







前情提要
之前我们根据教程完成了一套完整的CNN模型训练和分类任务,包括nn.Module的用法,梯度的计算和更新等。然而,我们还是留了一小块内容没有深究,那就是数据的处理和读取,即上一章开头加载图片时所用到的torchvision.datasets以及torch.utils.data.DataLoader。本章笔记整理了官方教程对于相关知识点的阐述,继续根据代码来解读相关模块的用法。
WRITING CUSTOM DATASETS, DATALOADERS AND TRANSFORMS
有经验的人都知道,实践中机器学习的大量精力都会耗费在数据准备这一环节中。Pytorch也同样针对这一环节提供了一系列工具,包括对数据的预处理、增强等等功能。
梳理一下我们即将要介绍的关键流程:
- 访问数据
- 数据变换(预处理、增强等)
- 数据采样(打包为batch,打乱顺序,多线程读取等)
以上每个流程各自都拥有更丰富的内涵,会在后续展开。
首先我们先导入本次需要使用到的模块:
from __future__ import print_function, division
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode数据集介绍
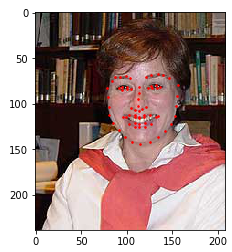
教程中使用到的数据集仍然是图片形式,只不过这次额外附带了面部姿态信息,通过68个界标点(landmark points)来标记姿态,得到的效果将如下图:

数据集可以从这里下载,下载并直接解压缩后放在代码路径下的data文件夹内(如果没有则新建一个)。
在data/faces/目录下有一个名为face_landmarks的csv文件,里面包含了每张图片的名称,以及对于的姿态annotation(也就是每个landmark point在图片内的横纵坐标),大致如下图:

我们可以使用pandas读取csv文件并输出看看
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 66
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2) #将annotation重新排列,一行为一个点的坐标
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4])) #输出这幅图前4个点的坐标输出
Image name: person.jpg Landmarks shape: (68, 2) First 4 Landmarks: [[ 78. 83.] [ 79. 93.] [ 80. 103.] [ 81. 112.]]
我们还可以写一个函数来把landmark point和对应的人脸画在一起:
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
show_landmarks(io.imread(os.path.join('data/faces/', img_name)),
landmarks)
plt.show()效果如下:
Dataset class
了解过我们的数据集之后,我们需要一种合理的方式去访问这个数据集。对于此数据集,我们有两个重要内容需要访问:landmark points的坐标,以及图片本身。Pytorch提供了一个抽象类torch.utils.data.Dataset来代表一个数据集,用户自定义的数据集应该继承它并重写必要的方法,包括:
- __len__:返回数据集的大小
- __getitem__:使得可以通过dataset[i]的下标形式来访问第i个数据
本例中的数据集具有一重要特征,那就是annotations都存储在体积较小的csv文件中,且能起到通过名称索引图片的作用;而对于的图片则由于数量较多,会占据较大存储空间(虽然其实只有60几张图,但是我们要体会这种思路。。。)。因此,我们可以在__init__方法中事先读取csv文件,而只在通过下标访问调用了__getitem__方法时才读取相应的图片,即节省了内存又能保证访问的速度。
我们规定读取的数据以{'image': image, 'landmarks': landmarks}的字典形式返回。除此之外,我们允许数据集接收一个名为transform的参数(实际上是一个实现了__call__方法的类),给出对读取的数据项进行的变换操作。代码详见下方:
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file) #初始化时就把csv文件读入
self.root_dir = root_dir
self.transform = transform
def __len__(self): #返回数据集总大小
return len(self.landmarks_frame)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:]
landmarks = np.array([landmarks])
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample我们可以试试实例化这个数据集类,并通过它来访问几张图片:
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break输出如下:
0 (324, 215, 3) (68, 2) 1 (500, 333, 3) (68, 2) 2 (250, 258, 3) (68, 2) 3 (434, 290, 3) (68, 2)

