






阿里
1、SpringBoot与Spring区别
2、Aop应用
3、服务治理
4、微服务划分
5、微服务调用
6、10个线程实现10000个数的相加
// 使用countDownLatch
public class CalculateThread {
private int[] sum = new int[10];
public void calculate(int start, int sumIndex, CountDownLatch countDownLatch) {
for (int i = start; i< start+100; i++) {
sum[sumIndex] += i;
}
countDownLatch.countDown();
}
public int getSum() {
int ret = 0;
for (int i =0; i<sum.length; i++) {
ret+= sum[i];
}
return ret;
}
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(10);
CalculateThread calculateThread = new CalculateThread();
for (int i = 0;i < 10; i++) {
final int j = i;
new Thread(new Runnable() {
@Override
public void run() {
calculateThread.calculate(j * 100, j, countDownLatch);
}
}).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(calculateThread.getSum());
}
}
8、两个不同长度的链表相交,求交点
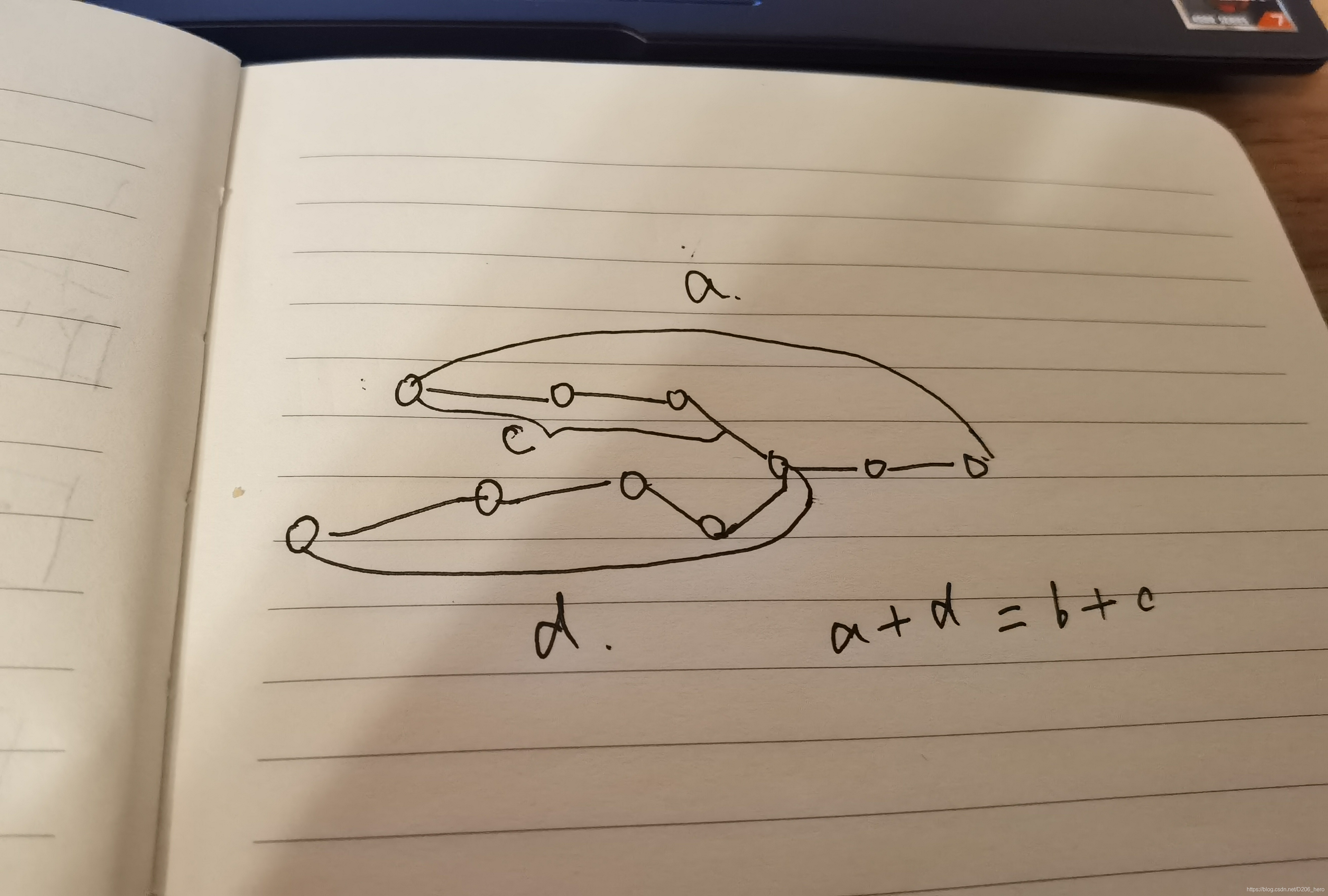
- A长度为 a, B长度为b, 假设存在交叉点,此时 A到交叉点距离为 c, 而B到交叉点距离为d
- 后续交叉后长度是一样的,那么就是 a-c = b-d -> a+d = b+c
- 这里意味着只要分别让A和B额外多走一遍B和A,那么必然会走到交叉,最后为交叉点为空说明两个没交叉,最后交叉点不为空则说明有交叉
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode currentA = headA;
ListNode currentB = headB;
while (currentA != currentB) {
currentA = currentA == null ? headB : currentA.next;
currentB = currentB == null ? headA : currentB.next;
}
return currentA;
}
}
快手
1、静态内部类和内部类的区别
- 可以对比静态属性和非静态属性来理解
- 内部类
- 内部类可以无条件访问外部类的属性和方法(包括私有的),外部类在访问内部属性和方法时必须先创建一个实例
- 创建内部类实例的时候必须先创建一个外部类实例
- 内部类不能定义static元素和方法,但是允许static final常量
- static 内部类
- 是内部类的一个特例,一旦内部类被static修饰则该类变成了顶层类,只能访问外部类的静态属性和方法
- 可以直接创建静态内部类的实例
- 可以在内部定义static元素
2、LinkedList的底层实现是啥, ArrayList的底层实现,两者各自优缺点
