









实验原理:
1、 条件随机场:
生成式概率图模型是直接对联合分布进行建模,如隐马尔可夫模型和马尔可夫随机场都是生成式模型。判别式概率图模型是对条件分布进行建模,如条件随机场Conditional Random Field:CRF。
条件随机场是用来标注和划分序列结构数据的概率化结构模型。对于给定的输出,标识序列Y和观测序列X,条件随机场通过定义条件概率P(Y|X),而不是联合概率分布P(X, Y)来描述模型。
条件随机场试图对多个随机变量(它们代表标记序列)在给定观测序列的值之后的条件概率进行建模:令X={X1,X2,⋯,Xn}为观测变量序列,Y={Y1,Y2,⋯,Yn}为对应的标记变量序列。条件随机场的目标是构建条件概率模型P(Y∣X)。即:已知观测变量序列的条件下,标记序列发生的概率。
标记随机变量序列Y的成员之间可能具有某种结构:
• 在自然语言处理的词性标注任务中,观测数据为单词序列,标记为对应的词性序列(即动词、名词等词性的序列),标记序列具有线性的序列结构。
• 在自然语言处理的语法分析任务中,观测数据为单词序列,标记序列是语法树,标记序列具有树形结构。
令G=<V,E>表示与观测变量序列X和标记变量序列Y对应的无向图,Yv表示与结点v对应的标记随机变量,n(v)表示结点v的邻接结点集。若图G中结点对应的每个变量Yv都满足马尔可夫性,即:P(Yv∣X,YV−{v})=P(Yv∣X,Yn(v))。则(Y,X)构成了一个条件随机场。
图G可以具有任意结构,只要能表示标记变量之间的条件独立性关系即可。但在现实应用中,尤其是对标记序列建模时,最常用的是链式结构,即链式条件随机场chain-structured CRF。条件随机场使用势函数和团来定义条件概率{Yi−1,Yi,X},i=2,⋯,n。采用指数势函数,并引入特征函数feature function,定义条件概率:
其中:
• tj(Yi,Yi+1,X,i):在已知观测序列情况下,两个相邻标记位置上的转移特征函数transition feature function。它刻画了相邻标记变量之间的相关关系,以及观察序列X对它们的影响。位置变量i也对势函数有影响。比如:已知观测序列情况下,相邻标记取值(代词,动词)出现在序列头部可能性较高,而(动词,代词)出现在序列头部的可能性较低。
• sk(Yi,X,i):在已知观察序列情况下,标记位置i上的状态特征函数status feature function。它刻画了观测序列X对于标记变量的影响。位置变量i也对势函数有影响。比如:已知观测序列情况下,标记取值名词出现在序列头部可能性较高,而动词出现在序列头部的可能性较低。
• λj,μk为参数Z为规范化因子(它用于确保上式满足概率的定义)。K1为转移特征函数的个数,K2为状态特征函数的个数。
特征函数通常是实值函数,用来刻画数据的一些很可能成立或者预期成立的经验特性。
2.中文分词
中文分词指的是中文在基本文法上有其特殊性而存在的分词 。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
基本思想:每个字在构造一个特定的词语时都占据着一个确定的构词位置(即构词位)。常用的四位构词位:词首(B),词中(M),词尾(E),独立词(S)。
基本原理:
CRF中文分词的图结构:
3. 基于词位标注的分词方法简介
现代机器学习的主要方法,包括支持向量机(Support Vector Machine,SVM)、最大熵(EM)和条件随机场(CRF),都己经被应用于由字构词的分词学习中。由于分词过程通常处于中文处理的前端,因此,很难设计出有效的特征来大幅度提高分词性能。事实上,由于分词的初等地位,可供选用的特征也非常少。迄今为止,最常用的两类特征是字本身以及词位(状态)转移概率(这里我们沿用隐马尔科夫模型H朋中的术语)。
对于SVM和ME来说,需要设计独立的状态转移特征来表达词位的转化。但是对于一阶线性链CRF学习来说,这一转移过程将被自动集成到系统中来,而无需专门指定。这样,对于基于CRF建模的分词系统而言,需要考虑的仅仅是字特征。
词位学习中确定字特征的主要参数是上下文窗口的宽度,也就是使用距当前字多远的字来作为当前字分类的依据。相关工作表明,使用前后各两个字(即5个字的窗口宽度)是比较理想的。
一个确定有效词位标注集的定量标准—平均加权词长。其定义为:
上式中,是时的平均加权词长,从是语料中词长为k的词次数,是语料中出现过的最大长,N是语料库的总词次数。如果k=l,那么Ll,代表整个语料的平均词长。
四、实验目的:
通过CRF++的使用,加深对CRF的理解,加深对中文分词的理解。
实验内容:
(一) 训练/测试语料格式转换程序开发
(二) 条件随机场汉语分词模型训练.
