










参考:
- B站教学视频【:AI绘画】新手向!Lora训练!训练集准备、tag心得、批量编辑、正则化准备】
- 官方教程:https://github.com/darkstorm2150/sd-scripts/blob/main/docs/train_README-en.md#automatic-captioning
2025.02.20最新教程——【FLUX微调+风格训练】从零免费训练自定义图像风格
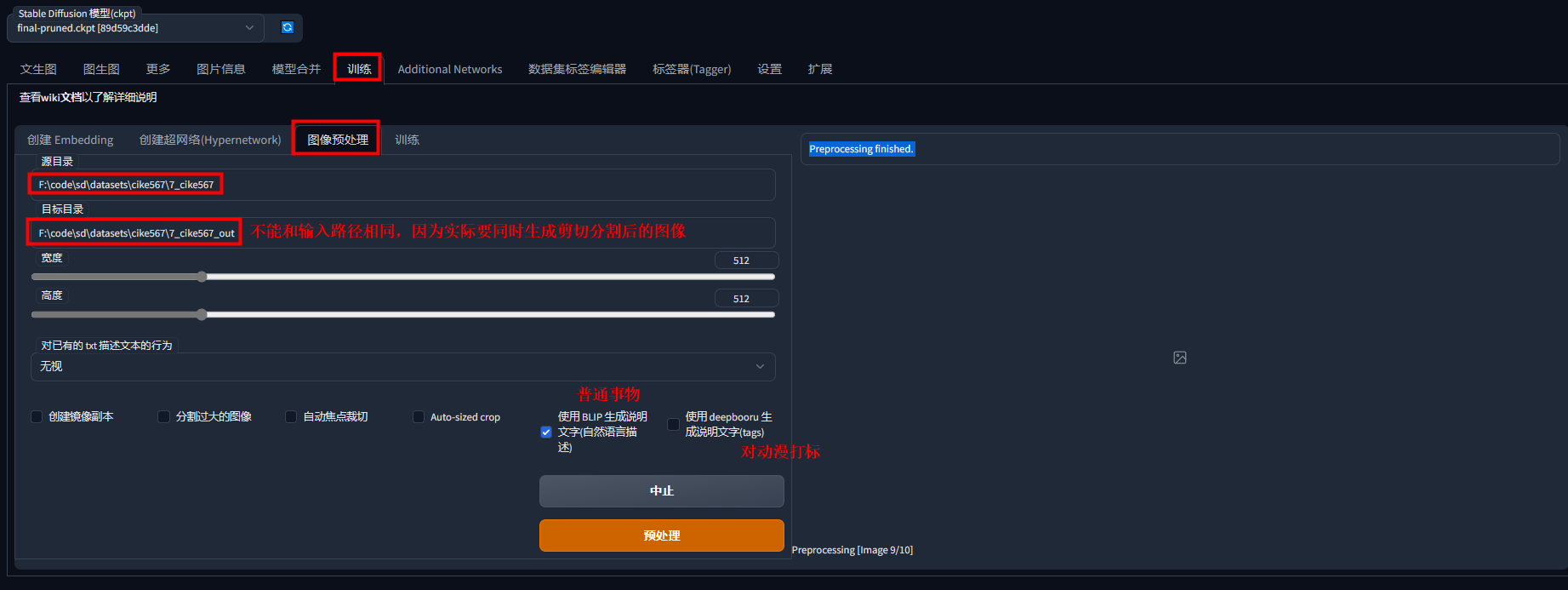
