








目录
一、OpenAI Gym深度解析
1.1 环境体系架构全景
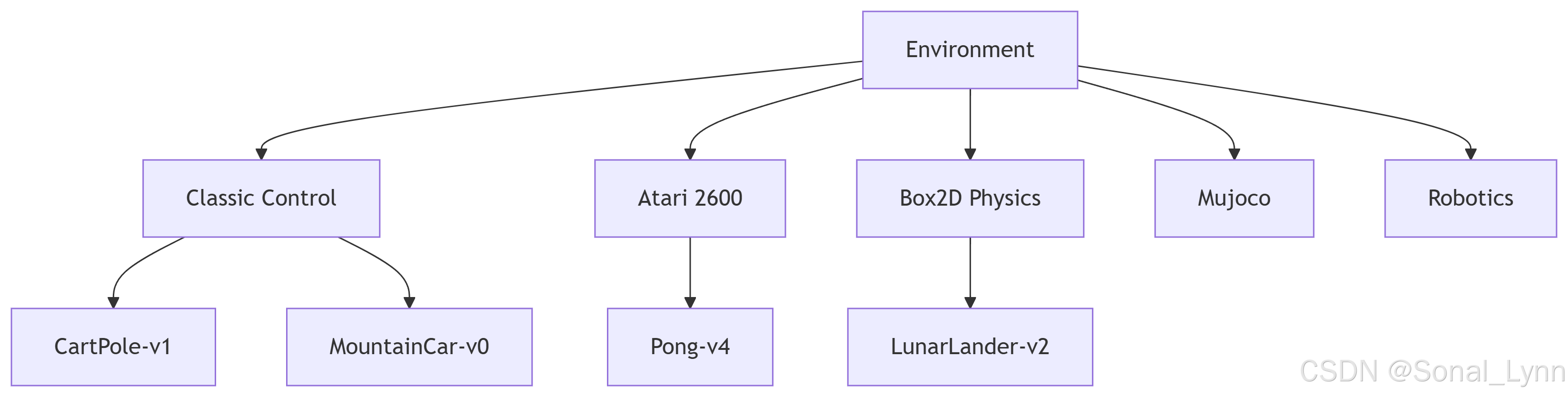
环境分类对比表
| 类别 | 典型环境 | 状态空间维度 | 动作类型 |
|---|---|---|---|
| Classic Control | CartPole-v1 | 4维连续 | 离散(2动作) |
| Box2D | LunarLanderContinuous-v2 | 8维连续 | 连续(2维) |
| Atari | Breakout-v4 | 210x160x3图像 | 离散(4动作) |
| Mujoco | Ant-v3 | 111维 | 连续(8维) |
1.2 核心API接口详解
import gym
# 环境生命周期管理
env = gym.make('CartPole-v1', render_mode='human') # 新增render_mode参数
obs, info = env.reset(seed=42) # 支持种子设置
done = False
total_reward = 0
while not done:
action = env.action_space.sample() # 随机采样动作
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
done = terminated or truncated # 新版终止条件分离
env.close()关键对象解析:
-
Observation Space:
Box(4,)表示4维连续状态 -
Action Space:
Discrete(2)表示2个离散动作 -
Reward Range:
(-inf, inf)奖励范围
二、CartPole环境数学建模
2.1 物理系统微分方程
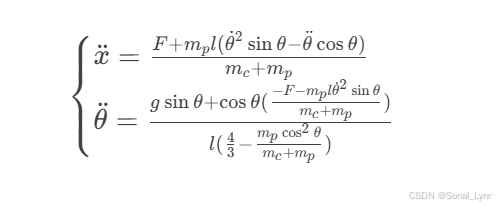
其中:
-
:小车质量(默认1.0kg)
-
:杆子质量(默认0.1kg)
-
:杆子半长(默认0.5m)
-
:重力加速度(9.8m/s²)
2.2 状态空间可视化
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 8))
plt.subplot(221)
plt.hist(observations[:,0], bins=50)
plt.title("Cart Position Distribution")
plt.subplot(222)
plt.scatter(observations[:,1], observations[:,3], c=rewards)
plt.title("Velocity vs Angular Velocity")
plt.colorbar(label='Reward')三、深度Q网络(DQN)实战
3.1 网络架构设计
import tensorflow as tf
from tensorflow.keras import layers
def build_dqn(input_shape, num_actions):
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.LayerNormalization(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2),
layers.Dense(num_actions)
])
return model
dqn_model = build_dqn((4,), 2)
dqn_model.summary()网络结构参数表:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| dense_1 (Dense) | (None, 128) | 640 |
| layer_normalization | (None, 128) | 256 |
| dense_2 (Dense) | (None, 64) | 8256 |
| dropout (Dropout) | (None, 64) | 0 |
| dense_3 (Dense) | (None, 2) | 130 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











