






阿里新出的AI"小钢炮"——325亿参数的QwQ-32B凭啥吊打行业顶流DeepSeek?
今天凌晨,阿里最新开源QwQ-32B模型,别看它参数只有325亿(相当于普通手机内存大小),但性能直接对标行业顶流DeepSeek-R1(6710亿参数)。
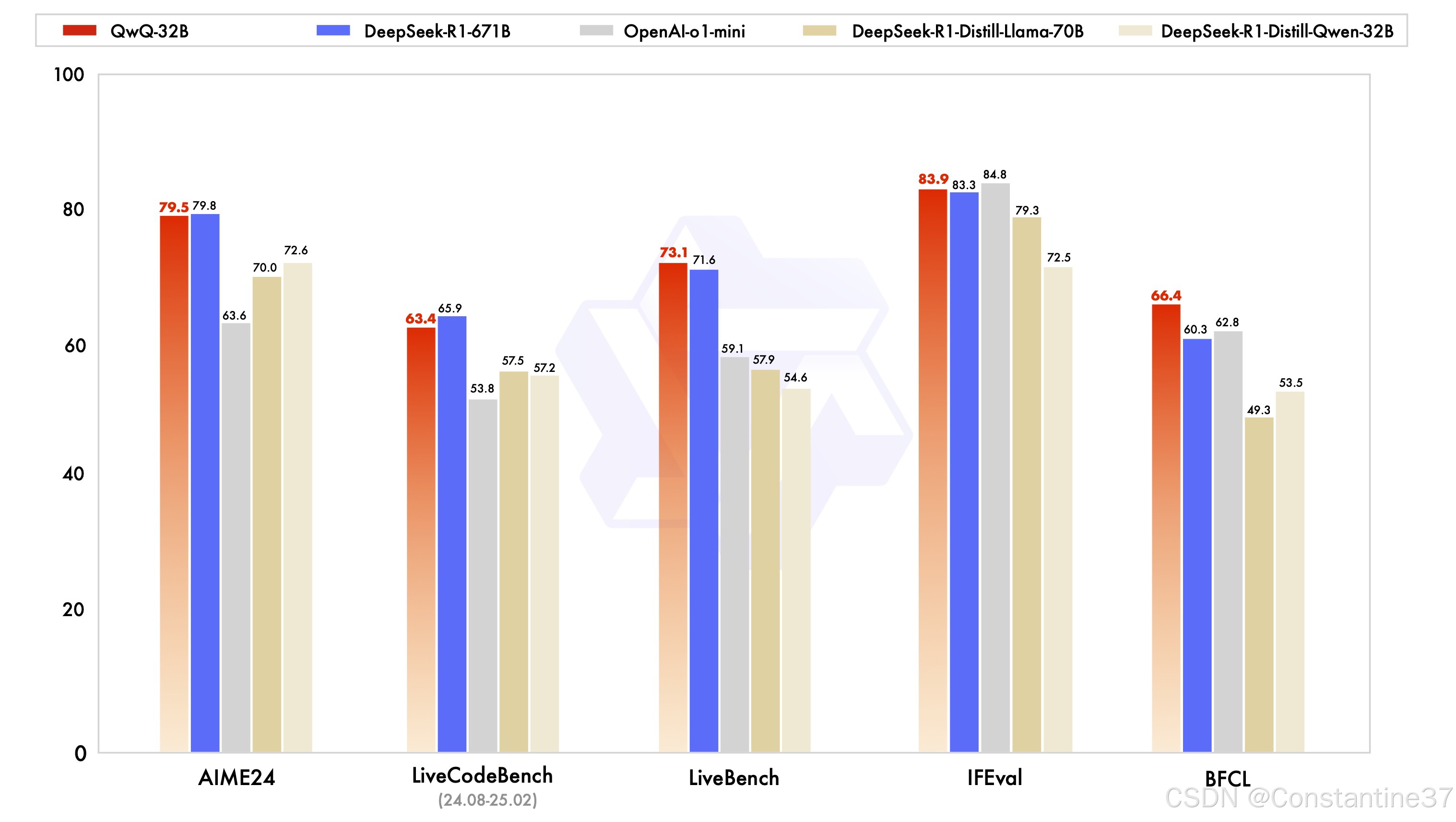
性能强劲
QwQ-32B在数学推理、代码生成等核心能力上,直接对标6710亿参数的DeepSeek-R1满血版。
这种“小身材、高能力”的特性,得益于两阶段强化学习训练:先通过冷启动数据建立基础推理逻辑,再针对数学/编程/通用任务进行动态优化,最终实现多步问题解决能力的跃升。
成本碾压
显存需求从行业顶流的1400G直接砍到120G,普通消费级显卡(如RTX 4090)就能跑
部署成本仅为同类模型的1/20,企业不用砸钱买专业设备。
普通用户如何使用QwQ-32B?