(三) 词位标注正确率统计程序开发
(四) 标注结果还原程序开发
(五) 标注结果的分析
(六) 修改训练过程的参数配置
(七) 分词正确率的计算
实验数据及结果分析:
(一)训练/测试语料格式转换程序开发。
#coding:utf-8
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--input_file", type=str, default="msr_training_1w.txt", help="The name of input file") #读取文件名称
parser.add_argument("--output_file", type=str, default="msr_training_1w_exchange.txt", help="The name of output file") #写入文件名称
opts = parser.parse_args()
input_file = opts.input_file
output_file = opts.output_file
with open(output_file,"w") as ff:
with open(input_file, "r", encoding='utf-8') as f:
for line in f.readlines():
start = 0
end = line.find(' ')
while end != -1:
#print(str(start) + ' ' + str(end) + '\n')
result = line[start:end]
#print(result)
if len(result) == 2:
temp = result[0] + ' ' + 'B\n'
ff.write(temp)
temp = result[1] + ' ' + 'E\n'
ff.write(temp)
elif len(result) == 1:
temp = result[0] + ' ' + 'S\n'
ff.write(temp)
elif len(result) > 2:
for i in range(0,len(result)):
if i == 0:
temp = result[i] + ' ' + 'B\n'
ff.write(temp)
elif i == len(result) - 1:
temp = result[i] + ' ' + 'E\n'
ff.write(temp)
else:
temp = result[i] + ' ' + 'M\n'
ff.write(temp)
start = end + 2
ff.write(temp)
start = end + 2
end = line.find(' ', end + 2)
if line[start] == '。':
temp = line[start] + ' ' + 'S\n'
ff.write(temp)
ff.write('\n')
ff.write('\n')
ff.close()
f.close()
print("写入成功")
生成结果如图所示:
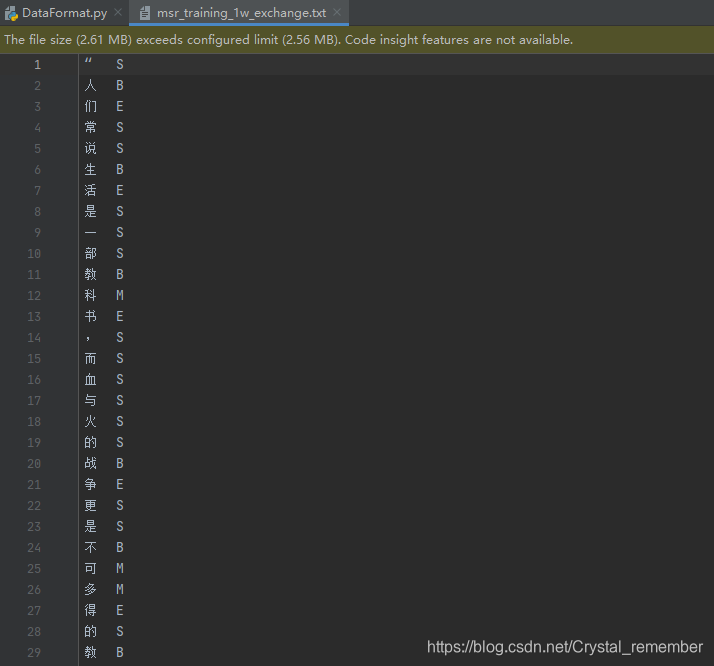
(二)条件随机场汉语分词模型训练.