一、sd-webui通用的打标界面
1.1 打标界面
根据需求,选择通用打标模型(BLIP)还是动漫打标模型(deepbooru)
设置好后,选择预处理,会开始下载模型,可开代理加速
1.2 BLIP打标结果
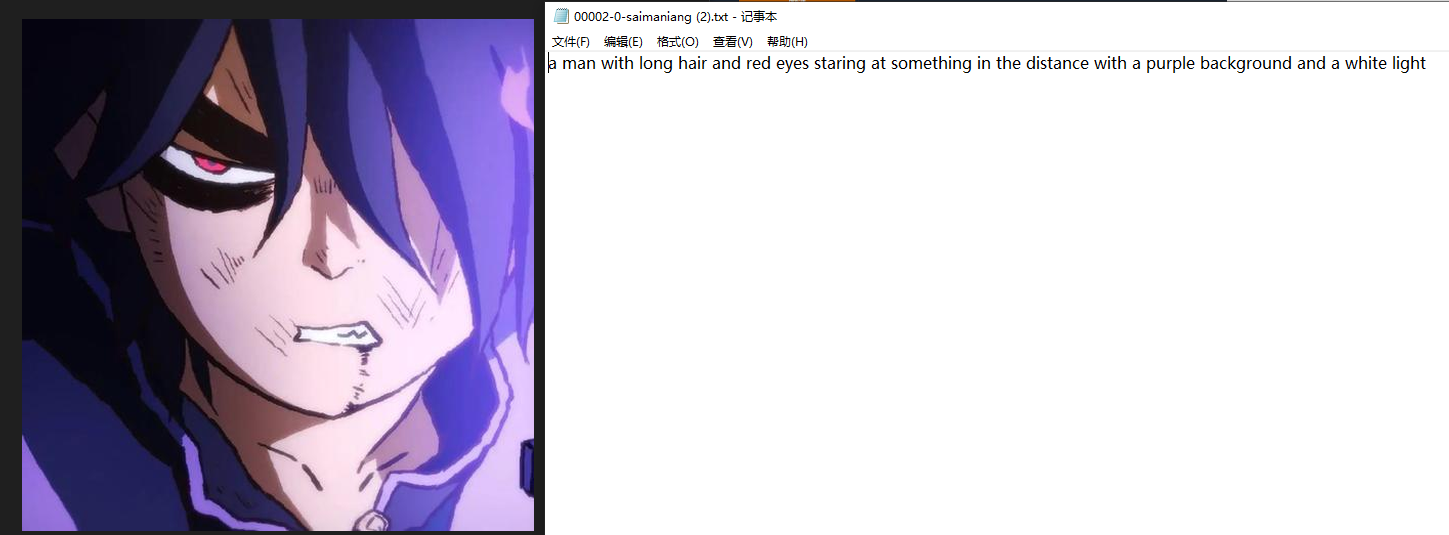
1.3 Deepbooru标注结果 (标签效果比下一段介绍的wd-14差一些)
二、sd-webui插件下wd14自动对动漫打标
插件名称: stable-diffusion-webui-wd14-tagger
