






本文翻译自 Convolutional Neural Networks(CNNs / ConvNets),更多内容请访问:http://cs231n.github.io/。
卷积神经网络非常类似于普通的神经网络:它们都是由具有可以学习的权重和偏置的神经元组成。每一个神经元接收一些输入,然后进行点积和可选的非线性运算。而整个网络仍然表示一个可微的得分函数:从原始的图像像素映射到类得分。在最后一层(全连接层)也有损失函数(例如 SVM / Softmax),而且训练普通神经网络的已有技巧 / 技术都可以应用。
然而差别在哪里呢?卷积网络结构具有特殊的图像输入,这个显式的输入假设使得网络结构具有一些特定的性质。这些性质使得前向函数能够高效的实现,并且极大的减少网络的参数个数。
结构概览
回顾:普通神经网络。神经网络接收一个输入(向量),然后通过一系列的隐藏层对输入进行变换。每一个隐藏层都由神经元的集合组成,每一个神经元与前一层的所有神经元连接,而同一层的神经元之间完全独立,也不共享任何连接。最后的全连接层称为“输出层”,在分类情形下它表示类得分。
普通神经网络不能适用所有图像。CIFAR-10 数据集中的图像大小只有 32x32x3 (宽 32,高 32,3 个颜色通道),因此一个普通神经网络的第一个隐藏层的一个全连接神经元的参数个数是 32*32* 3 = 3072。这样的大小看起来好像很容易处理,但显然全连接结构不能扩展到大图像。例如,一张更可观的图像,它的大小为 200x200x3,那么一个神经元的就有 200*200*3 = 120,000 个参数。而且,我们几乎总是需要很多这样的神经元,因此参数合在一起会快速的增长。很明显,这样的全连接是浪费的,而且大量的参数会很快的导致过拟合。
神经元的 3D 方体(?,volume)。卷积神经网络充分的利用了输入是图像这一事实,而且以一种更有意义的方式来限制它们的结构。特别的,不像普通神经网络,卷积网络中的层以 3 维(宽、高、深度,这里的深度不是指整个网络的深度——网络中所有层的个数,而是指激活方体的第三个维度)的方式来排列神经元。例如,CIFAR-10 中的图像是维数为 32x32x3(宽、高、深度)的激活输入方体。我们马上就会看到,卷积网络层中的神经元不是以全连接的方式连接到前一层的所有神经元,而是只与一个小局部相连。而且,依据卷积网络结构,用于 CIFAR-10 的卷积网络的最后的输出层的维数是 1x1x10,就把整张图像简化成一个沿着深度方向的类得分向量。下图是两种网络的一个可视化:
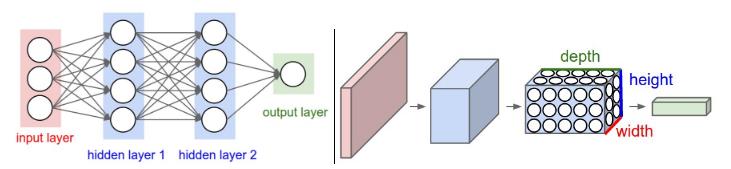
左图:普通的 3 层神经网络。右图:卷积网络,同一层的神经元使用三维(宽、高、深度)来可视化。卷积网络的每一层把神经元的激活的 3D 的输入方体变换为 3D 的输出方体。在这个例子里,红色的输入层保存图像,所以它的宽度和高度是图像的维数,而深度是 3 (红、绿、蓝通道)。
卷积网络由层组成。每一层都有一个 API:它把 3D 的输入方体通过一个可微函数(参数可有可无)变成一个 3D 的输出方体。
组成卷积网络的层
正如我们在前面说的,一个简单的卷积网络是层的一个序列,每一个层通过一个可微函数把一个激活方体变成另一个。我们使用三种主要类型的层:卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-Connected Layer)来建立卷积网络结构。我们将这三种类型的层堆叠起来形成整个卷积网络的结构(architecture)。