主要程序为CRF++,通过程序crf_learn.exe crf_test.exe 来进行测试。
TMPT-6定义为:
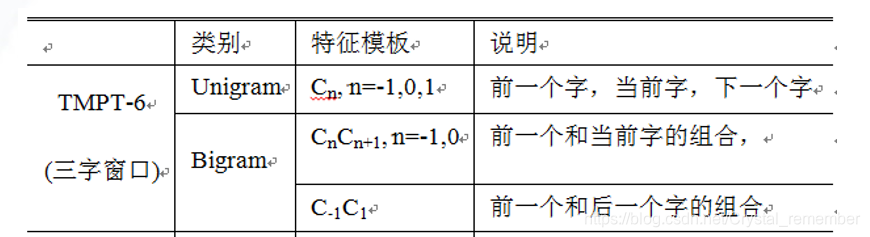
特征模板按照TMPT-6定义的特征集合,修改为如下:
# Unigram
#U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
#U04:%x[2,0]
#U05:%x[-2,0]/%x[-1,0]
U06:%x[-1,0]/%x[0,0]
#U07:%x[0,0]/%x[1,0]
#U08:%x[1,0]/%x[2,0]
U09:%x[-1,0]/%x[1,0]
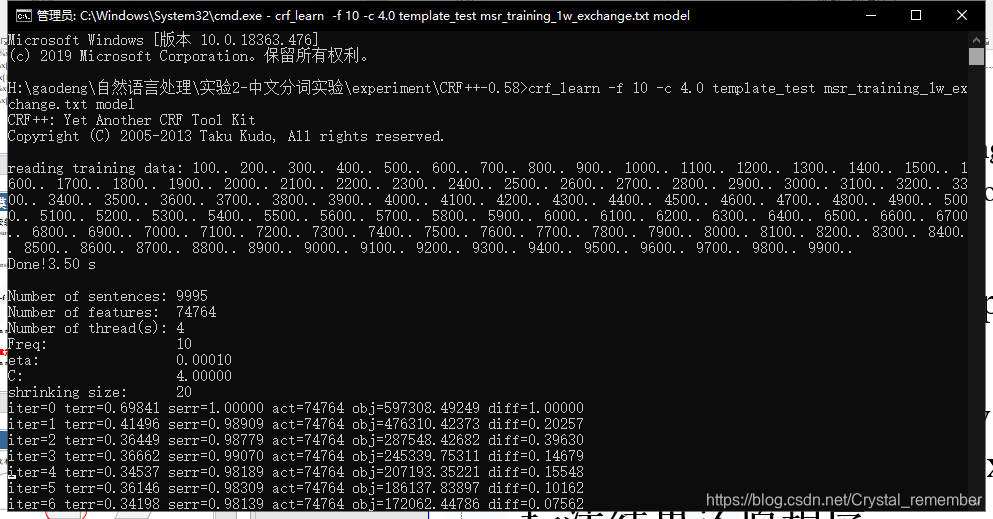
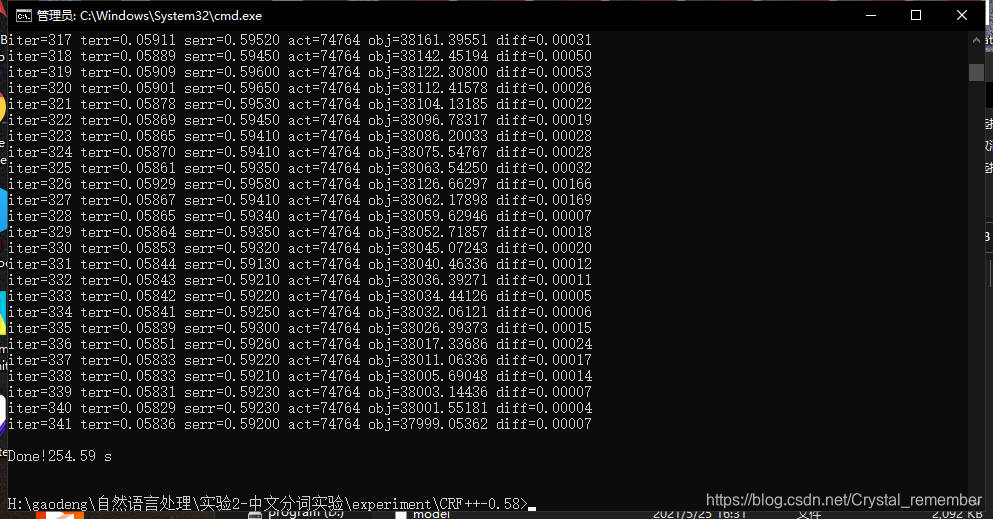
训练过程和结果如下:
使用命令为:
crf_learn -f 10 -c 4.0 template_test msr_training_1w.crf.txt model
测试结果如下:
使用命令为:
crf_test -m model msr_test_gold_test.txt
在另外数据集测试,追加输出重定向之后命令为:
crf_test -m model pku_test_gold_result.txt>>pku_test_gold_result_result.txt
结果如下:
生成文件如下:

(三)词位标注正确率统计程序开发
程序源代码如下所示:
# coding:utf-8
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--input_file", type=str, default="pku_test_gold_result_result.txt", help="The name of input file") #读取文件名称
opts = parser.parse_args()
input_file = opts.input_file
acc = 0
n = 0
with open(input_file, "r", encoding='utf-8') as f:
for line in f.readlines():
if len(line) > 2:
GT = line[2]
PRE = line[4]
if GT == PRE:
acc = acc + 1
n = n + 1
accuration = acc / n
print('the accuration is :', accuration)
测试结果如下:

(四)标注结果还原程序开发.
#coding:utf-8
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--input_file", type=str, default="msr_test_gold.crf.result.example.txt", help="The name of input file") #读取文件名称
parser.add_argument("--output_file", type=str, default="msr_test_gold_restore.txt", help="The name of output file") #写入文件名称
