









1.前言
3D点云数据的一些主要问题可以体现在其(1)稀疏性(2)无序性(3)冗余性三个方面。
对于稀疏性,现有的一些方法喜欢引入体素(Voxel)进行三维空间的划分,然后将稀疏、无序,分布不均匀的点云数据分配于不同的体素,接着利用MLP、卷积、池化等操作实现对体素(点云)进行特征提取,很明显这种方法会引入大量的计算量。
考虑到这一点,本文要解析的MV3D并没有使用类似的方法,而是将点云数据和图片数据映射到三个不同的维度进行特征融合,然后进行物体的定位和识别。
这三个维度分别为:点云的俯视图、点云的前视图以及图片。这里值得注意的,作者融合了点云数据和图片数据,说到底,这就是一个多模态融合的问题。
MV3D的论文地址为:https://arxiv.org/abs/1611.07759
MV3D的代码地址为:https://github.com/bostondiditeam/MV3D
2. MV3D的点云处理
上面提到MV3D将点云和图片数据映射到三个维度进行融合,从而获得更准确的定位和检测的结果。这三个维度分别为点云的俯视图、点云的前视图以及图片,如下图所示。
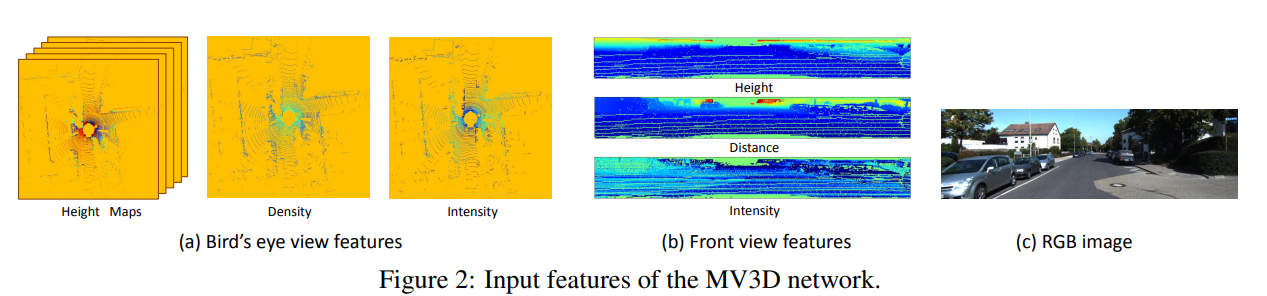
(1)点云俯视图
点云俯视图由高度、强度、密度组成。
高度图的获取方式为:作者将点云数据投影到分辨率为0.1的二维网格中,将每个网格中所有点高度的最大值记做高度特征。为了编码更多的高度特征,将点云被分为M块,每一个块都计算相应的高度图,从而获得了M个高度图。
强度图的获取方式为:仍然是分辨率为0.1的二维网格中,找到每个网络中具有最大高度的点云的反射强度,构成1个强度图。
密度图的获取方式为:统计每个单元中点云的个数,并且按照公式
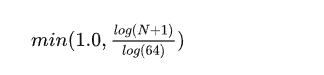
进行标准化,其中N为单元中的点云个数,构成1个密度图。
那么点云俯视图的维度为 (
M
+
2
M+2
M+2,
W
W
W,
H
H
H)
(2)点云前视图
如果直接将点云的前视图映射到图像平面,会非常稀疏。因此作者将三维点 (
x
x
x,
y
y
y,
z
z
z) 映射到一个柱平面 (
r