结构例子:概览。我们会在以后更详细的描述卷积网络,但一个用于 CIFAR-10 分类的简单卷积网络具有结构 [INPUT - CONV - RELU - POOL - FC]。更详细的:
- INPUT [32x32x3] 保留图像的原始像素值,这里的情形是宽 32,高 32,和具有 R,G,B 三个颜色通道的图像。
- CONV 层计算与输入局部连接的神经元的输出,每一个神经元计算它们的权重与局部连接的输入单元的权重的点积。如果我们使用 12 个过滤器,则得到 [32x32x12] 的单元。
- RELU 层逐元素的使用激活函数 max{0, x}。它保持单元的大小 [32x32x12] 不变。
- POOL 层沿着空间维度(宽、高)进行降采样运算,得到如 [16x16x12] 的单元。
- FC(fully-connected)层计算类得分,得到的单元大小为 [1x1x10],其中 10 个数中的每一个对应到一个类得分(CIFAR-10 总共 10 个类别)。顾名思义,与普通神经网络一样,这个层的每一个神经元都与前一层的所有神经元连接。
使用这种方法,卷积网络一层一层的把原始图像的原始像素值变换成最后的类得分。注意到一些层包含参数,而另一些层没有。特别的,CONV / FC 层进行的变换不仅是输入方体的激活的函数,也是神经元的参数(权重和偏置)的函数。另一方面,RELU / POOL 层实现固定的函数。CONV / FC 层的参数通过梯度下降算法训练,使得卷积网络计算的类得分和训练集中的每一张图像的类标号一致。
综合来说:
- 卷积网络结构是把图像方体变成输出方体(如保存类得分)的变换的层列表的最简单的情形
- 只有几种不同类型的层而已(例如,当前 CONV / FC / RELU / POOL 最流行)
- 每一层都接收 3D 的输入方体,然后通过一个可微函数把它变成 3D 输出方体
- 每一层可能有参数,也可能没有(例如,CONV / FC 层有,而 RELU / POOL 层没有)
- 每一层可能有额外的超参数,也可能没有(例如,CONV / FC / POOL 有,而 RELU 没有)
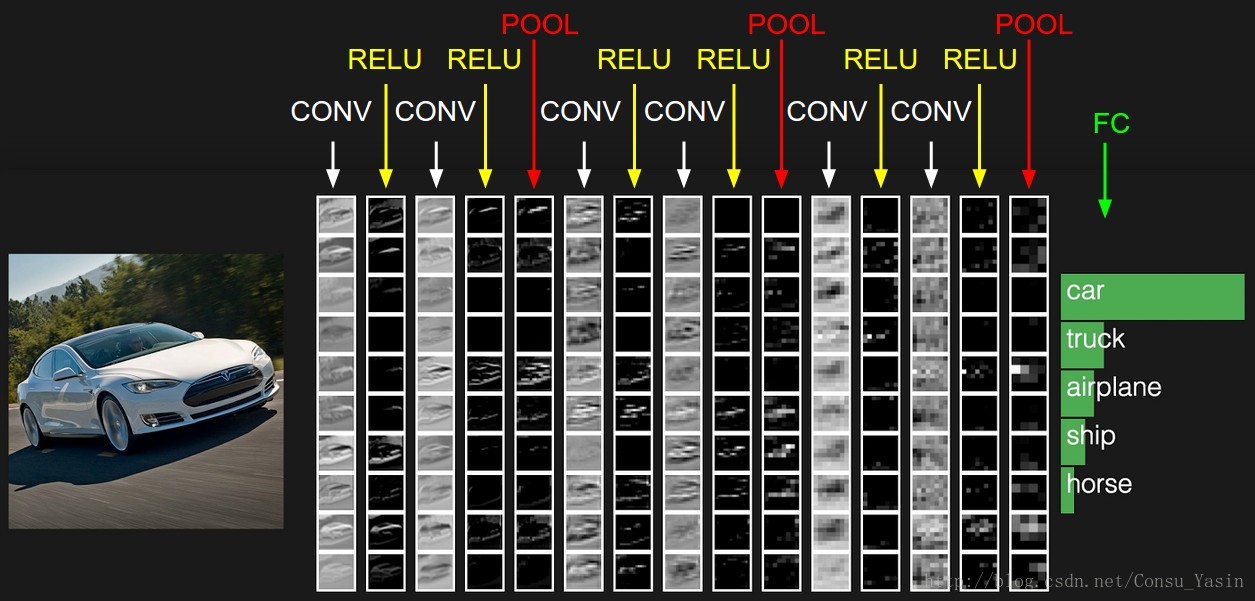
一个样例卷机网络的激活。初始的方体保存原始图像像素(左边),而最后的方体保存类得分(右边)。沿着处理路径的每一个激活的方体由列来显示。由于很难可视化 3D 方体,所以通过行来展示每一个方体的切片。最后一层的方体保存每一个类的得分,这里我们仅列出了排名前 5 的得分,及它们的标签。访问网站查看完整的 web-based demo。这里展示的是小型VGGNet(后面会讨论)的结构。
现在我们来描述特定层的超参数和它们连接的细节。
卷积层
卷积层(convolutional layer,Conv layer)是卷积网络的核心模块,它对卷积网络的计算性能提升最多。
