







Spark 单机版本安装
安装Java
安装scala
http://www.scala-lang.org/
按步骤点确定即可
此时需要注意 hadoop2.6.x 只能使用 scala2.10.x , 否则会报错无法运行
Intellij IDE 开发
- 下载后安装scala插件
- 下载spark预编译版本
- 将spark-assembly-1.6.1-hadoop2.6.0.jar 添加到 Intellj IDE 安装目录 lib文件夹下
- File -> Project Structure -> Libraries -> +号 -> java ->添加spark-assembly-1.6.1-hadoop2.6.0.jar
- 选择scala 2.10.6
Scala-IDE for Eclipse
- 添加 spark-assembly-1.6.1-hadoop2.6.0.jar
- 默认编译器选择2.11.x, 手动修改为2.10.6
win 7 下单机版WordCount
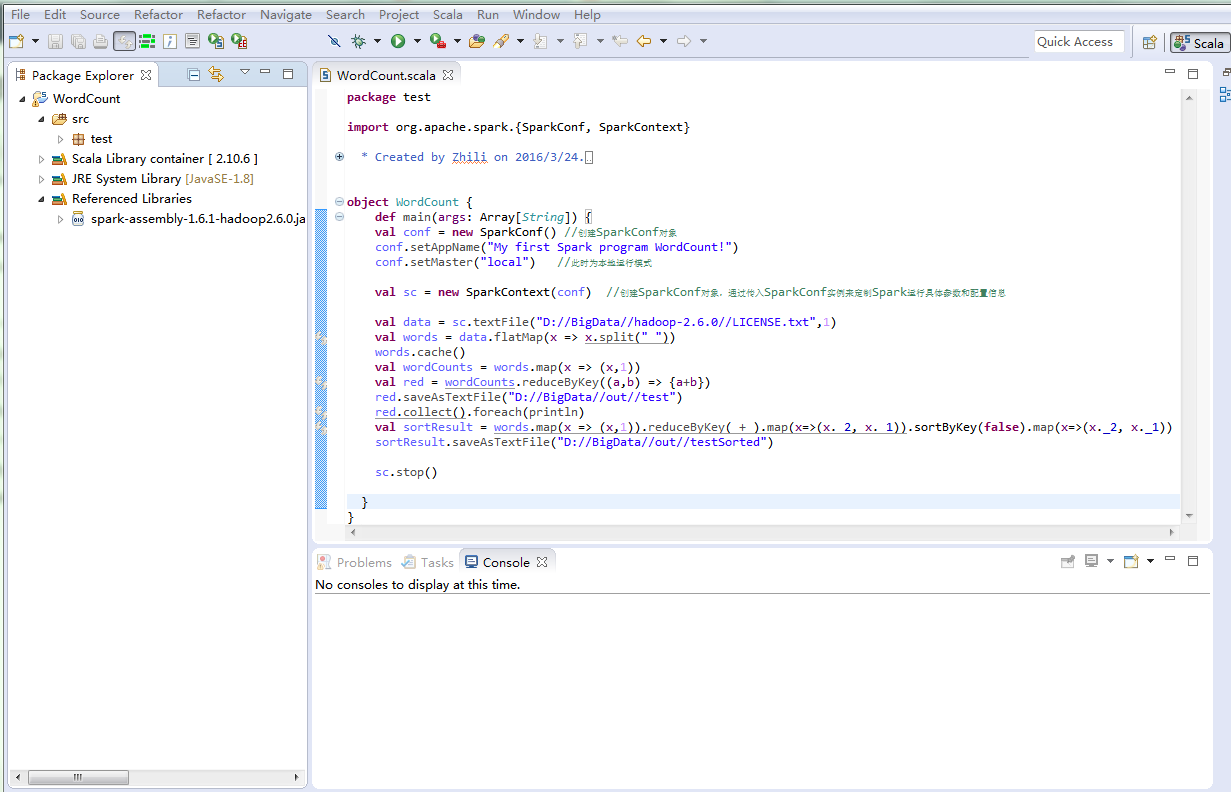
package test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Zhili on 2016/3/24.