安装与下载方式
可参考
在 extensions/文件夹下拉取源码
git clone https://github.com/toriato/stable-diffusion-webui-wd14-tagger.git extensions/tagger
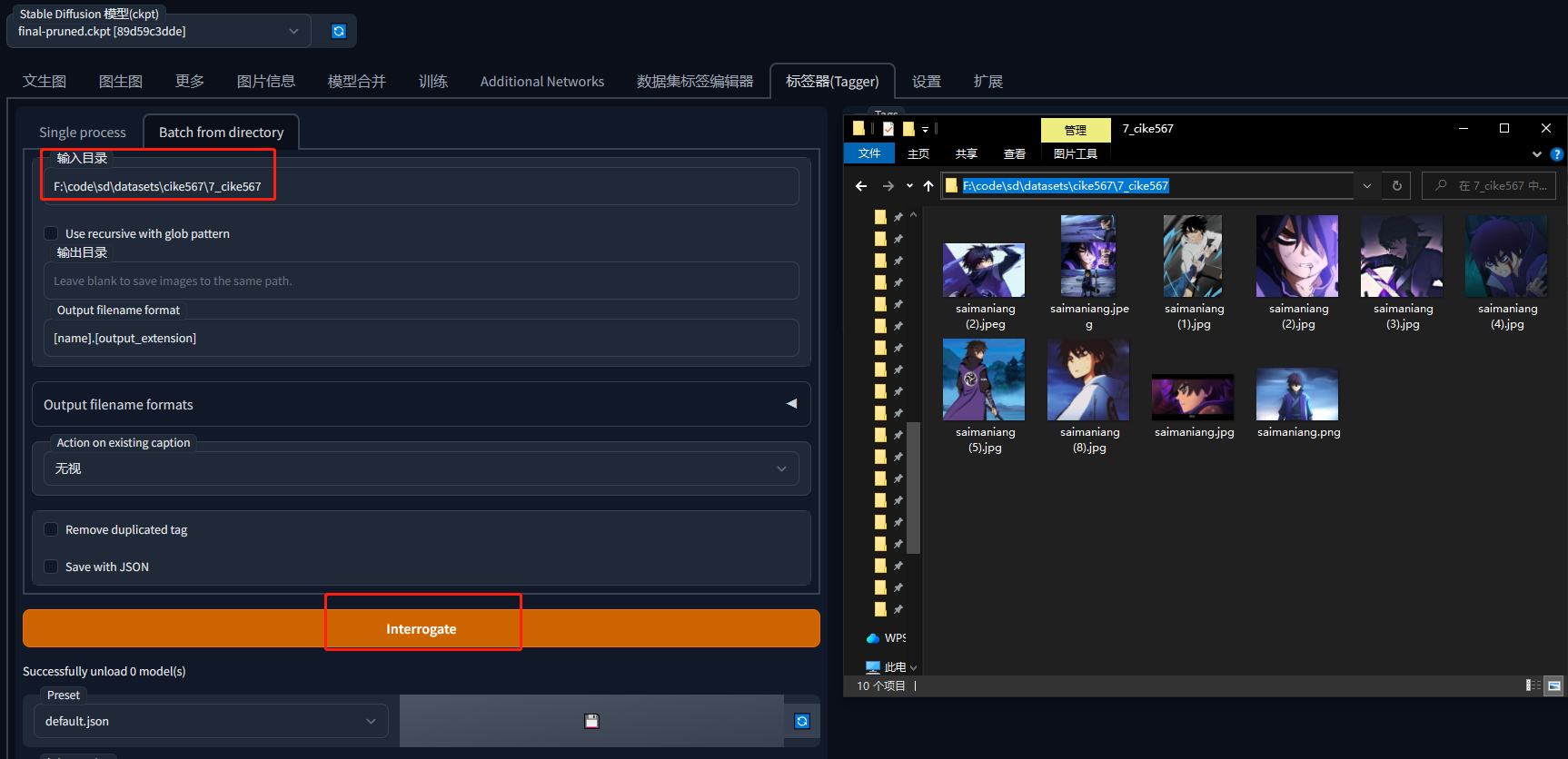
2.1 选择Tagger下的Batch from directory
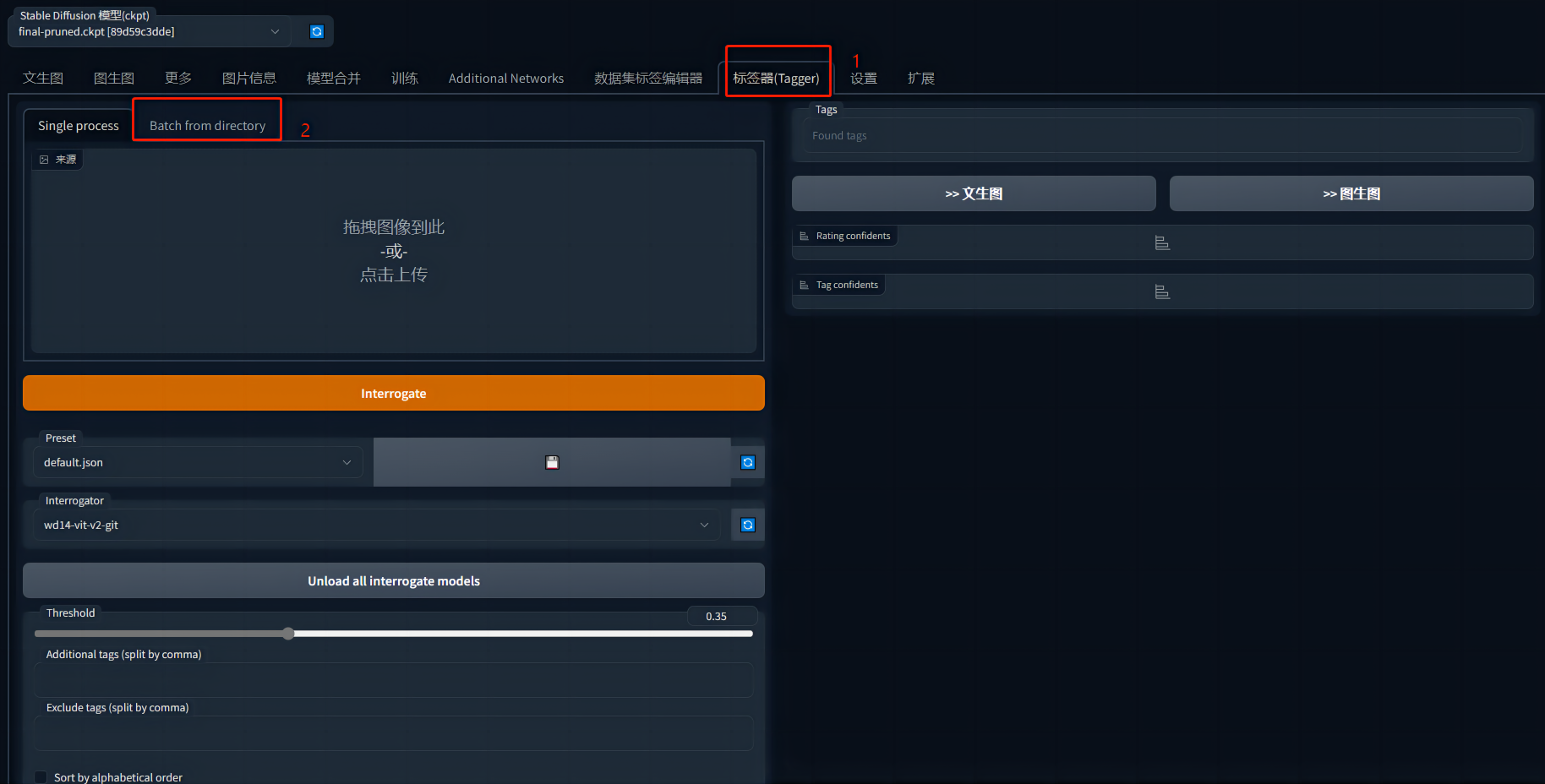
