









目录
一、前言
在做数据分析的时候,很少会遇到连续变量和分类变量,更多的是需要我们对同时包含连续变量和分类变量进行可视化分析。所以我们在在本篇当中要开始来学习如何处理同时包含连续变量和分类变量进行可视化分析的问题。
二、介绍
Ⅰ.一个分类变量和一个连续变量
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import altair as alt
Iris=pd.read_csv(r'C:\Users\asuspc\Desktop\program\data\chap2\Iris.csv')
Irislong=Iris.melt(['Id','Species'],var_name='measurement_type',value_name='value')开始之前还是老样子,先导包和获取数据,得到之后,我们将数据变成长型数据用到melt方法,Id和Species变量与其他数据的变化无关所以我们不将这两个数据进行融合。
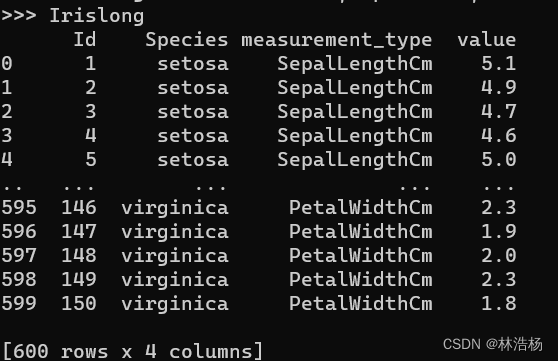
我们就能得出如上的数据,那么接下来就是开始使用可视化,我们可以使用箱线图,分析在不同分类变量下,连续变量的分布情况。
plt.figure(figsize=(10,6))
sns.boxplot(data=Irislong,x='Species',y='value')
plt.title('Box')
plt.show()这里对X轴和Y轴的变量名称注释清楚,然后将处理好的数据Irislong放入。

