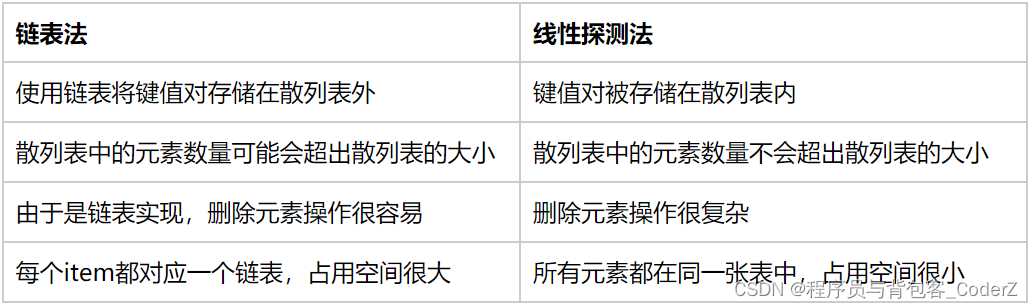
方式一,链表法
在链表法中,散列表中的每个key都映射到一个链表。因此,当两个key具有相同的item值时,这两个key都被添加到相同的链表中。
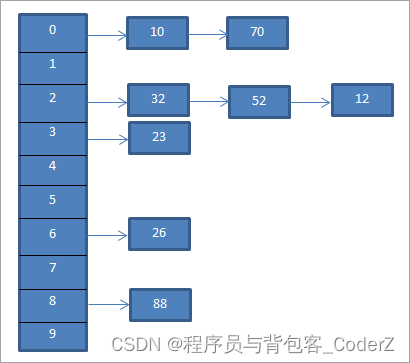
方式二,线性探测法
线性探测法是开放寻址法中的一种,所谓开放寻址,是指如果出现了散列冲突,在散列表中重新找一块儿没被使用过的内存地址,组成新的键值对。
具体操作
基于当前key生成的item值,没有被其他键值对占用时。则该item值可以和key组成键值对来放进散列表中。如果该item值对应了已有的其他的key,则将该key映射到散列表中还没被使用的下一个位置的item值,组成新的键值对来放进散列表中。
对于当前场景,具体步骤为
step.01: 采用item=key%10的方式来获得哈希值。
step.02: 发现采用item= key%10的方式获得的哈希值被别的key占用了,于是采用item=(key+1)%10的方式来获得新的哈希值。
step.03: 发现采用item=(key+1)%10的方式获得的新哈希值没被占用,就将此哈希值作为key的item,生成键值对放入到散列表。否则,继续采用item=(key+2)%10的方式来获得哈希值,以此类推。
例如
根据key=70获得的哈希值也是0。但是那个位置已经被(key=10, item=0)占用了。因此,根据线性探测法,我们将继续找到下一个位置 1。由于该位置暂时未被占用,我们依此生成(key=70, item=1)的键值对。

两种方式对比
五,散列表常见操作
a.插入元素
step1.计算key对应的散列值。
step2.如果散列值不在散列表中,则插入生成新的键值对。
step3.如果散列值已经在散列表中,则发生了散列冲突,return返回或覆盖旧散列值或调用专门处理散列冲突的函数。
b.查找元素
step1.计算key对应的散列值。
step2.如果散列值在散列表中,则查找成功,否则,查找失败。
c.删除元素
对于链接法,执行和链表一样的删除操作。
对于开放寻址法,将被删除节点置为“已删除”标记,查找时跳过此节点,插入时重新覆盖该节点。
六,代码实现
1.Python实现:
class HashTable:
def __init__(self, size):
self.size = size
self.hash_table = self.create_buckets()
def create_buckets(self):
#存储key用的桶结构
return [[] for _ in range(self.size)]
def insert_val(self, key, val):
hashed_key = hash(key) % self.size
bucket = self.hash_table[hashed_key]
found_key = False
for index, record in enumerate(bucket):
record_key, record_val = record
if record_key == key:
found_key = True
break
if found_key:
#遇到散列冲突时,直接覆盖了旧的值
bucket[index] = (key, val)
else:
bucket.append((key, val))
def get_val(self, key):
hashed_key = hash(key) % self.size
bucket = self.hash_table[hashed_key]
found_key = False
for index, record in enumerate(bucket):
record_key, record_val = record
if record_key == key:
found_key = True
break
if found_key:
return record_val
else:
return "No record found"
def delete_val(self, key):
hashed_key = hash(key) % self.size
bucket = self.hash_table[hashed_key]
found_key = False
for index, record in enumerate(bucket):
record_key, record_val = record
if record_key == key:
found_key = True
break
if found_key:
bucket.pop(index)
return
#魔法函数,遍历对象中的元素
def __str__(self):
return "".join(str(item) for item in self.hash_table)
hash_table = HashTable(5)
hash_table.insert_val('key_1', 'value_1')
hash_table.insert_val('key_2', 'value_2')
hash_table.insert_val('key_3', 'value_3')
print(hash_table)
print("the value of key_2 is: ", hash_table.get_val('key_2'))
hash_table.delete_val('key_3')
print(hash_table)运行结果:
[][][('key_3', 'value_3')][('key_1', 'value_1'), ('key_2', 'value_2')][]