2.2 输入图片的路径
图片与服务器应在同一台电脑
批量打标
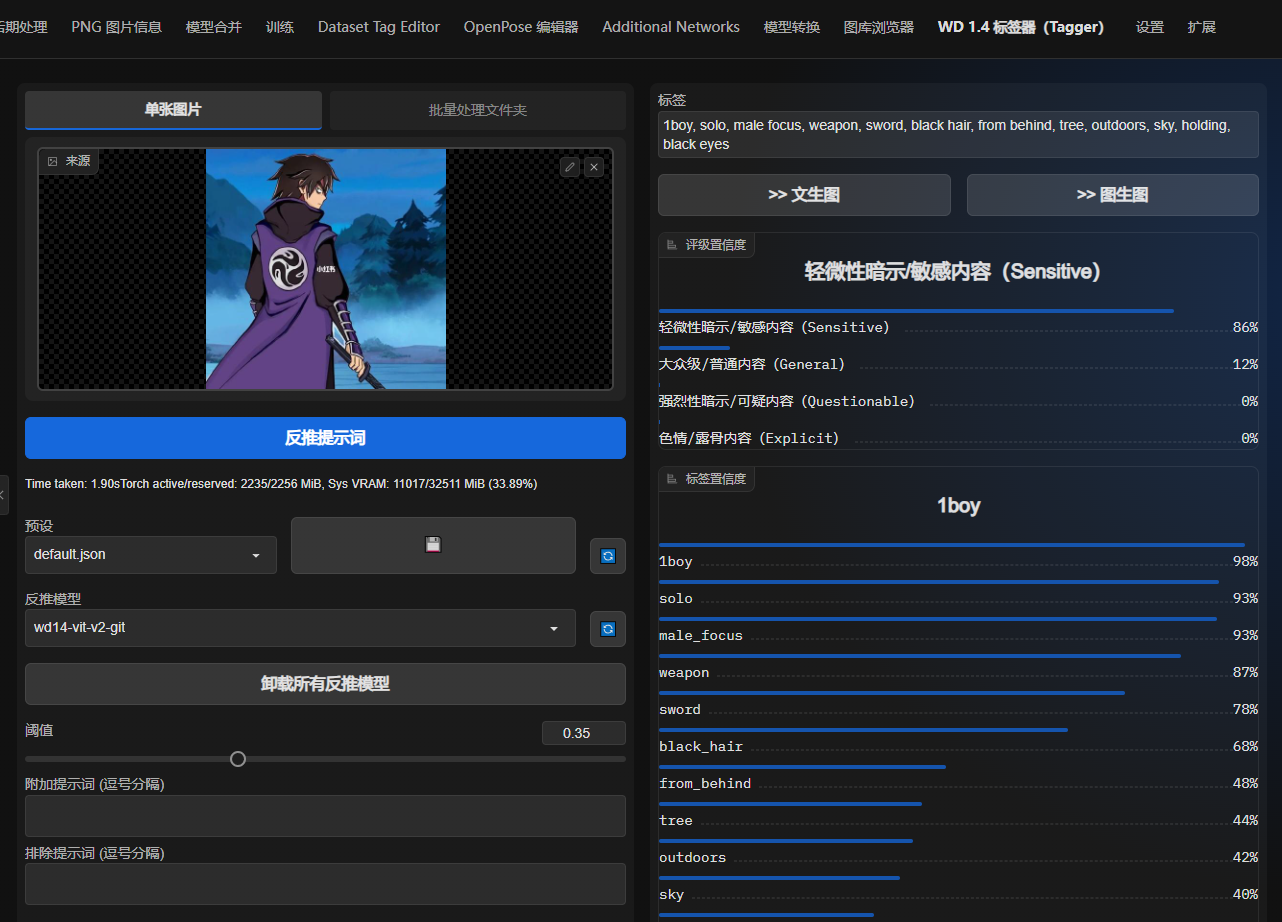
单张图片看效果
可以了解到一些打标签原理,他是一个多类分类器,输出得每个词都是有概率的,一般输出置信度40%以上的词。
2.3 等待模型自动下载(可能卡住)
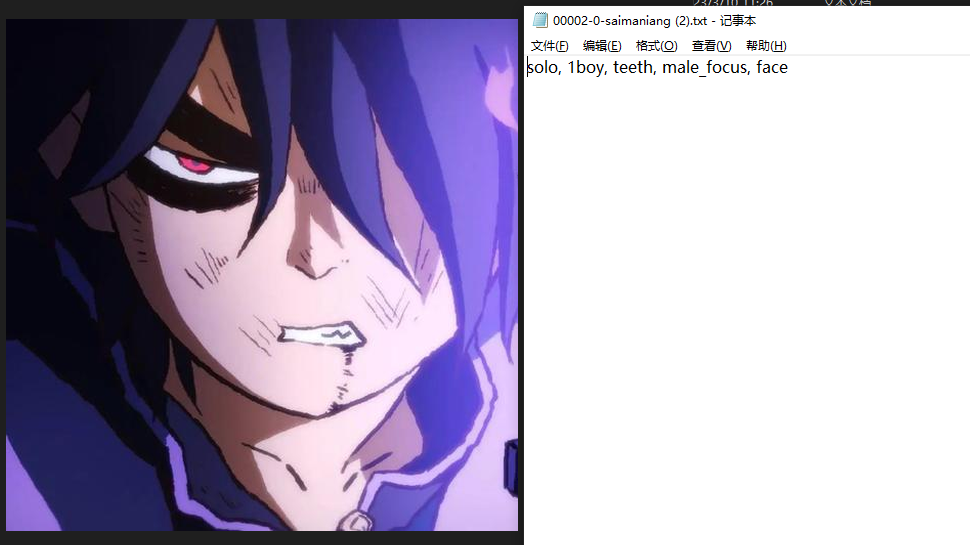
2.4 打标结果
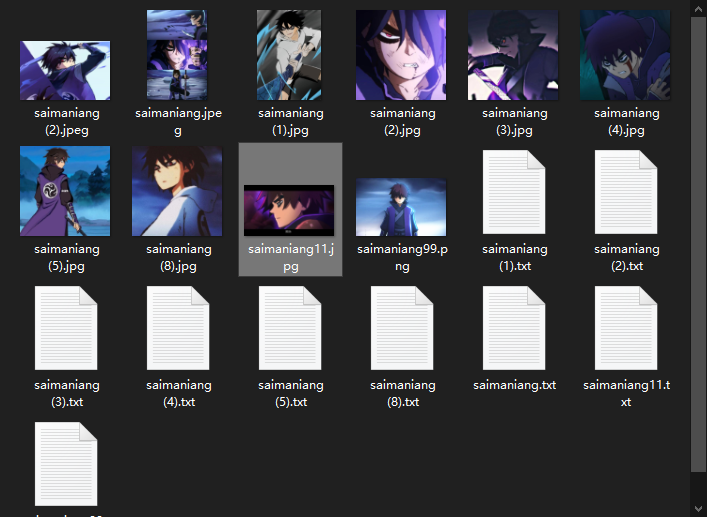
图片与对应tag结果1