从图中我们可以发现,三者的极差(上下四分位数的距离)趋于一致,但是数据的集中位置在依次升高,箱线图在这的确利于我们取理解数据构成的趋势。
Ⅱ.两个分类变量的一个连续变量
plt.figure(figsize=(10,6))
sns.boxplot(data=Irislong,x='Measurement_type',y='value',hue='Species')
plt.title('The Box of Divided-group')
plt.show()到了两个分类变量的一个连续变量时,我们依然使用箱线图,与一个分类变量和一个连续变量来说,我们更加需要分组的箱线图进行可视化。
这里的参数中hue视为分类变量,将数据分位不同组。
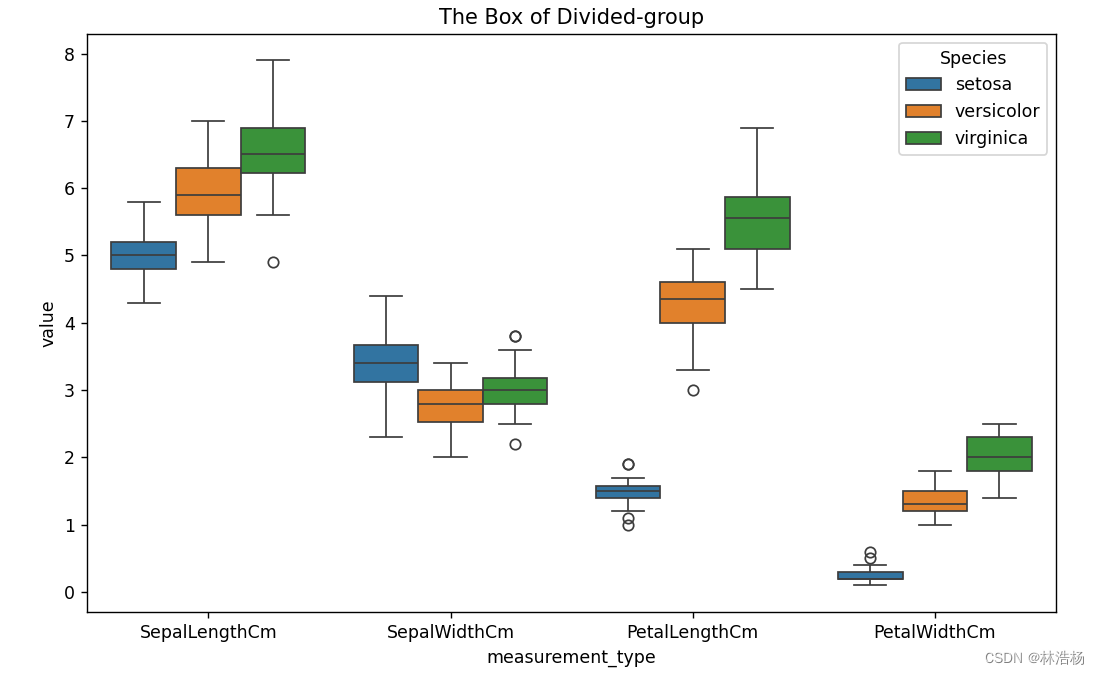
这样我们就能在不同种类中分析同一个数据项的关系,也能让我们一目了然看出一定的趋势。
Ⅲ.两个分类变量和两个连续变量
如果想要可视化两个分类变量和两个连续变量之间的关系,那我们需要分面散点图。
Titanic=pd.read_csv(r"C:\Users\asuspc\Desktop\program\data\chap2\Titanic数据.csv")
fig=sns.FacetGrid(data=Titanic,row='Survived',col='Sex',margin_title=True,height=3,aspect=1.4)
fig.map(sns.scatterplot,'Age','Fare')
plt.show()先分面散点图,其中两个分类变量将可视化切为网格,如何在对应的网格下可视化出两个连续变量的散点图,从而帮助我们 能够对数据进行分析。
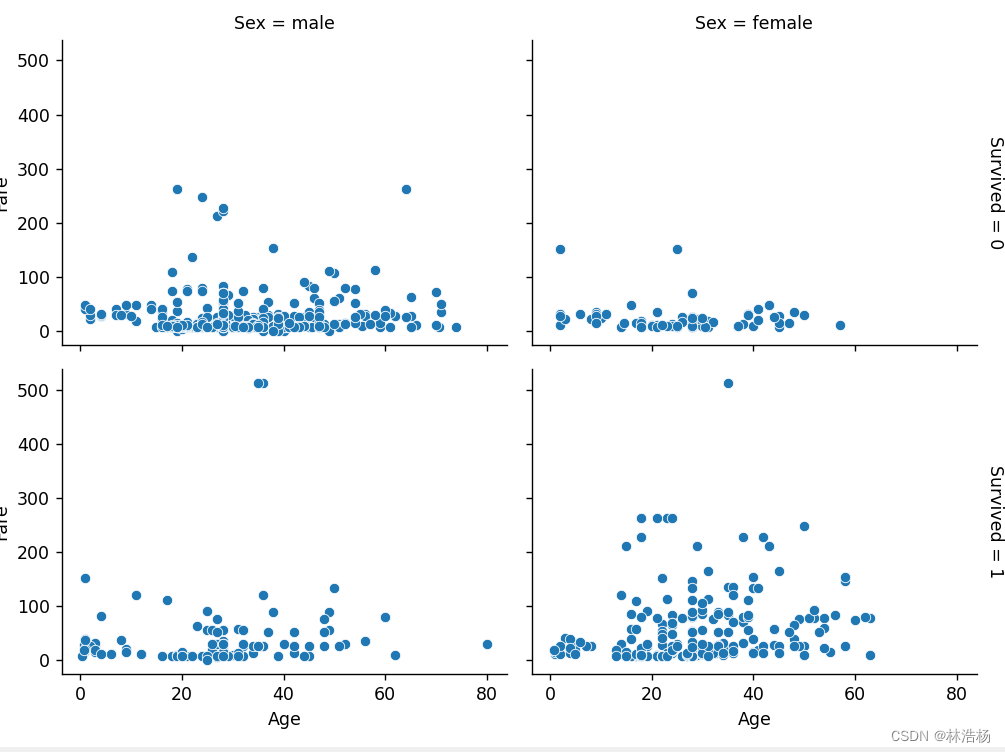
从中我们可以对比不同性别在不同年龄的不同票价中的存活顾客,可以看出,不同年龄层的女性存活总数相对于男性较少,并且买低票价的男性存活高于买低票价的女性
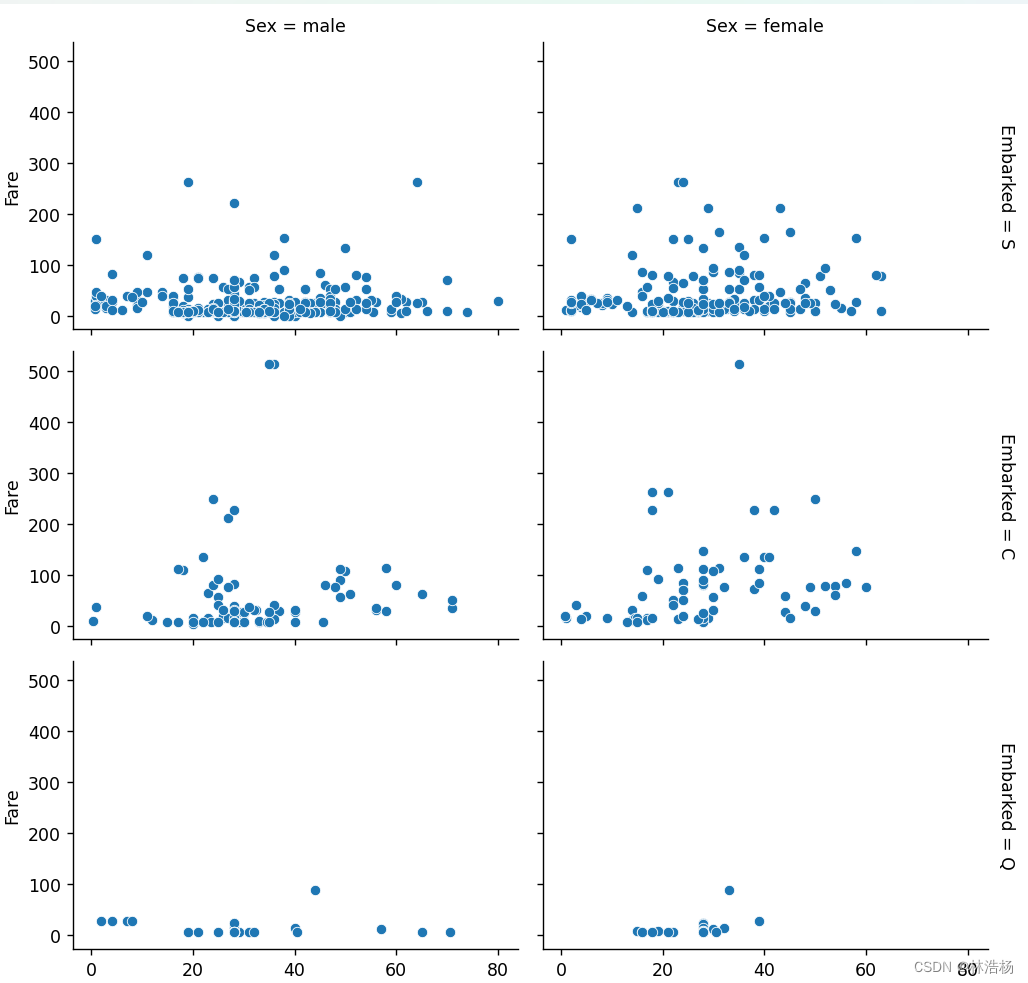
