






【1】标签页的概述
作为StableDiffusion的标签页,也是这款模型最主要的功能块的展示。其中包括了:文生图、图生图、附加功能、图片信息、训练、Dreambooth、设置和扩展等几个主要功能。其他的,如:SadTalk、Civitai助手、InfiiteZoom、openpossEdit等,都是之后学习后根据自己的使用情况陆续加载进去的。之后在本文中会重点介绍几个标签页的使用。

【2】不同插件不同的栏目调用和存放路径
在我们的Stable
Diffusion的界面中,我们后面陆续添加的插件安装存放路径,一般在SD的安装目录下的“extensions”文件夹中,并以文件夹的形式存在。
这个栏目中,很多我们安装了的插件的标签页,比如。。
当然,并不是所有装在插件目录(stablediffusion安装目录下的extensions目录)下的插件都在此栏中调用,比如controlnet的插件调用页就在主页面的下端一栏中。

还有的插件虽然是在脚本栏中调用,但也是放在extensions目录中,但大多数脚本文件是放在stablediffusion目录的scrip目录下。
一般来说,脚本文件都比较简单,就一个以.py为后缀名的以单个文件 形式在其目录下;而放在extensions目录下的一般都是以文件夹的形式
存在在其目录下。
【3】图生图的使用介绍
子标签页-图生图/绘图
图生图作为Stable Diffusion中与文生图一样,都是很经常用到的强大绘图方式。
通过图生图的子标签页,我们可以通过多种方式进行图生图的操作。
其中最直接的就是用现有的图进行重新生成图像。
我们可以将我们的原图置入框中,点击反向推辞按钮后,软件会自动识别图像信息到提示词栏中。

图生图/绘图
打好提示词后。将图像置入,并调整重绘幅度。即可生成。

局部重绘
用图像框提供的画笔,将要重绘的部分涂抹为黑块即可,不一定要涂抹得非常精确。

局部重绘(上传蒙版)
我们还可以调用在PS中获得的与主体同样大小的蒙版进行控制我们不想要改变的图像信息内容。再结合重绘幅度这个参数进行精准控制重绘图像。

【4】图片信息页
用于置入由StableDiffusion生成的图片后,可以获得该图像的具体信息,包括正向提词和反向提词内容,以及各参数的设置和lora调用的名称以及基础模型的名称等等。

【5】模型合并页
这个页面的功能,可以将我们所用的模型进行合并处理后使用。特别是对于做“inpaint”的时候,很多基础模型是不带inpaint功能的,我们一般调用的是官方SD15的inpaint模型来用。但如果追求更好的效果,就可以用此功能。通过这个页面,将inpaint的官方模型(我们暂且称为A),与我们习惯用的基础模型(我们暂且称为B),与之合并后,再减去官方的这个版本的非inpaint功能的基础模型(我们暂且称为C),从而生成一个新的带有inpaint功能的我们习惯用的新模型。

当然,我们还可以再这个页面,进行基础模型与VAE模型的合并,但个人认为倒非必要,毕竟VAE模型我们现在可以另外挂载着使用。

【6】OpenPoss Editor页
这个标签页也是在我们用到图生图和controlnet插件时候,经常需要用的页面,在这里我们可以很方便地预先将我们所要绘制的人物姿势摆好后,置入图生图的页面的controlnet栏中,作为openposs这个预处理器的结果,提供给openposs的模型使用。
例如,我们要给一件衣服绘制一个模特,那么就可以先将模特的造型动作在OpenPoss
Editor页中,配合衣服摆放好后,导出poss图片,用在controlnet的图框中来控制人物的动作造型。


【7】扩展页
扩展页是提供我们安装各种插件的页面。在这个页面中可以对已有的插件进行是否有更新的检查(已安装的子标签页),还可以通过“可用”或“从网址安装”子标签页,对自己想要用的插件进行安装(当然这只是安装插件的4种方法中的其中2种,还有就是直接去GitHub上下载压缩包解压到extensions目录下,再就是在GitHub上复制到克隆地址后,到extensions目录下运行“git
clone xxxx(复制的克隆地址)”)。

AI绘画SD整合包、各种模型插件、提示词、GPT人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

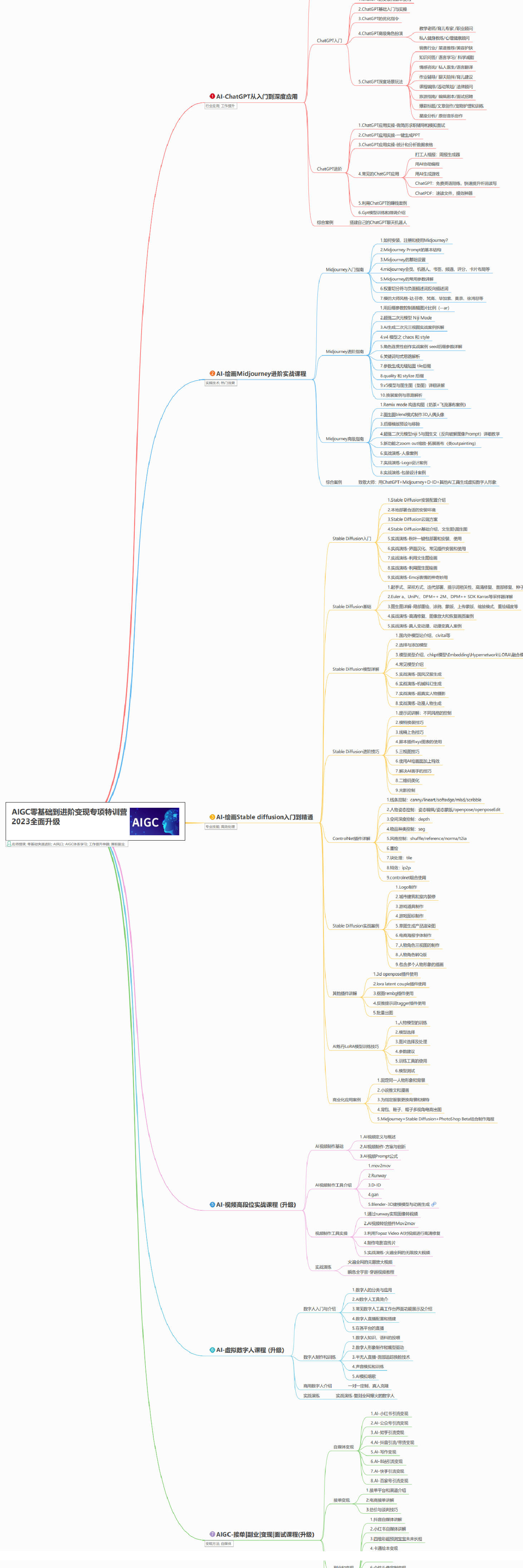
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!

















 3596
3596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