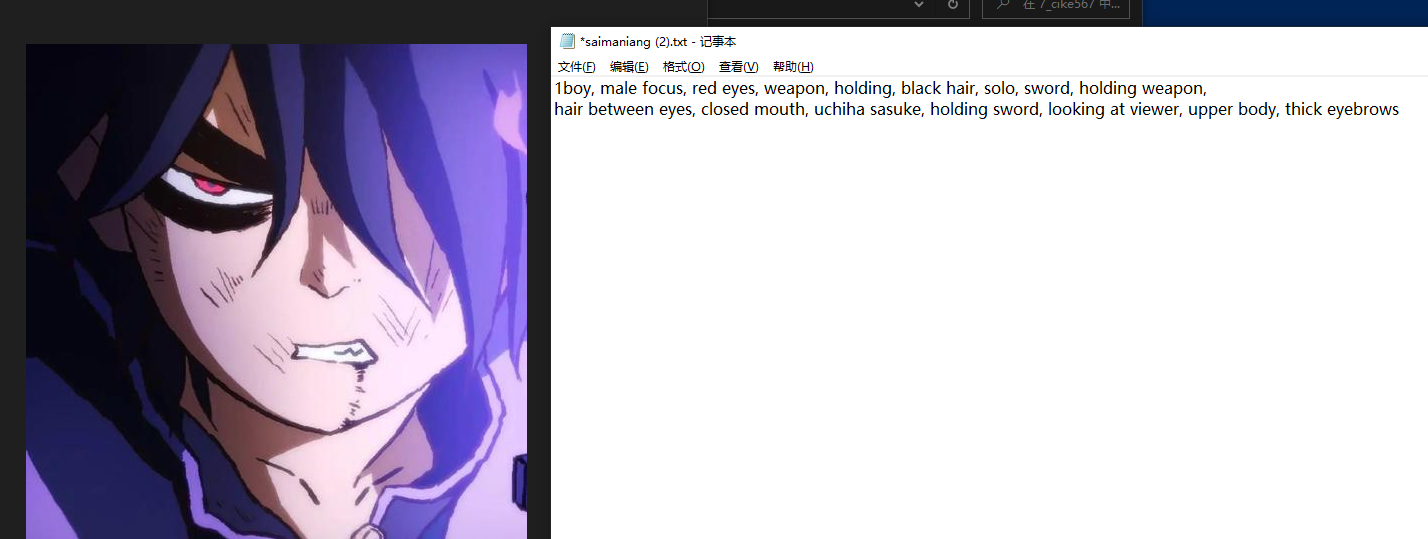
图片与对应tag结果2
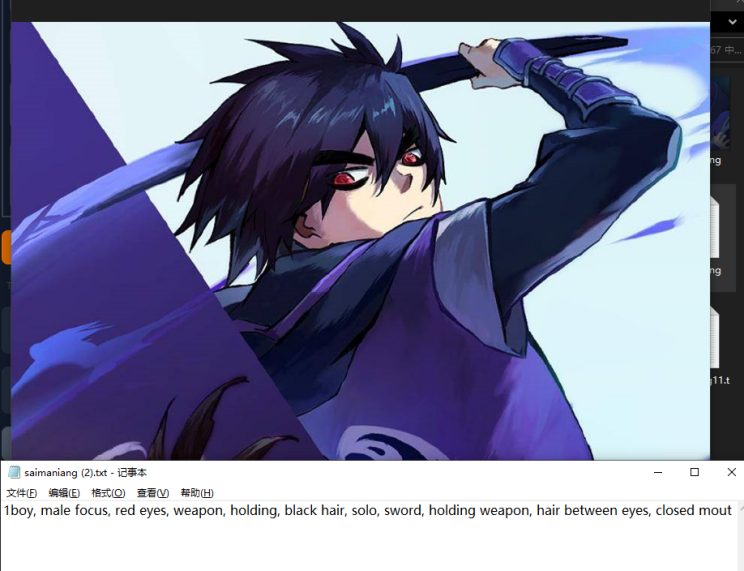
三、sd-webui编辑标签
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
下载:
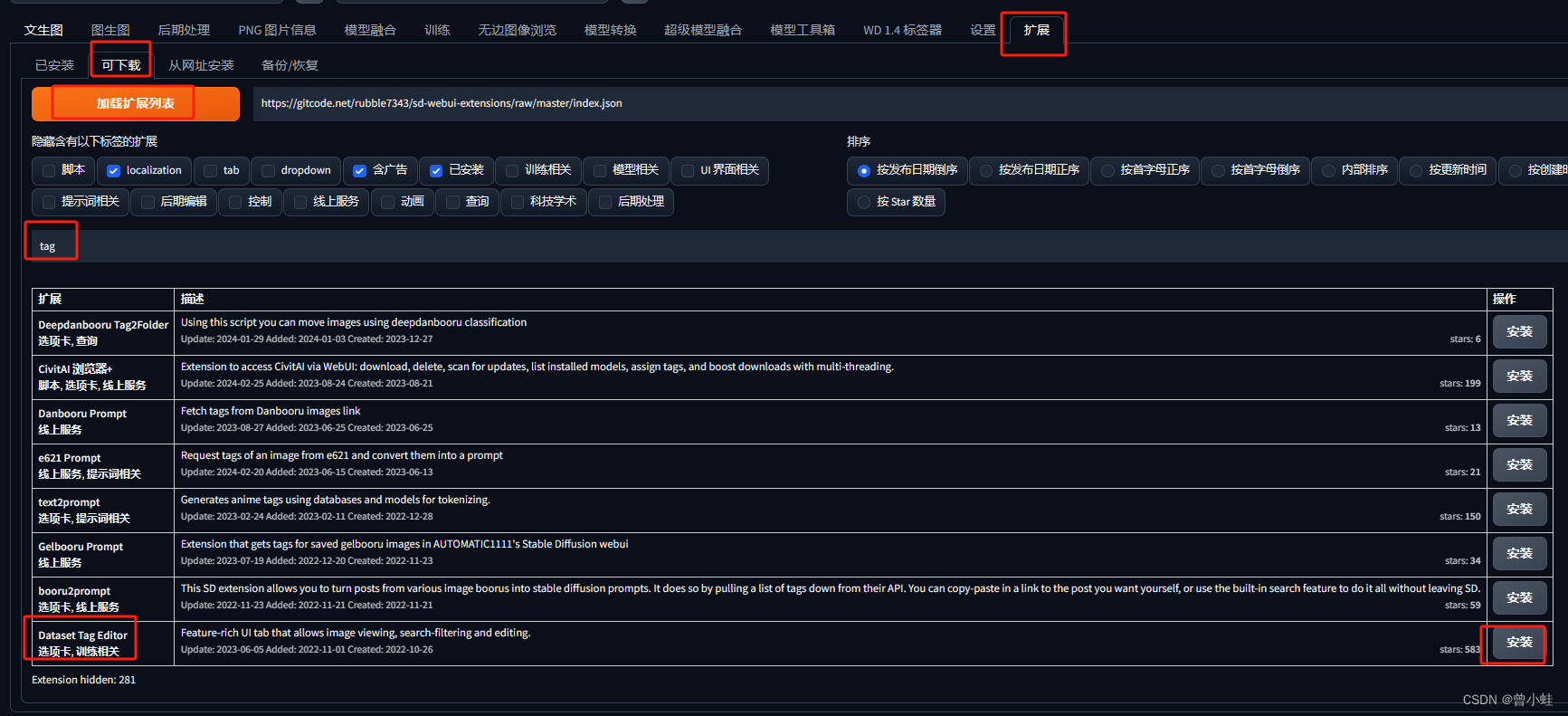
3.1 导入自动打标后的图片
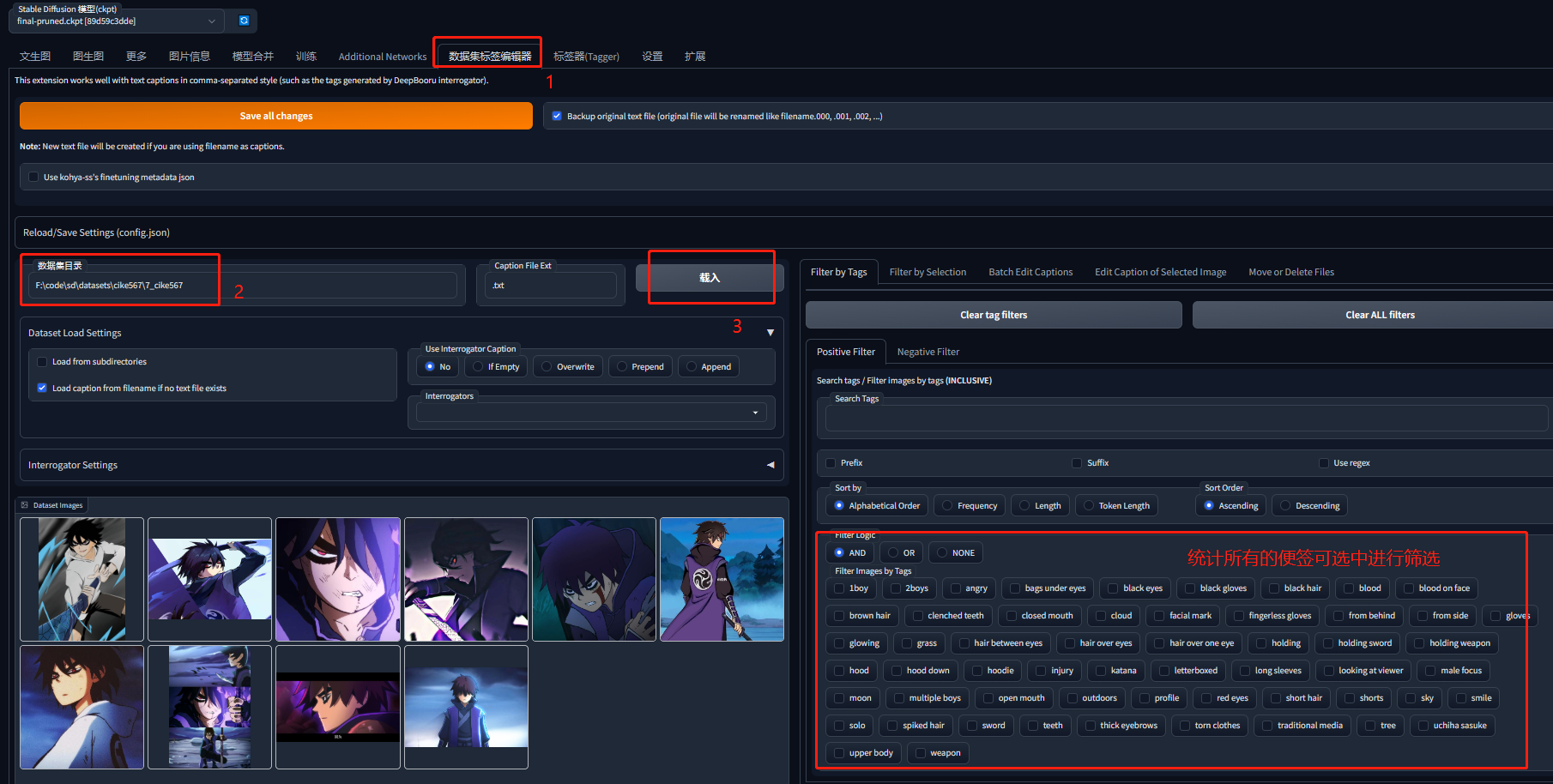