*/
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName("My first Spark program WordCount!")
conf.setMaster("local") //此时为本地运行模式
val sc = new SparkContext(conf) //创建SparkConf对象,通过传入SparkConf实例来定制Spark运行具体参数和配置信息
val data = sc.textFile("D://BigData//hadoop-2.6.0//LICENSE.txt",1)
val words = data.flatMap(x => x.split(" "))
words.cache()
val wordCounts = words.map(x => (x,1))
val red = wordCounts.reduceByKey((a,b) => {a+b})
red.saveAsTextFile("D://BigData//out//test")
red.collect().foreach(println)
val sortResult = words.map(x => (x,1)).reduceByKey(_+_).map(x=>(x._2, x._1)).sortByKey(false).map(x=>(x._2, x._1))
sortResult.saveAsTextFile("D://BigData//out//testSorted")
sc.stop()
}
}
个人还是比较习惯eclipse, 鼠标悬停有类型提示,对于新手学习scala, 隐式转换等都有帮助
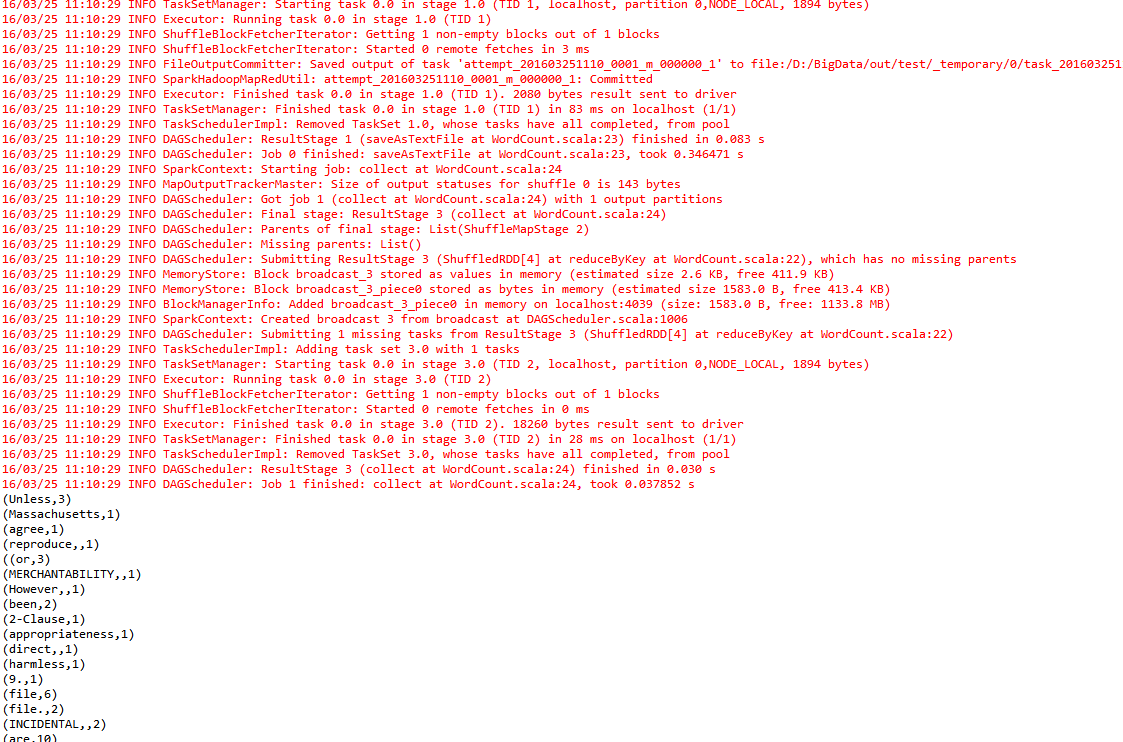
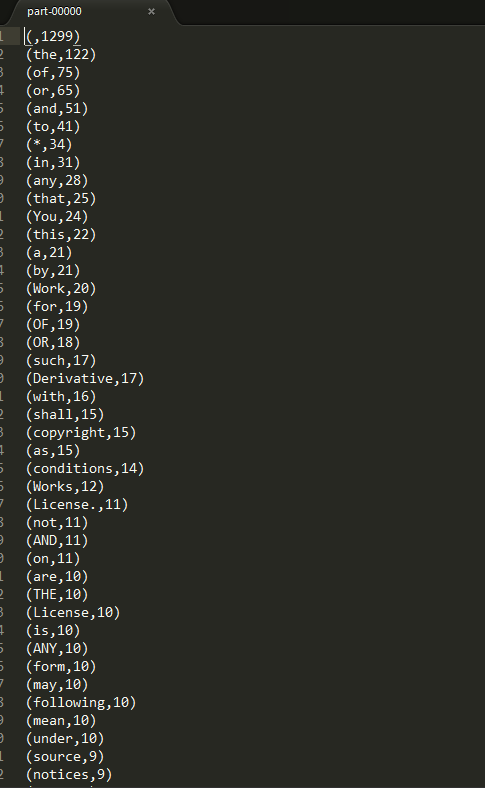
运行结果

提交到伪分布式集群
- 确保集群节点连接正常
ssh Slave1
ssh Slave2 cd /usr/local/hadoop/sbin
./start-dfs.sh
jsp
Master:50070 //查看DFS信息hdfs dfs -mkdir -p /user/hadoop
hdfs dfs -mkdir input
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml inputhdfs dfs -mkdir /test/input
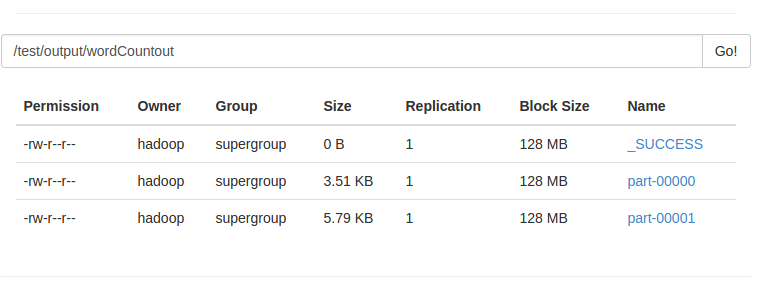
hdfs dfs -mkdir /test/output
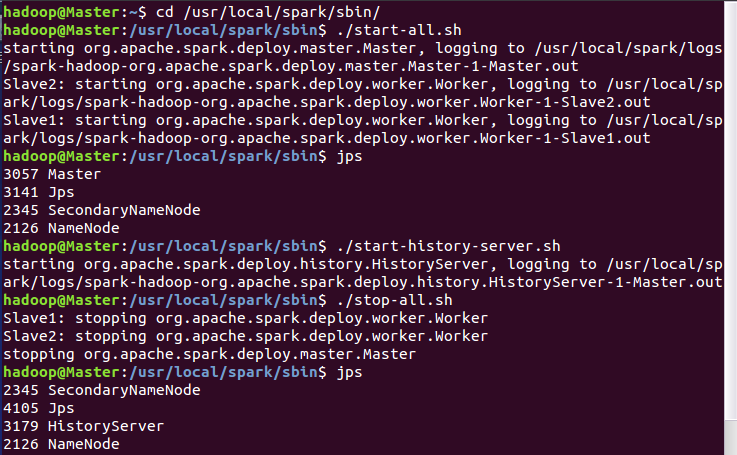
hdfs dfs -put /usr/local/hadoop/LICENSE.txt /test/input- cd /usr/local/spark/sbin
./start-all.sh