- linkedList底层实现是双向链表,内部主要维护first和last两个节点,非哨兵节点,插入删除效率高,索引方式查找时会判断index是否大于链表长度的一半,如果大于从后向前找,如果小于从0向后找
- ArrayList底层是一个数组,默认初始化大小是10,当添加元素达到数组现有大小后会按1.5倍来扩容,并拷贝原来的数据
- linkedList插入和删除元素效率很高,只需要修改链表元素的指针即可,而ArrayList需要整体移动元素,效率很低
- ArrayList按索引查询时效率比LinkedList高
3、MySql为什么习惯用自增序列作为主键
innoDB存储引擎在选择聚簇索引时的顺序是这样的:如果有主键选用主键,如果没有选用唯一且非空的字段作为聚簇索引,如果都没有则自己生成一个Row_ID作为聚簇索引,使用自增序列不使用uuid是这样考虑的:
- uuid是一般字符串比较长,比较占用空间
- 自增序列插入效率高:插入数据可以顺序写入;如果不是自增的,则可能导致大量页分裂和页移动,还有可能写入的目标页已经写入到磁盘中而不仅仅是在内存中,又或者目标页还没有被加载到内存中,这样会导致IO操作,效率低下
4、手写一个阻塞队列
// 参考:https://zhuanlan.zhihu.com/p/64156753
public class BlockQueue {
private List<String> dataContainer;
private int size;
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public BlockQueue(int size) {
this. size = size;
dataContainer = new LinkedList<>();
}
public void put(String element) {
lock.lock();
try {
while (dataContainer.size() >= size) {
condition.await();
}
dataContainer.add(element);
condition.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public String pop() {
lock.lock();
String element = null;
try {
while (dataContainer.size() == 0) {
condition.await();
}
element = dataContainer.get(0);
dataContainer.remove(0);
condition.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
}
finally {
lock.unlock();
}
return element;
}
}
4、谈谈你对泛型的理解
- 泛型即参数化类型, 分为 泛型类、泛型方法、泛型接口, 泛型类型变量不能是基本数据类型,因为擦除后是以Object代替原来的类型T的
- 泛型只在编译阶段有效,编译时先检查代码中泛型的类型,编译之后程序会擦除泛型,泛型信息不会进入到运行时阶段,因此我们可以利用反射来给我们定义好的list添加任意类型的元素