opts = parser.parse_args()
input_file = opts.input_file
output_file = opts.output_file
with open(output_file,"w") as ff:
with open(input_file, "r", encoding='utf-8') as f:
for line in f.readlines():
if len(line) == 6:
if line[4] == 'B':
ff.write(line[0])
elif line[4] == 'M':
ff.write(line[0])
elif line[4] == 'E':
ff.write(line[0] + ' ')
elif line[4] == 'S':
ff.write(line[0] + ' ')
flag = 1
else:
if(flag == 1):
ff.write('\n')
flag = 0
ff.close()
f.close()
print("写入成功")
写入结果如下所示:
(五)标注结果的分析
对比图如下所示:

可以看到,通过CRF预测后的分词结果与原文差异主要集中在一些频率较低的词汇,另外较长的词汇也无法正确区分,如中央人民广播电台 、邓小平理论 等词汇。
(六)修改训练过程的参数配置
通过官方文档,可对其中的参数c和f进行调整来提升正确率。由于时间原因,测试的密度不足,且范围不大。
训练数据集为msr_training_1w.txt
测试数据集为pku_test_gold.txt
实验的参数调整表格为:
| 模型编号 | c | f | 准确率 |
| model1 | 2 | 4 | 0.342785 |
| model2 | 2 | 10 | 0.329013 |
| model3 | 4 | 10 | 0.329013 |
| model4 | 4 | 4 | 0.342826 |
| model5 | 4 | 1 | 0.342826 |
| model6 | 2 | 1 | 0.342826 |
由于训练集和测试数据集相差较大,整体准确率比较低。通过表格看出,在f较低时,其准确率较高。另外,在f较低时,准确率没有变化。在f=10时,不同的c产生的准确率竟然也相同。
(七)分词正确率的计算
分词正确率的计算,可以统计正确词位标签的开始,即标签为“S”的字,及其到结尾“E”的长度,将这两个字段在分词模型的结果中进行比对。相同则分词的正确数加一,最后除以正确词位标签中S的个数即可
附录
实验过程中的数据,代码和模型、中间结果等。准确率复现脚本(windows,本机环境python3.6)
链接:https://download.csdn.net/download/Crystal_remember/19323619
转载载明出处:https://blog.csdn.net/Crystal_remember/article/details/117457268


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