Master:8080
./start-history-server.sh export jar
上传 /Document/SparkApps//home/hadoop/Documents/SparkApps/WordCount.jar
wordcount.sh
/usr/local/spark/bin/spark-submit –class test.WordCount_Cluster –master spark://Master:7077 /home/hadoop/Documents/SparkApps/WordCount.jar
cd /home/hadoop/Documents/SparkApps/
chmod +x wordcount.sh // chmod 777 wordcount.sh
./wordcount.sh
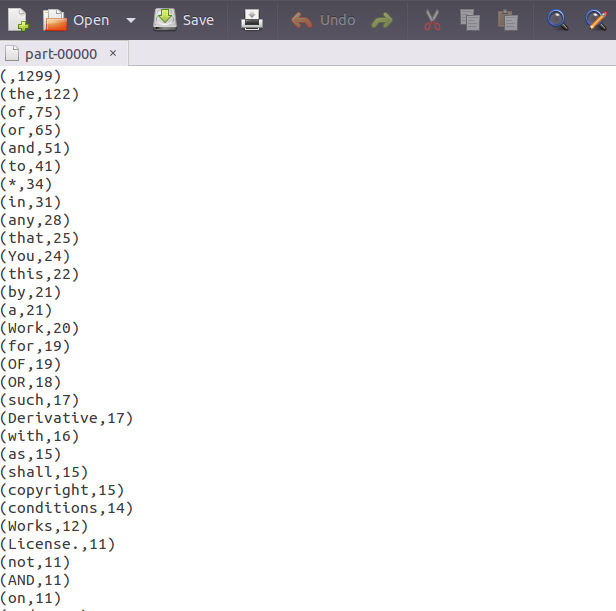
note:
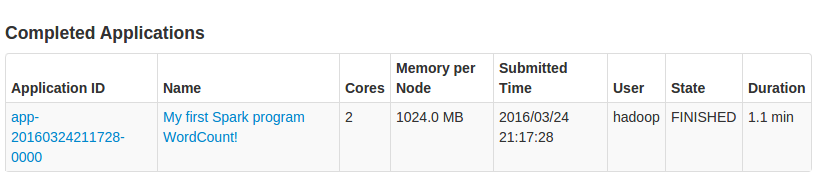
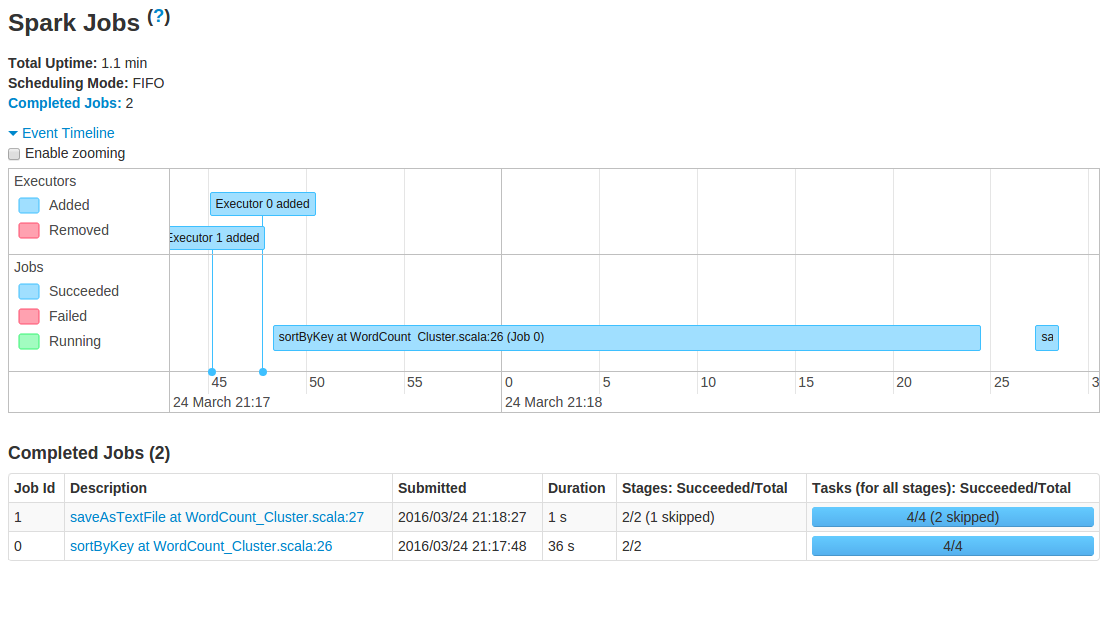
由于文件太小,只有几十k,在集群上运行的时间花了1分钟!!!
这也是hdfs的性质原理所决定的















 2190
2190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