直观概览。首先来看看没有脑 / 神经元类比的卷积层的计算。它的参数由可学习的过滤器组成。每一个过滤器都是一个小的沿着宽和高方向的空间区块,但也可以扩展到输入方体的整个深度。例如,卷积网络的第一层的一个典型的过滤器具有 5x5x3 的大小(也就是宽和高 5 个像素,而 3 是因为图像有 3 个颜色通道)。在前向传播阶段,我们沿着输入方体的宽和高滑动(更精确的,卷积)每一个过滤器,在每一个位置计算输入和过滤器元素之间的点积。这将产生一个 2 维的激活映射(activation map),它是对过滤器在每一个空间位置的响应。直观的,网络学习的过滤器会在看到某些类型的可见特征(例如,网络第一层的某些方向的边缘,或者某些颜色的斑块,或网络上层的最终的蜂窝似或轮似的模式)的时候激活。在每一个 CONV 层我们有过滤器的一个集合,它们每一个都产生一个分离的 2 维激活映射。沿着深度维数方向把这些激活映射堆叠起来就产生了输出方体。
脑观点。如果从脑 / 神经元的类比来看,3D 输出方体的每一个元素都可以解释成神经元的输出,这些神经元只依赖输入的一个小区域,而且它们与左右空间的神经元共享参数(因为它们都使用相同的过滤器)。现在我们来阐述神经元连接的细节,它们的空间排列,以及它们的参数共享方式。
局部连接。当我们处理高维输入(如图像)的时候,把神经元与它前一层的所有神经元连接是不现实的。实际上,我们只把它和前一层的一个小区域相连。这个连接的空间范围是称为神经元的感受野(receptive field)的一个超参数,它等价于过滤器的大小。沿着深度轴的连接范围总是等于输入方体的深度。需要再次强调的是我们在处理空间维度(宽和高)和深度维度的时候是不对称的:连接在沿着输入方体的空间(宽和高)方向是局部的,而在深度方向则总是等于整个深度。
例1。假设输入方体大小为 [32x32x3](例如一张 RGB CIFAR-10 图像)。如果感受野(或过滤器大小)为 5x5,则卷积层的每一个神经元连接到输入方体的 [5x5x3] 的区域,总共有 5*5*3 = 75 个权重(再加 1 个偏置参数)。注意,沿着深度方向的连接范围必须是 3,因为它就是输入方体的深度。
例2。假设输入方体的大小是 [16x16x20]。则使用 3x3 大小的感受野,卷积层的每一个神经元与输入方体有 3*3*20 = 180 个连接。再次注意,连接在空间上是局部的(如 3x3),但在输入深度上是整体的。
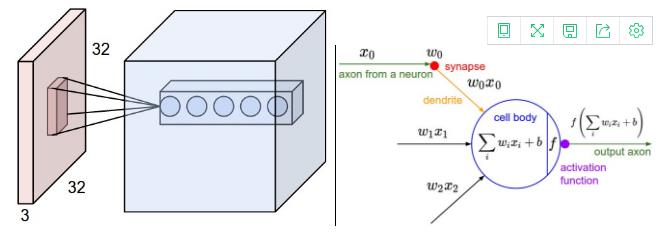
左图:一个样例输入方体(红色,例如一张 32x32x3 的 CIFAR-10 图像),和一个样例第一个卷积层的神经元方体。卷积层的每一个神经元在空间上都连接到输入方体的一个局部,但要连接整个深度(例如,所有的颜色通道)。注意,沿着深度有多个神经元(如图片上有 5 个),每一个都连接到输入的相同区域(见下文 depth column 的讨论)。右图:与普通神经网络的神经元一样:它们仍然要计算权重与输入的点积,然后再进行非线性激活,只是它们的连接被限制到局部空间。
空间排列。我们已经解释了卷积层的每一个神经元与输入方体的连接,但我们还没有讨论输出方体中神经元的个数以及它们的排列方式。有三个超参数控制着输出方体的大小:深度(depth),步幅(stride)和 0-填充(zero-padding)。我们分别讨论如下:
- 首先,输出方体的深度是一个超参数:它对应到我们使用的过滤器的个数,每一个过滤器学习输入的不同特征。例如,第一个卷积层把原始图像作为输入,则沿着深度维数的不同神经元会在不同方向边缘或颜色块出现时激活。我们把连接到输入的相同区域的神经元集合称为 depth column(某些人更倾向于术语 fibre)(原文:We will refer to a set of neuros that are all looking at the same region of the input as a depth column (some people also prefer the term fibre))。
- 其次,我们必须指定过滤器滑动的步幅。当步幅为 1 时,过滤器一次移动一个像素。当步幅为 2(或者,不同寻常的 3 或更大,这些实际很少使用) 时,过滤器一次跳动两个像素。这将会产生在空间上更小的输出方体。
- 我们将在后面看到,往输入方体的边界填充 0 有时是方便的。这种 0-填充的大小是一个超参数。0-填充的一个非常好的特性是它可以让我们控制输出方体的空间大小(大部分情况,如我们将看到的,我们使用它来保持输出方体与输入方体相同的空间大小,即具有相同的宽和高)。
-
输出方体的大小可以通过输入方体的大小(W),卷积层神经元的感受野的大小(F),使用的过滤器的步幅(S),以及边界 0-填充的量(P)的一个函数来计算。你可以确认一下,计算输出神经元个数的正确公式是 (W - F + 2 P) / S + 1。例如,对于 7x7 的输入,步幅为 1 的 3x3 过滤器,以及 0 个填充,我们得到 5x5 的输出。如果步幅为 2,则得到 3x3 的输出。让我们来看一个更图形化的例子:

空间排列的说明。在这个例子中,空间维数只有一个(x-轴),一个神经元的感受野的大小为 F = 3,输入大小为 W = 5,0-填充个数 P = 1。左图:步幅 S = 1,从而输出大小为 (5 - 3 + 2) / 1 + 1 = 5。右图:步幅 S = 2,输出大小为 (5 - 3 + 2) / 2 + 1 = 3。注意,步幅 S = 3 不能用,因为它不匹配方体的大小。用方程的术语来说,这可由 (5 - 3 + 2) = 4 不被 3 整除来确定。
这个例子中,神经元的权重是 [1, 0, -1](图中最右侧),偏置是 0。这些权重被所有黄色的神经元共享(见下文参数共享)。
使用 0-填充。注意到在上面例子的左图,输入和输出的维数都是 5。这之所以成立,是因为感受野是 3 而我们使用了 1 的 0-填充。如果没有使用 0-填充,则输出的空间维数只有 3。一般的,如果步幅 S = 1,则设置 0-填充 P = (F - 1) / 2 就能确保输入方体和输出方体具有相同的空间维数。使用这种方式的 0-填充非常常见,我们在进一步讲卷积结构的时候会讨论这样做的充足理由。
步幅的限制。再次注意到空间排列超参数是两两相互制约的。例如,当输入大小是 W = 10 时,如果没有 0-填充 P = 0,并且过滤器的大小 F = 3,则不能使用步幅 S = 2,因为 (W - F + 2 P) / S + 1 = (10 - 3 + 0) / 2 + 1 = 4.5,也就是说,不是一个整数,这意味着神经元不是整齐和对称的与输入做卷积。因此,超参数这样设置是无效的,而且一个卷积库(ConvNet library)会抛出一个例外,或者使用 0 的 0-填充,或者截断输入,或其它方式来匹配这些超参数。我们将在卷积网络结构那一节看到,合适的设置卷积网络的大小使得所有的维数都匹配确实令人头痛,而这是 0-填充以及其它一些设计指导会帮我们显著缓解的。