r
r,
c
c
c)上。计算公式如下:

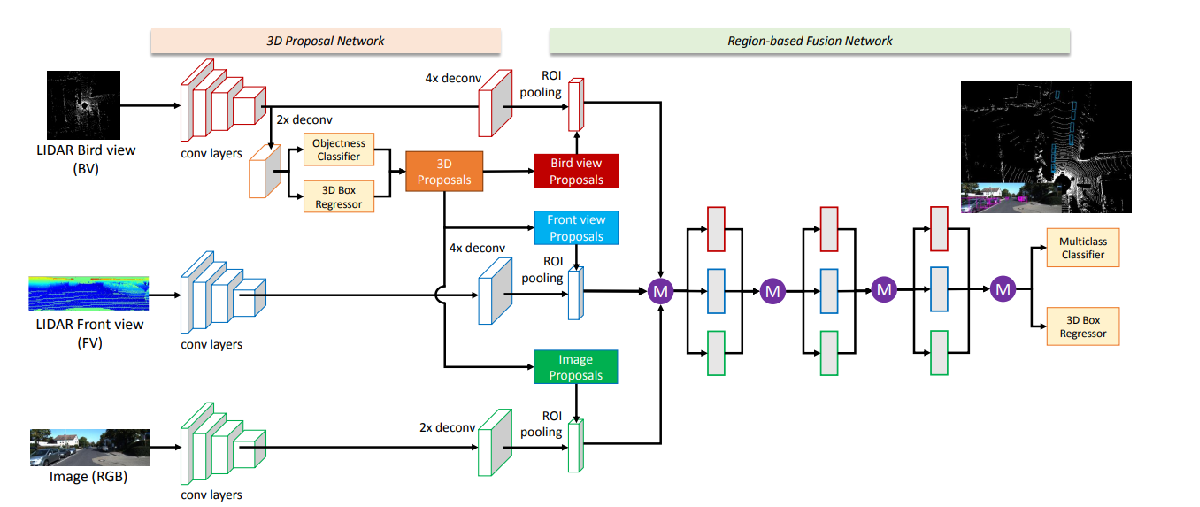
3. 网络结构图
具体的网络结构图如下所示。
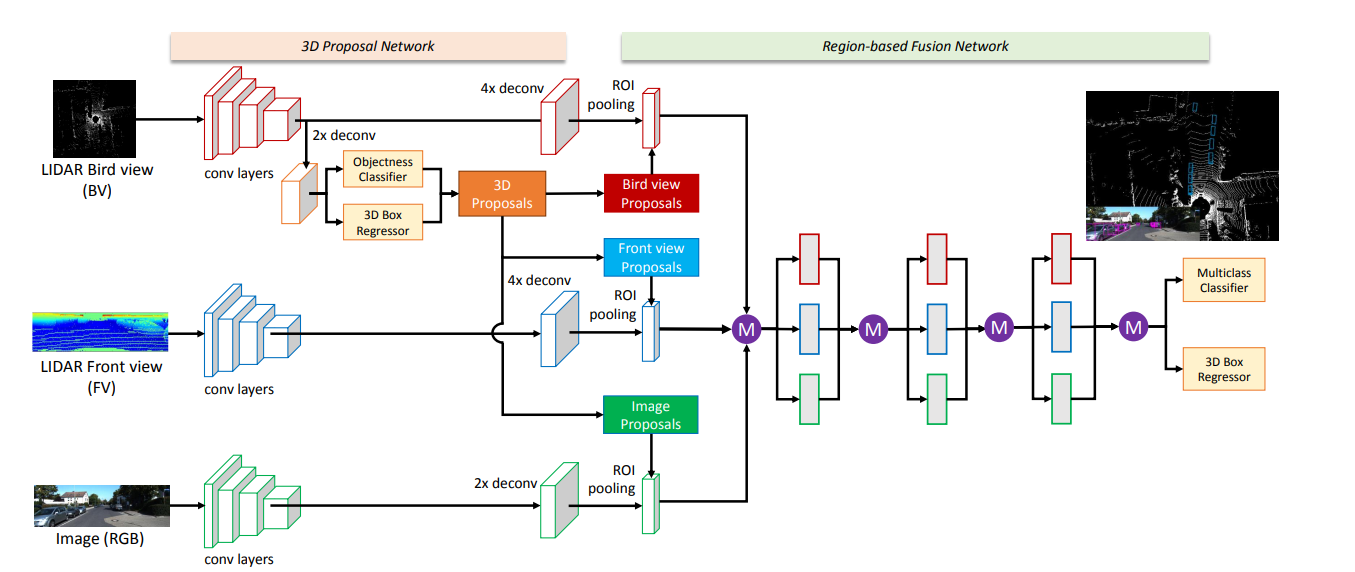
可以,该网络结构主要由两部分组成,分别为3D proposal Network和Region-based Fusion Network。
(1) 3D proposal Network
3D proposal Network有三个输入分支,分别以上面提到的点云的俯视图、点云的前视图以及图片为输入,通过CNN网络(文中用的VGG),获得三个特征图。
值得注意的是,与另外两个分支不同的是,作者从以俯视图为输入的特征图中获取了3D proposal。至于为什么这么做,作者在原文中提到:
In 3D object detection, The bird’s eye view map has several advantages over the front view/image plane. First, objects preserve physical sizes when projected to the bird’s eye view, thus having small size variance, which is not the case in the front view/image plane. Second, objects in the bird’s eye view occupy different space, thus avoiding the occlusion problem. Third, in the road scene, since objects typically lie on the ground plane and have small variance in verticallocation, the bird’s eye view location is more crucial to obtaining accurate 3D bounding boxes. Therefore, using explicit bird’s eye view map as input makes the 3D location prediction more feasible.