3.2 批量修改添加
首先在所有tag前面加一个风格tag: cike567
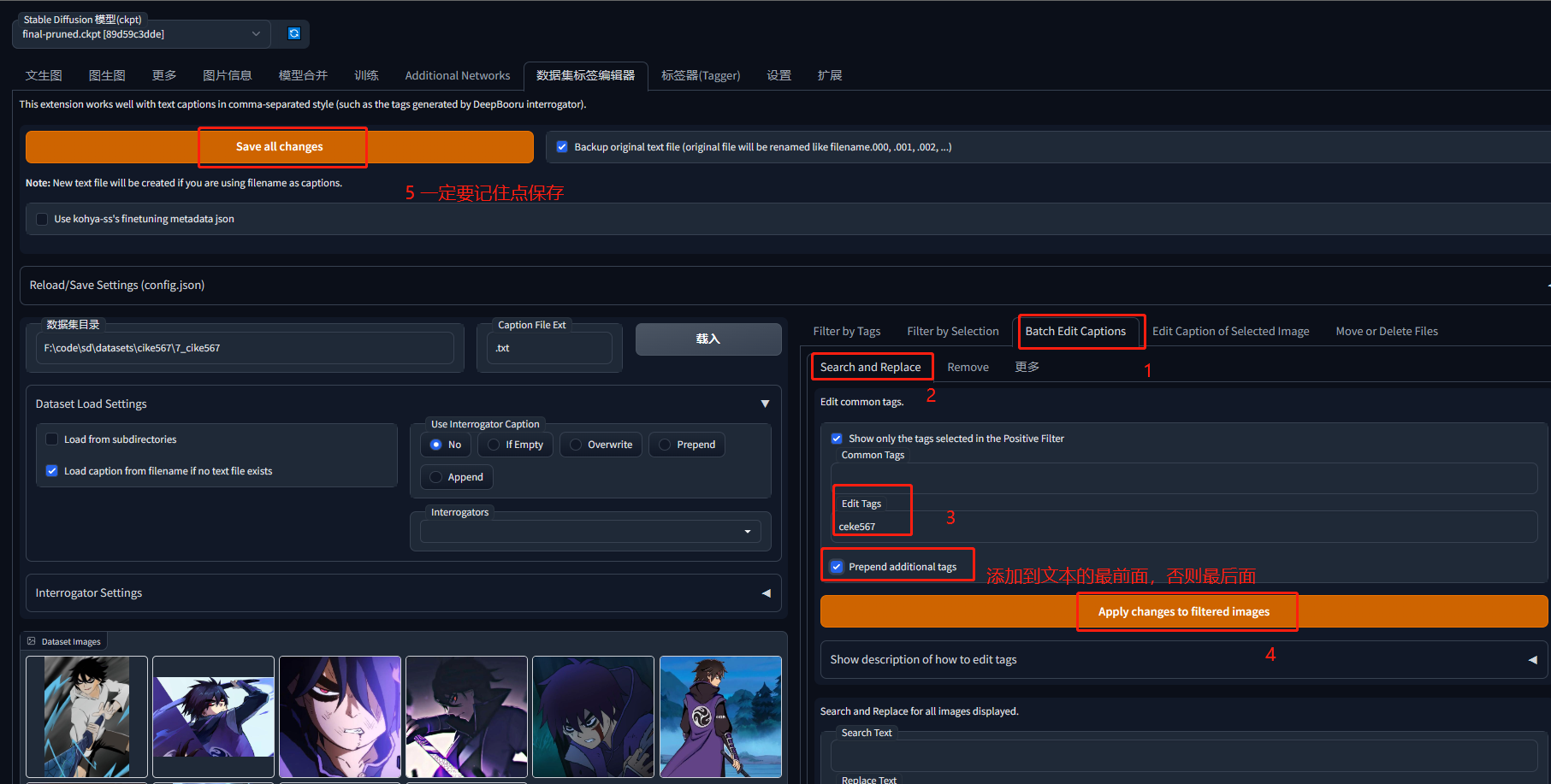
打开txt查看

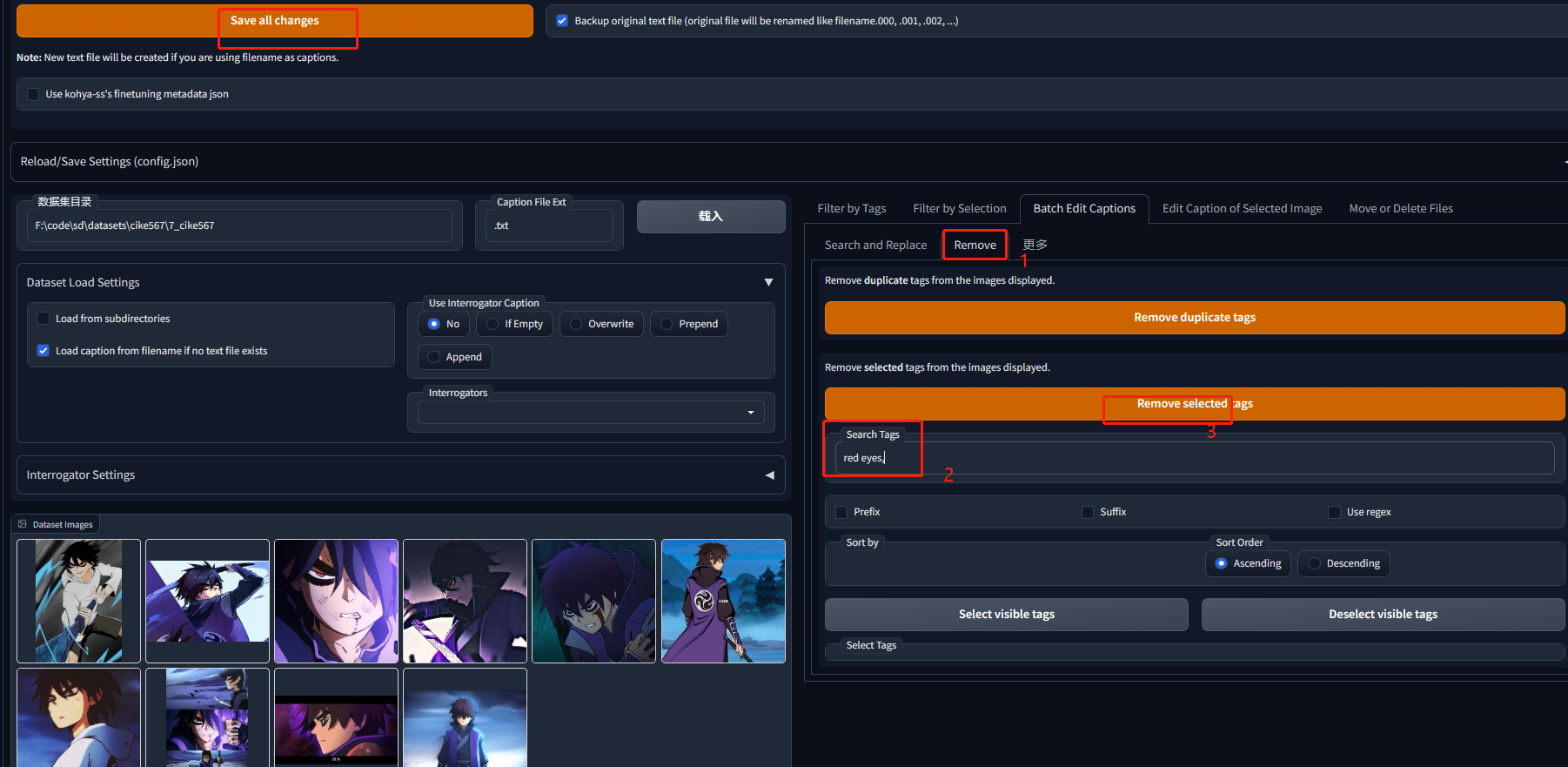
3.3 批量删除
四、lora训练集成开发工具自动打标
(下载模型时间长,过程是类似的,本文暂不介绍了)
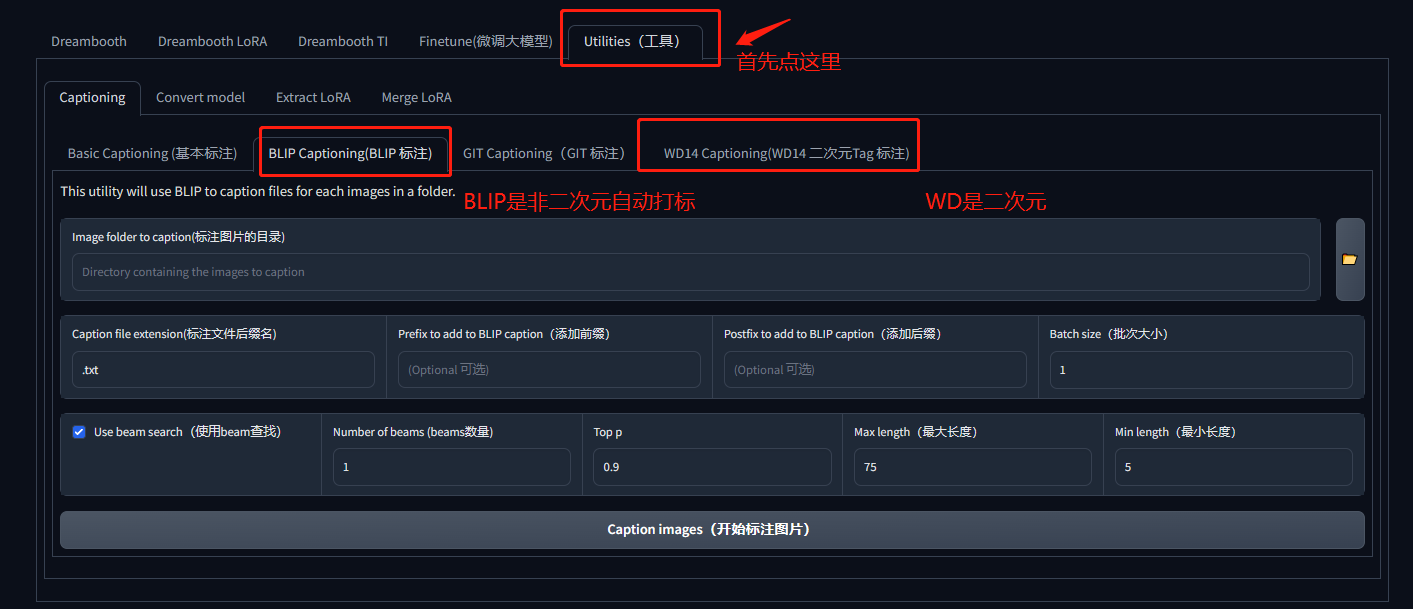
4.1 BLIP打标