the value of key_2 is: value_2
[][][][('key_1', 'value_1'), ('key_2', 'value_2')][]2.C++实现:
#include<iostream>
#include <list>
using namespace std;
class Hash
{
int BUCKET;
//每个散列值对应的链表
list<int>* table;
public:
Hash(int V);
//插入元素
void insertItem(int x);
//删除元素
void deleteItem(int key);
//散列函数
int hashFunction(int x) {
return (x % BUCKET);
}
void displayHash();
};
Hash::Hash(int b)
{
this->BUCKET = b;
table = new list<int>[BUCKET];
}
void Hash::insertItem(int key)
{
int value = hashFunction(key);
table[value].push_back(key);
}
void Hash::deleteItem(int key)
{
//找到key对应的散列值
int index = hashFunction(key);
list <int> ::iterator i;
for (i = table[index].begin();
i != table[index].end(); i++) {
if (*i == key)
break;
}
//删除key对应的元素
if (i != table[index].end())
table[index].erase(i);
}
void Hash::displayHash() {
for (int i = 0; i < BUCKET; i++) {
cout << i;
for (auto x : table[i])
cout << " --> " << x;
cout << endl;
}
}
int main()
{
int a[] = { 15, 11, 27, 8, 12 };
int n = sizeof(a) / sizeof(a[0]);
Hash h(7);
for (int i = 0; i < n; i++)
h.insertItem(a[i]);
h.deleteItem(12);
h.displayHash();
return 0;
}运行结果:
0
1 --> 15 --> 8
2
3
4 --> 11
5
6 --> 273.内置数据类型实现
C++内置数据类型:STL标准库中的unordered_map容器
Python内置数据类型:Python字典dict
Demo1:
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
{
unordered_map<string, double> umap = {
{"One", 1},
{"Two", 2},
{"Three", 3}
};
//insert value
umap["PI"] = 3.14;
umap["root2"] = 1.414;
umap.insert(make_pair("e", 2.718));
string key = "PI";
if (umap.find(key) == umap.end())
cout << key << " not found\n\n";
else
cout << "Found " << key << "\n\n";
unordered_map<string, double>::iterator itr;
cout << "\nAll Elements : \n";
for (itr = umap.begin();
itr != umap.end(); itr++)
{
cout << itr->first << " " <<
itr->second << endl;
}
}运行结果:
Found PI
All Elements :
One 1
Two 2
Three 3
PI 3.14
root2 1.414
e 2.718Demo2:
dict_obj = {"a":1, "b":2, "c":3, "d":4}
#打印字典
print(dict_obj['a'])
#增加键值对
dict_obj['e'] = 5
#修改字典的值
dict_obj['a'] = 21
#删除键值对
del dict_obj['d']
print(dict_obj)
#清空字典
dict_obj.clear()
print(dict_obj)运行结果:
1
{'a': 21, 'b': 2, 'c': 3, 'e': 5}
{}七,参考阅读
《Problem Solving with Algorithms and Data Structures Using Python, Second Edition》
https://www.softwaretestinghelp.com/hash-table-cpp-programs/
https://www.digitalocean.com/community/tutorials/hash-table-in-c-plus-plus
https://www.geeksforgeeks.org/hash-map-in-python/
https://scanftree.com/programs/cpp/c-program-for-hashing-with-chaining/















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