而这张是改变survived为embarked,我们可以看到不同登港的人数和性别对于。
S是Southampton南安普顿,C是Cherbourg法国瑟堡,Q是Queenstown爱尔兰昆士敦。
Ⅳ.一个分类变量和多个连续变量
①.平行坐标轴
plt.figure(figsize=(10,6))
parallel_coordinates(Iris.iloc[:,1:6],"Species",alpha=0.8)
plt.title('Parallel_Coordinates')
plt.show()这里需要的导包是from pandas.plotting import parallel_coordinates, 用iloc的方法定位取值,而class_column:str 包含类名的列名。(即按类别划分),我们这里只是将将class_column省略,直接填‘Species’。

其中每一个变量都是横轴中的一个坐标点,值的大小标记在对应的竖直线上,用颜色为分组变量中的每条平行线进行分组。我们清晰的看出第三个连续变量在不同类别的差异是最大的,最小的是第一个连续变量。
②.矩阵散点图
sns.pairplot(Iris.iloc[:,1:6],hue='Species',height=2,aspect=1.2,diag_kind='kde',markers=['o','s','D'])
plt.show()我们用三种不同的颜色来描述不同种类在这一连续变量的密集程度,hue参数如上为分类分组,iloc是数据的切片操作。

这样我们就可以更加具体分析在不同分类变量里的连续变量的关系,有助于我们对不同分类变量对比不同连续变量的数据特征。
三、结语
这些数据描述的通常是表格数据,那么对于其他类型的数据也有特定的数据可视化的方法,下一篇我们将对其进行相关介绍。
















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