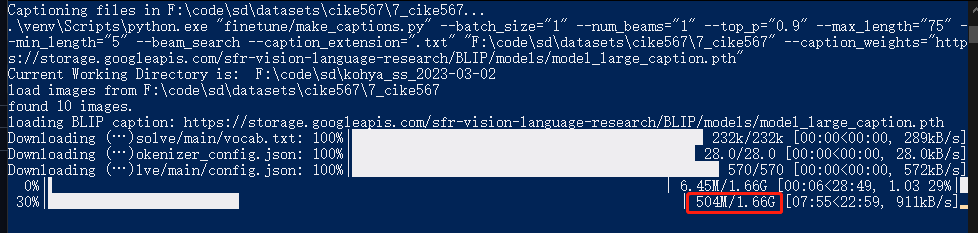
首先会下载模型,下载非常慢
扩展——方法 阿里线上平台打标
https://modelscope.cn/aigc/modelTraining
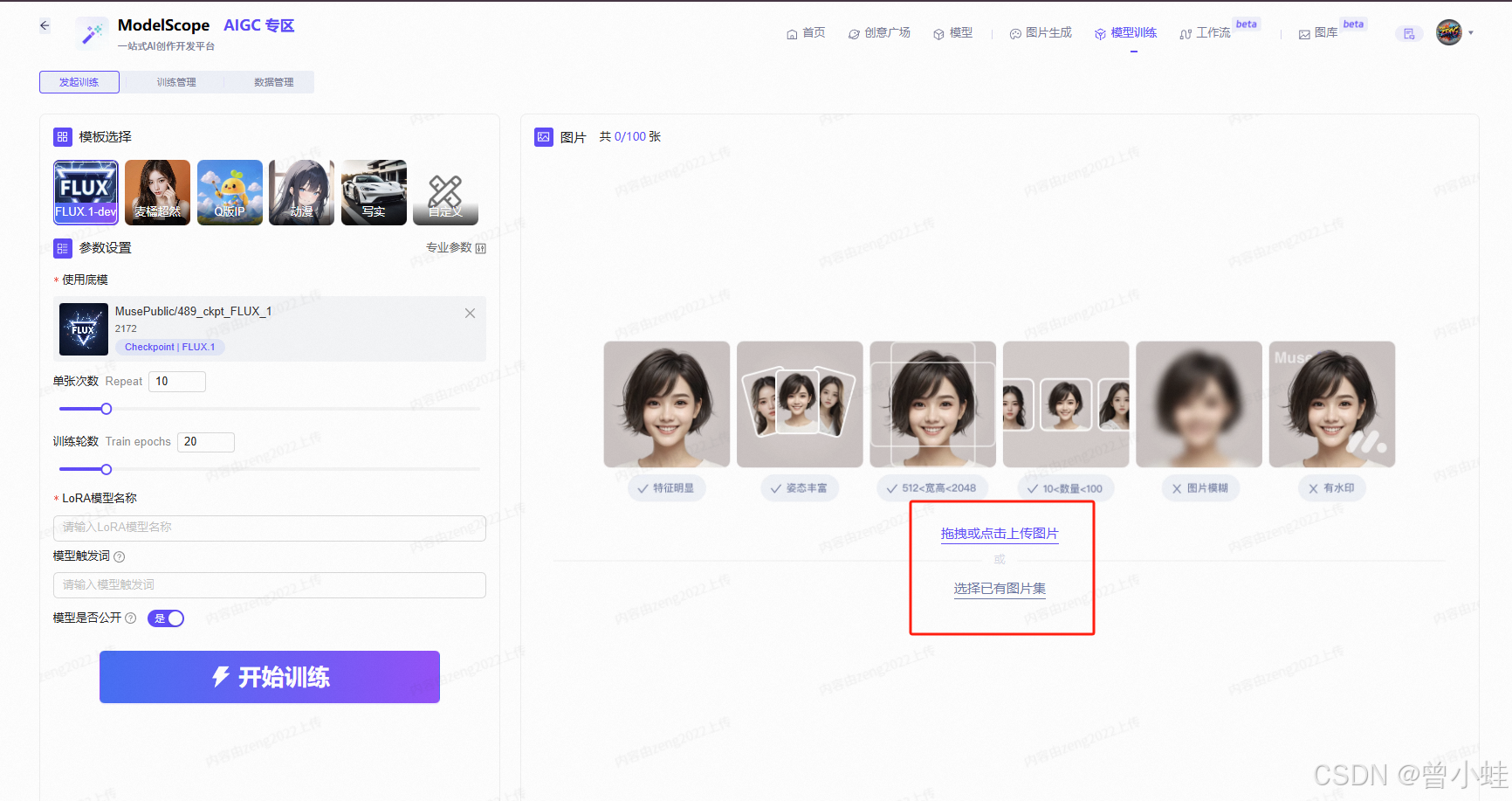
上传图片后选择 打标方式
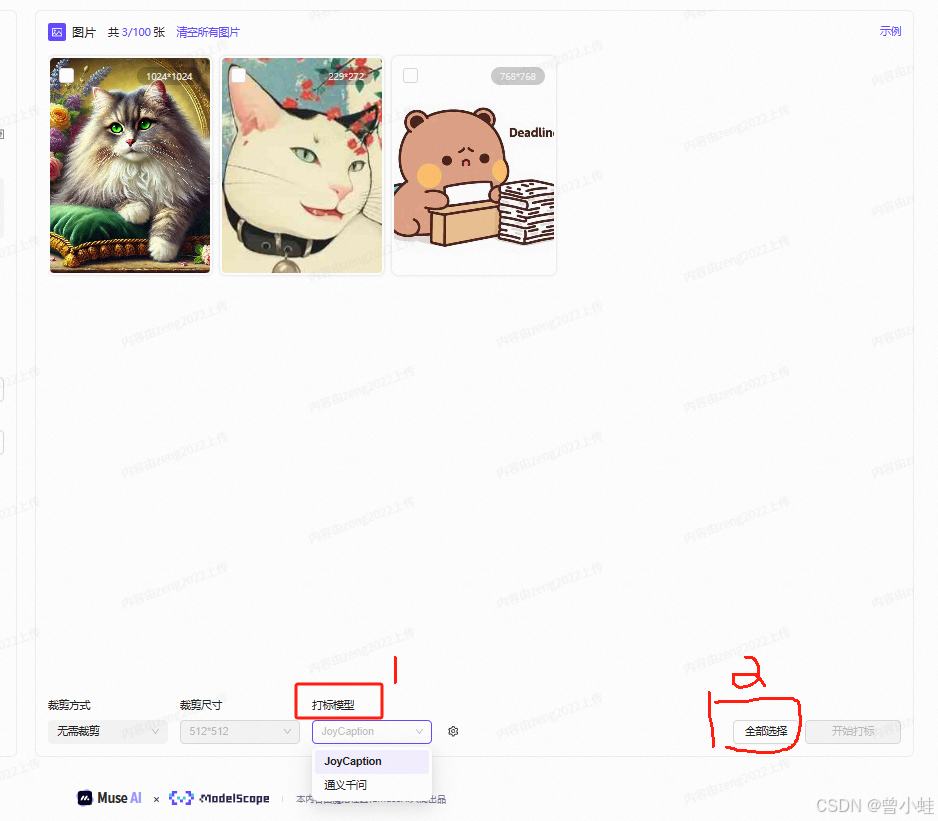
通义千问 单词打标
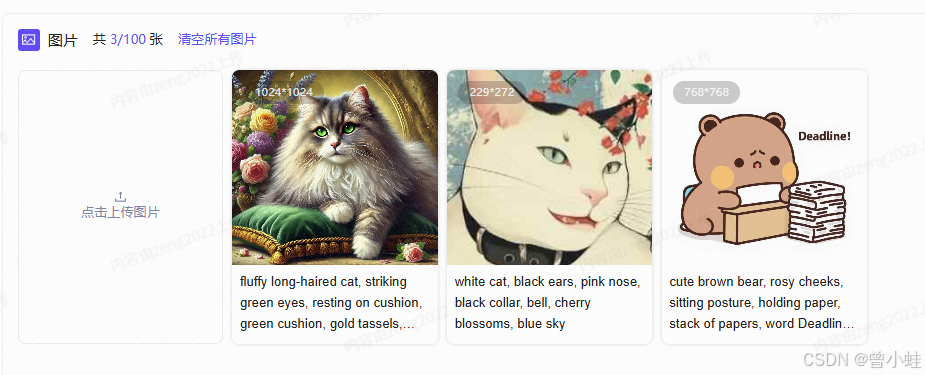
