








目录
一、强化学习的数学本质与核心框架
1.1 马尔可夫决策过程(MDP)的数学建模
强化学习的理论基础建立在五元组MDP之上:(S,A,P,R,γ)
关键要素解析表
| 符号 | 含义 | 典型示例 |
|---|---|---|
| S | 状态空间 | 棋盘位置坐标 |
| A | 动作空间 | 机器人关节运动角度 |
| P | 状态转移概率 | 90%概率正确执行指令 |
| R | 即时奖励函数 | 得分+1,能耗-0.2 |
| γ | 折扣因子(0.9-0.99) | 未来奖励的衰减系数 |
1.2 价值函数与策略的深层关系
贝尔曼最优方程:
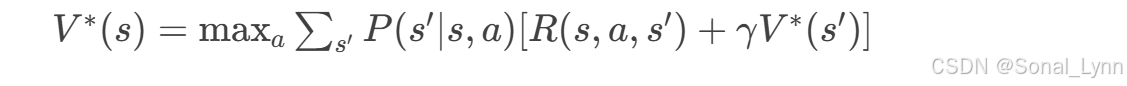
二、奖励工程:智能体的价值导向系统
2.1 奖励函数设计的艺术与科学
典型奖励结构案例对比:
| 场景 | 正奖励项 | 负奖励项 | 设计要点 |
|---|---|---|---|
| 自动驾驶 | 车道保持+0.1/帧 | 偏离车道-1.0 | 平滑驾驶行为 |
| 围棋AI | 占领区域+0.01/格 | 无效落子-0.5 | 长期战略平衡 |
| 工业机器人 | 完成装配+5.0 | 碰撞检测-10.0 | 安全优先原则 |
| 推荐系统 | 用户点击+0.2 | 用户跳过-0.1 | 实时反馈机制 |
2.2 稀疏奖励问题的突破性解决方案
技术演进路线图:

分层奖励设计实例:
class RewardShaper:
def __init__(self):
self.base_reward = 0
self.shaping_factors = {
'distance': -0.01, # 距离目标每米奖励
'energy': -0.005, # 每焦耳能耗惩罚
'safety': -2.0 # 危险动作惩罚
}
def calculate(self, state, act 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