若想随时随地与QwQ-32B交互,推荐安装DeepSider浏览器插件。
DeepSider支持在网页侧边栏直接开启对话界面,无需切换应用即可调用模型能力——无论是调试代码、解答数学题,还是生成创意文案,都能通过浏览器实现无缝衔接。
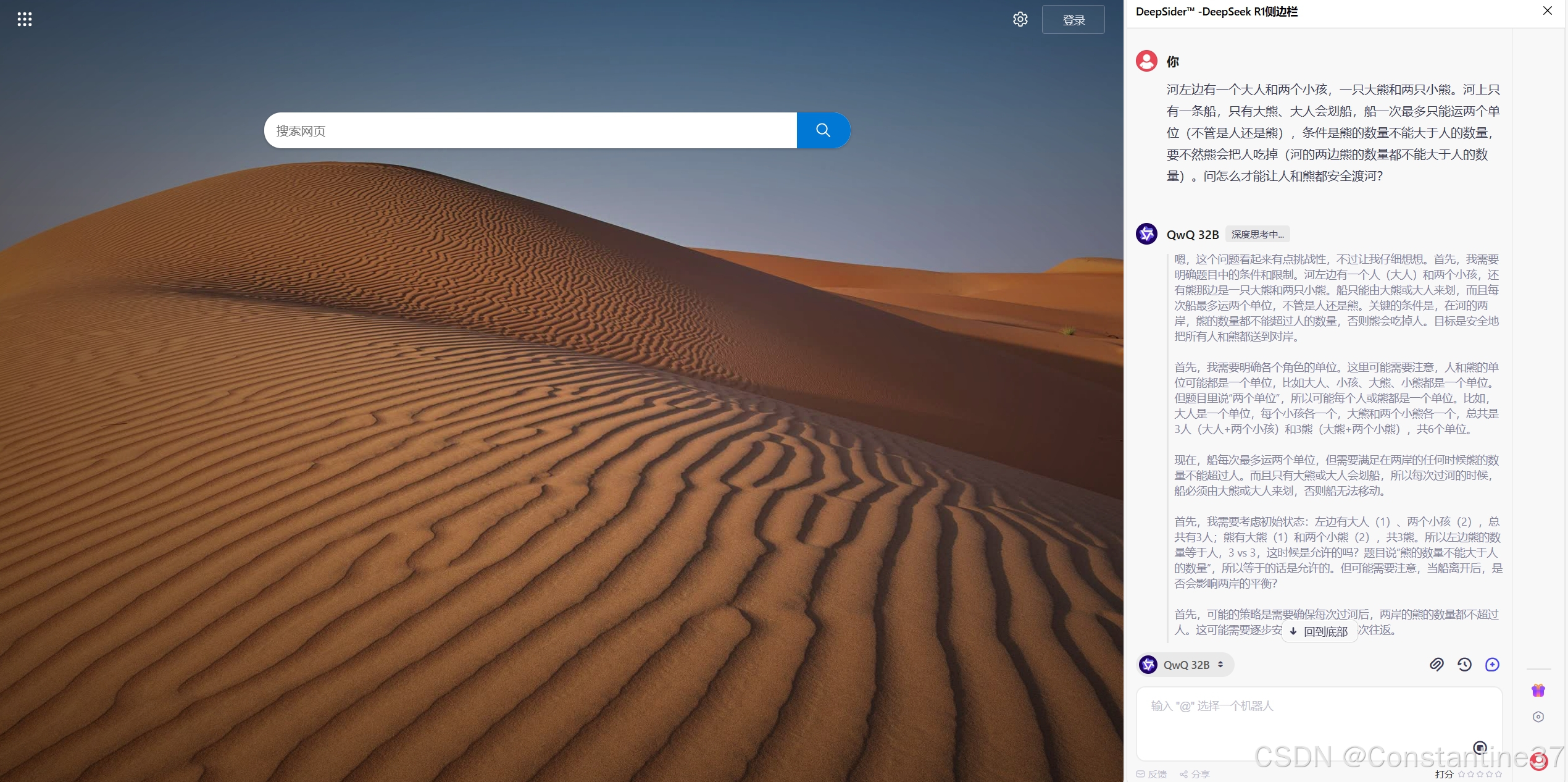
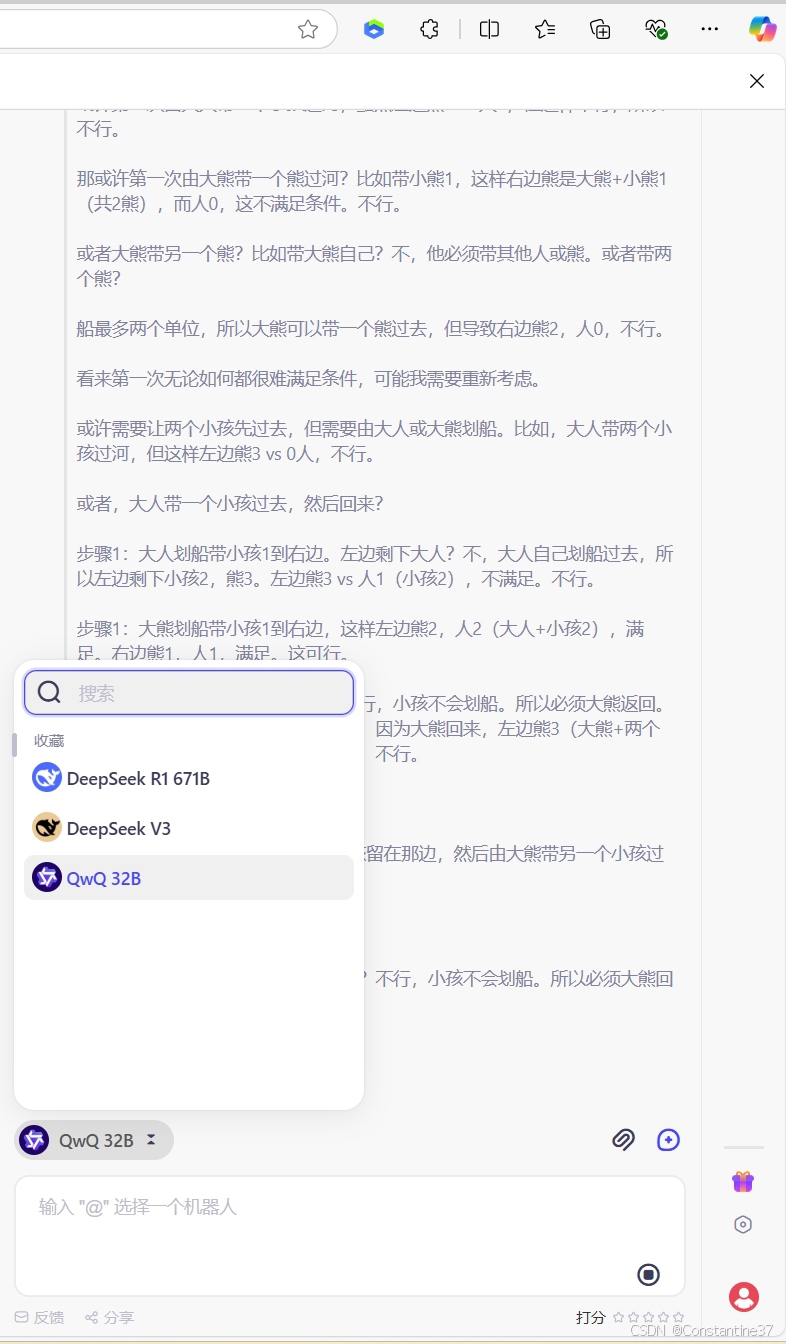
此外,DeepSider还支持DeepSeek-R1满血版模型,以及DeepSeek-V3,刚好可以与QwQ-32B进行对比测试。
DeepSider插件安装方法
Chrome:访问Chrome Web Store搜索“DeepSider”,点击“添加”
Edge:因商店版本更新较慢,建议在deepsider.ai网站下载离线版安装文件,拖拽到浏览器扩展管理页,完成安装

















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