翻译
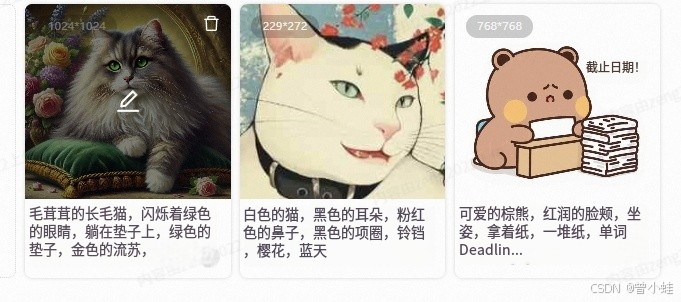
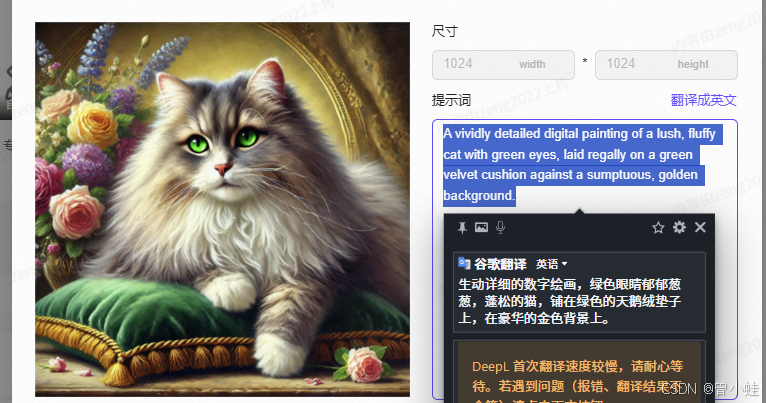
joycaption是连续的句子,适合flux之类的
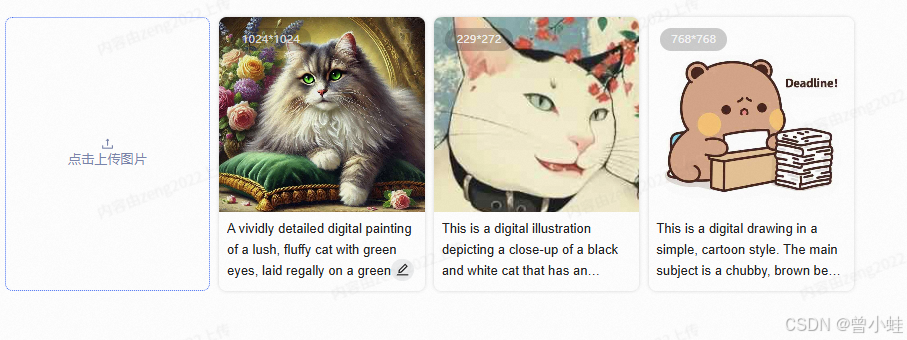
详情



















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











