








目录
一、零样本学习的革命性意义
1.1 传统AI识别系统的困境
在经典机器学习范式下,模型训练与推理存在以下典型问题:
| 传统方法痛点 | 具体表现 |
|---|---|
| 数据依赖性高 | 需要大量标注数据支持,标注成本呈指数级增长 |
| 模型泛化能力差 | 面对训练集未覆盖的类别时性能断崖式下降 |
| 系统维护成本高 | 新增类别需要重新收集数据并全量训练 |
| 知识迁移能力缺失 | 不同领域间的知识难以互通,每个任务都需要独立建模 |
1.2 零样本学习的突破性优势
零样本学习(Zero-Shot Learning)通过引入语义空间映射机制,实现了以下创新:

这种架构使得模型能够:
-
通过预训练获取通用音频理解能力
-
利用自然语言描述建立跨模态关联
-
实现未知类别的开放式推理
二、零样本音频分类核心技术解析
2.1 CLAP模型架构深度剖析
CLAP(Contrastive Language-Audio Pretraining)作为当前最先进的零样本音频分类模型,其核心结构如下:
2.1.1 音频编码器
-
采用HTS-AT(Hierarchical Token-Semantic Audio Transformer)
-
关键特征:
-
分层注意力机制
-
多尺度特征提取
-
频谱图切割技术
-
2.1.2 文本编码器
-
基于RoBERTa预训练模型
-
文本处理流程:
-
词嵌入层
-
12层Transformer编码器
-
池化输出
-
2.1.3 对比学习目标函数
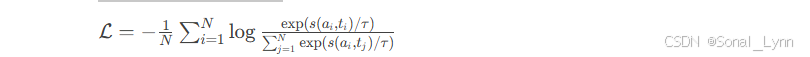
其中:
-
s(a,t)表示音频-文本相似度
-
τ为温度系数
-
N为批次大小
2.2 关键技术创新点
-
多模态对齐技术:通过对比学习实现跨模态特征对齐
-
层次化注意力:有效捕捉音频信号的时频特征
-
动态掩码策略:提升模型抗噪能力
-
混合训练策略:结合有监督与自监督学习
三、Pipeline实战:从入门到精通
3.1 环境配置与数据准备
# 环境安装
!pip install transformers datasets soundfile librosa -U
# 数据加载
from datasets import load_dataset
dataset = load_dataset("ashraq/esc50", split="train")
sample = dataset[0]
print(f"""
音频文件信息:
文件名: {sample['filename']}
采样率: {sample['audio']['sampling_rate']} Hz
持续时间: {len(sample['audio']['array'])/sample['audio']['sampling_rate']:.2f}秒
类别标签: {sample['category']}
""") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