Transforms
仔细观察我们的数据集中的图片,是不是发现图片的尺寸其实并不统一?这样可不能直接送给一个CNN进行训练呀!其次,我们希望实现数据增强,也就是扩充原始的数据集得到更丰富的数据,这要怎么实现呢?最后,如果要使用Pytorch进行训练,我们还需要把读取的类型转化为Tensor。这三步都可以统一称为transforms,也就是我们接下来要介绍的内容。我们可以定义一下三种变换(transforms):
- Rescale:改变图片尺寸
- RandomCrop:随机截取原图的一个子图来扩充(增强)数据集
- ToTensor:将numpy格式的图片转化为Tensor
注意:每个变换的功能需要实现在__call__方法内,__call__方法的作用我在上一篇中提到过,作为功能性的类,__call__方法可以集成类中所有需要使用到的方法,而我们只需要给类的实例传参就能完成一系列操作,而不用像常规的类一样依次去调用需要使用的方法。其他关于__call__方法的作用可参考https://www.cnblogs.com/renfanzi/p/5818767.html。上述三种变换的代码实现如下:
class Rescale(object):
"""Rescale the image in a sample to a given size.
Args:
output_size (tuple or int): Desired output size. If tuple, output is
matched to output_size. If int, smaller of image edges is matched
to output_size keeping aspect ratio the same.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# h and w are swapped for landmarks because for images,
# x and y axes are axis 1 and 0 respectively
landmarks = landmarks * [new_w / w, new_h / h]
return {'image': img, 'landmarks': landmarks}
class RandomCrop(object):
"""Crop randomly the image in a sample.
Args:
output_size (tuple or int): Desired output size. If int, square crop
is made.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}Pytorch中还提供了能够整合一系列变换的工具:torchvision.transforms.Compose,它的参数是一个以变换为元素的列表。下面的代码比较了单独调用Rescale、RandomCrop和Compose后的变换对图片处理的效果:
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# Apply each of the above transforms on sample.
fig = plt.figure()
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()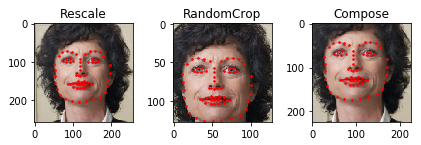
可以看见,最后一幅图(Compose)结合了前两步操作。
Iterating through the dataset
有了自己的数据集类,也学会了如何整合若干个变换,我们就可以系统地进行数据访问啦!先试试看通过我们的数据集类读取数据并用整合好的变换进行处理得到的结果如何:
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break输出结果:
0 torch.Size([3, 224, 224]) torch.Size([68, 2]) 1 torch.Size([3, 224, 224]) torch.Size([68, 2]) 2 torch.Size([3, 224, 224]) torch.Size([68, 2]) 3 torch.Size([3, 224, 224]) torch.Size([68, 2])
可以发现,所有的数据都有了统一的尺寸,也都变成了Pytorch中的格式!
但是,这样的数据还是不能直接喂给我们的网络。我们最开始的时候就了解到了,nn.Module是以batch为单位读取样本的,而我们还没有实现抽样的方案。其次,为了提高抽样的效率,我们还需要启动多线程策略。这样来看,我们还缺失下面几步:
- 样本分批
- 打乱样本顺序
- 并行抽样
这下要登场的就是我们一开始提到的torch.utils.data.DataLoader了!它可以一次性完成上述三种操作!我们需要使用到它的四个主要参数,第一个默认参数是datasets类的实例,第二个batch_size说明batch的大小,第三个shuffle是布尔类型的变量,指明是否需要打乱样本顺序,第四个num_workers则指定线程的数量。由于Windows下指明num_workers不为零时会报错,因此我在这里将其修改为了0,其他系统的朋友可以改成其他数字。我们可以试着用DataLoader对数据集进行操作,并打印一个batch看看效果,代码如下:
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=0)
# Helper function to show a batch
def show_landmarks_batch(sample_batched):
"""Show image with landmarks for a batch of samples."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid_border_size = 2
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size + (i + 1) * grid_border_size,
landmarks_batch[i, :, 1].numpy() + grid_border_size,
s=10, marker='.', c='r')
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# observe 4th batch and stop.
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff()
plt.show()
break输出如下:
0 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2]) 1 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2]) 2 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2]) 3 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])

可以发现,一个batch确实是4个样本!
至此,对于输入数据的完整处理已经结束了。
Afterword: torchvision
官方教程在最后还悉心提示道,Pytorch的torchvision提供了许多封装好的变换供直接使用。除此之外,Pytorch还实现了名为ImageFolder的datasets子类,能够根据形如:
root/ants/xxx.png root/ants/xxy.jpeg root/ants/xxz.png . . . root/bees/123.jpg root/bees/nsdf3.png root/bees/asd932_.png
的文件组织形式来读取图片和label,可以说是十分方便了!
好了,本章就到这里结束了,over!















 3118
3118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