现实例子。Krizhevsky 等人的结构赢得了 2012 年的 ImageNet 比赛,它接受的图像大小是 [227x227x3]。在第一个卷积层,神经元的感受野大小 F = 11,步幅 S = 4,0-填充 P = 0。因为 (227 - 11) / 4 + 1 = 55,以及卷积层具有深度 K = 96,所以卷积层的输出方体大小为 [55x55x96]。这个有 55*55*96 个神经元的方体中的每一个神经元都与输入方体的大小为 [11x11x3] 的区域相连。另外,每一个深度列(depth column)中的 96 个神经元都连接到输入方体的相同 [11x11x3] 的区域,当然它们的权重不一样。有趣的是,他们的论文中说输入图像大小是 224x224,这显然是不正确的,因为 (224 - 11) / 4 + 1 并不是一个整数。这在卷积网络的历史中困扰了很多人,而且很少有人知道发生了什么。我们自己最好的猜测是 Alex 使用了 3 个额外像素的 0-填充,而他没有在论文中指出。
参数共享。卷积层中使用参数共享方式来控制参数个数。使用上面现实的例子,我们已经知道在第一个卷积层中有 55*55*96 = 290,400 个神经元,每一个神经元都有 11*11*3 = 363 个权重和 1 个偏置。加起来,在第一个卷积层就有 290400*363 =105,705,600 个参数。显然,这个数非常大。
一个被证明能够极大的减少参数个数的合理的假设是:如果一个特征对某个空间位置 (x,y)的计算是有用的,则它对不同位置 (x2,y2)的计算也是有用的。换句话说,如果记一个深度的二维切片为 depth slice (例如,一个大小为 [55x55x96] 的方体有 96 个 depth slice,每一个大小为 [55x55]),我们将限制每一个 depth slice,使得它的所有神经元都使用相同的权重和偏置。使用这种参数共享模式,我们的例子的第一个卷积层只有 96 个权重集(每一个 depth slice 对应一个),因此共有 96*11*11*3 = 34,848 个权重,或者 34,944 个参数(+96 个偏置)。也就是,每一个 depth slice 中的所有 55*55 个神经元都使用相同的参数。在实际的反向传播过程中,方体中的每一个神经元都会对参数求梯度,但每个 depth slice 中的这些梯度都会加到一起,而且权重也只更新一次。
注意到,如果一个 depth slice 中的所有神经元都使用相同的权重向量,则卷积层在前向传播过程时,每个 depth slice 计算神经元的权重与输入方体的卷积(因此得名:卷积层)。这也是为什么通常把权重集称为过滤器(filter)(或核,kernel),它与输入进行卷积。

学到的过滤器的例子(Krizhevsky et al)。96 个过滤器中的每一个都具有大小 [11x11x3],而且都被每一个 depth slice 中的 55*55 个神经元共享。注意到参数共享这个假设是合理的:如果在图像中某个位置检测到一个水平边缘是重要的,则由于图像的平移不变结构,直观的说,在其他位置也是有用的。从而,不需要在卷积层的输出方体中的 55*55 个位置中的每一个都重新去学习检测水平边缘。