public static void main(String args[]) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException { ArrayList<Integer> array=new ArrayList<Integer>(); // 这样调用add方法只能存储整形,因为泛型类型的实例为Integer array.add(1); // 通过泛型可以突破泛型类型约束 array.getClass().getMethod("add", Object.class).invoke(array, "asd"); for (int i=0;i<array.size();i++) { System.out.println(array.get(i)); // 如果这里这样定义, 会报类型转换的错误,编译器在这里自动插入int的强制类型转换 // int a = array.get(i); } // 这段代码不会报任何的错 } - PECS原则(Producer Extends Consumer Super)
- 频繁往外读取内容的,适合用上界Extends。
- 经常往里插入的,适合用下界Super。
- 参考文章:
- https://blog.csdn.net/sunxianghuang/article/details/51982979
- https://segmentfault.com/a/1190000005179142
京东
1、10亿条数据怎么排序,以及10亿条数据找出TOPN的数据
- 10亿条数据排序:
2、对分布式事务的理解
3、谈谈对spring的ioc和AOP的理解
4、volatile的底层实现
5、redis的缓存击穿、缓存雪崩怎么解决
6、秒杀系统应该考虑哪些问题
7、spring中的事务是个什么样子的
8、Redis单线程为什么这么快
- Redis是内存数据库,操作内存比IO本身就快
- 单线程可以避免线程之间的切换耗费时间,而且Redis本身耗时的动作是在IO操作上,高版本的Redis的IO是多线程的
9、Redis持久化的方式和每种方式的优缺点
10、2.X版本后Redis不再使用zookeper作为注册中心的优缺点
11、常见排序算法及其稳定性
- 排序稳定性:对于任意两个相等的元素排序前和排序后的相对顺序不变,称为该算法是稳定的
- 稳定排序:插入排序、冒泡排序、归并排序(nlogn)
- 非稳定排序:快排(最坏n方,最好nlogn)、堆排(nlogn)
12、水平触发和边缘触发
13、负载比较高怎么排查
14、CAS一般的应用场景
小红书
1、Redis大的key怎么删除
2、Redis某个热key访问量达到 8 9万以上怎么解
3、MySql的索引覆盖和索引下推
- 索引覆盖:在一棵B+Tree上就可以获得SQL所需的所有列的数据:使用联合索引替换单列索引,可以避免回表
- 索引下推:没有索引下推优化的时候,当进行索引查询时,先根据索引来查找记录,然后回表根据where条件过滤;当有索引下推优化的时候,在根据索引条件查询的时候(一般是联合索引)如果可以就直接进行where条件过滤了,减少回表次数
- 参考:https://www.jianshu.com/p/d0d3de6832b9
4、MySql的幻读和可重复读的怎么解决
- 可重复读:主要是靠MVCC来实现的:undolog + ReadView + 3个隐式字段
- 幻读:主要是靠临建锁来解决的
5、线程池各个参数的意义,以及等待队列使用LinkedBlockQueue和ArrayBlockedQueue的应用场景
- 核心线程数、最大线程数、keepAliveTime, 阻塞队列
- keepAliveTime 说的是非核心线程数处于空闲时间后会被回收,核心线程也可以被回收,但是要设置 allowCoreThreadTimeOut
- 阻塞队列的设置
- ArrayBlockingQueue: 有界缓存等待队列,可以指定大小,当正在执行的线程数等于核心线程数的时候
- LinkedBlockingQueue:如果不指名大小是无界缓存队列,当执行任务的线程数量达到核心线程数后,剩下的任务会放在无界阻塞队列中,此时最大线程数是无效的
- 关闭线程池的2种方法:
- shutdown: 不再接收新的任务,但是线程池中的任务会执行完
- shutdownNow:杀掉线程池中正在执行的任务,并返回尚未执行的任务列表
金山云
1、熔断、降级、限流
- 熔断:当服务A调用下游服务B的时候,B由于某些原因接口没响应,导致A服务调用接口一直超时,当超时次数达到一定阈值后A停止调用B的接口,直接使用MOCK的数据,熔断器有阿里的Sentinel或者hystrix
- 限流:当A大并发调用B的时候,B可以限制A的流量上限,同一时间设定固定的线程数量来支持A的调用
- 降级:保住核心业务,将非核心业务关闭或者简化掉
- 参考: https://www.cnblogs.com/qianjinyan/p/10816952.html
2、大表怎么添加索引
- 如果是主从的话,可以先把从机停掉,先给从机上添加索引,然后把从机起来,主从切换,然后再在原来的主机上添加索引
- 如果只有一个实例的话:找业务不忙的时候添加索引
3、Spring的事务
4、什么情况下会线程不安全
5、hashMap什么情况下会线程不安全
6、String从一个json中读取是放到常量池中么
7、百万数据分策略怎么分
8、 Redis的Zset的底层实现原理
9、水平分表的底层实现原理
10、http包里面都包含什么
11、怎么看某个服务当前的连接状态
12、G1垃圾回收器的安全点
百度
1、为什么要分代
优化GC性能, 假如不分代的话,每次GC都要全堆扫描,这样效率很低;大部门的对象的生命周期很短,当使用分代模型之后把朝生夕死的对象放到某一个地方,发生GC后就可以腾出很大的空间。
2、kafka的使用场景
削峰填谷、服务之间进行解耦、方便扩展应用
3、redis常见数据结构底层的实现
- String: 使用SDS来实现的,简单动态Str,其实就是一个结构体,然后里面有char型数组,还有标志数组存储的元素的个数的变量、还有数组的未使用的字节数量
- List:底层实现是一个双向链表
- 参考:https://www.cnblogs.com/ysocean/p/9080942.html
4、大对象为什么直接放到老年代
- 如果放到年轻代的话,来回复制会消耗很多的时间(对象大 + GC频率高)
- 放到年轻代首先会加快Edgen区GC的频率,假如大对象躲过了GC放到了surivor区,surivor区本来就小,这样surivor能放的对象就变少了,迫使对象放到老年代,这样就会加快老年代的GC
5、JDK目前最新的版本是什么
JDK16、JDK9垃圾回收器默认使用的是G1
滴滴
1、hashMap的底层实现
- hashMap底层是数组加链表来实现的,JDK1.8中当链表长度达到阈值8之后会变成红黑树
- 各个参数值:装载因子:默认0.75;数组初始化大小:16;扩容时是以2倍原来容量来扩容的
- jdk1.7头插法出现环形链表:
- 出现环形链表主要是在transfer方法中,参考:https://xw.qq.com/cmsid/20200825A0O09T00
- hashMap在JDK1.8中做了哪些优化
- 1.7是使用数组+单向链表, 1.8是用的是数组+单向链表+红黑树,链表长度达到阈值8时转化成红黑树
- 计算Hash值的时候,1.8中hashcode的高16位参与了运算,异或hashcode
- 1.7使用的是头插法,1.8使用的是尾插法,1.7并发情况下容易出现循环链表
- 1.7中计算索引位置时用的是hashCode & length-1, 1.8用的是扩容前的位置+扩容的大小值
- 1.7 是先扩容后插入, 1.8是先插入后扩容















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