注意,有时参数共享假设可能没有意义。特别是如果卷积网络的输入图像具有特定的中心结构这种情况更是如此,在这里,我们期望,比如,学到图像的一侧相对于另一侧完全不同的特征。一个实际例子是,当输入是居于图像中心的人脸时。你可能期望在不同的空间位置学习到不同的眼睛或头发特征。这种情况通常会放松参数共享模式,取而代之的是局部连接层(Locally-Connected Layer)。
Numpy 例子。为了让讨论变得更精确,我们把相同的想法用代码和特定的例子来表达。假设输入方体是一个 numpy 数组 X。则:
- 在位置
(x, y)中 depth column(或 fibre)是激活 X[x, y, :]。 - 在深度
d的 depth slice,或等价的,activation map 是激活 X[:, :, d]。
卷积层例子。假设输入方体具有形状 X.shape: (11, 11, 4)。再假设我们不使用 0-填充(P = 0),过滤器大小 F = 5,步幅 S = 2。则输出方体的的空间大小是 (11 - 5) / 2 + 1 = 4,即宽和高是 4。输出方体的激活映射(称它为 V)看起来如下(在这个例子中只有其中的一些元素被计算):
V[0, 0, 0] = np.sum(X[:5, :5, :] * W0) + b0V[1, 0, 0] = np.sum(X[2:7, :5, :] * W0) + b0V[2, 0, 0] = np.sum(X[4:9, :5, :] * W0) + b0V[3, 0, 0] = np.sum(X[6:11, :5, :] * W0) + b0
记住在 numpy 中, 上面的运算符 * 指数组中的元素级乘法。同时要注意神经元的权重向量是 W0,而 b0 是偏置。这里,W0 假设具有形状 W0.shape: (5, 5, 4),因为过滤器大小是 5 以及输入方体的深度是 4。而且在每一个点,我们像通常的神经网络一样计算点积。另外,我们使用相同的权重和偏置(由于参数共享),同时沿着宽度方向的维数以 2 的步长(也就是步幅)增长。要构造输出方体的第二个激活映射,我们有:
V[0, 0, 1] = np.sum(X[:5, :5, :] * W1) + b1V[1, 0, 1] = np.sum(X[2:7, :5, :] * W1) + b1V[2, 0, 1] = np.sum(X[4:9, :5, :] * W1) + b1V[3, 0, 1] = np.sum(X[6:11, :5, :] * W1) + b1V[0, 1, 1] = np.sum(X[:5, 2:7, :] * W1) + b1(沿着 y 方向的例子)V[2, 3, 1] = np.sum(X[4:9, 6:11, :] * W1) + b1(沿着两个方向的例子)
这里我们看到,V 的深度维数的下标是 1,因为我们计算的是第二个激活映射,而且现在使用的参数(W1)也不同。为了简单起见,卷积层的输出数组 V 的其它部分并没有全部计算。另外,这些激活映射之后通常都会使用像 ReLU 这样的激活函数,虽然这里并没有演示。
总结。总而言之,卷积层:
- 接收一个大小为 W1×H1×D1 方体
- 需要 4 个超参数:
- 滤波器个数 K ,
- 滤波器大小
F , - 步幅 S ,
- 0-填充数量
P
- 产生一个大小为 W2×H2×D2 的方体:
- W2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