很明显,从俯视图为输入获得的特征图中进行3D proposal有三点原因。简单来说,就是(1)保持了物理形状(2)不会发生遮挡和重叠(3)获得的3D检测框更准。
而且,BEV视角只能获取二维的检测框,如何生成三维的检测框呢?
答案也很简单,作者提到:
and z can be computed based on the camera height and object height.
也就是三维检测框的高度其实就根据物体高度(二维检测框内最高点云对应的高度)与相机高度求解获得,实际上应该是两者相加即可。
接下来的3D proposal过程和FasterRCNN中的RPN类似,只不过从2D proposal升级到了3D proposal,主要分为物体分类(应该是分前景和背景)以及3D BBox回归两个过程。
其中,3D BBox回归结合了一些预先设定的3D Prior Boxes(也就是Anchor),然后进行回归学习。学习的参数从3D Prior Boxes到GT-BBoxes的变换过程,也就是八个变化参数(长方体的八个角点)。

(2)Region-based Fusion Network
上面的3D proposal Network获取了一系列的3D检测框,作者将这些检测框映射到3个不同视角,分别为俯视图、前视图和图片视角。
这样的话,就有了3个不同视角的proposal了。作者用这3个不同视角的proposal分别从俯视图、前视图和图片中获得相应的ROI区域。为了更好地融合来自不同视角的ROI,作者将所有获得的ROI通过ROI pooling得到等长的特征表示,如下图所示。
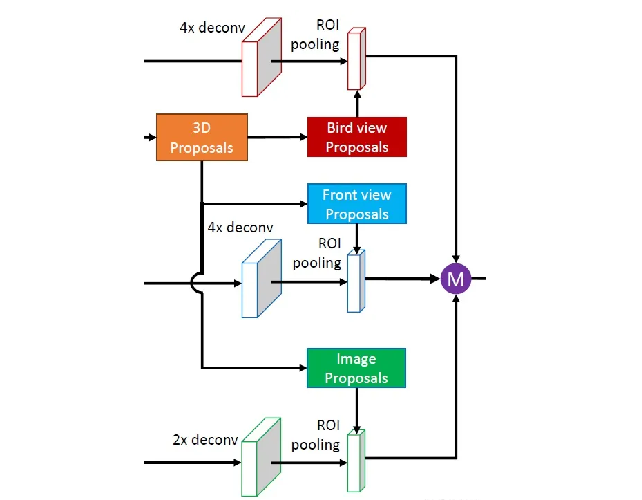
获得不同视角的ROI后,下面要做的就是特征融合了。
作者介绍了三种不同的融合方式,分别为
(1)Early Fusion
(2)Late Fusion
(3)Deep Fusion。各自的结构如下图所示。
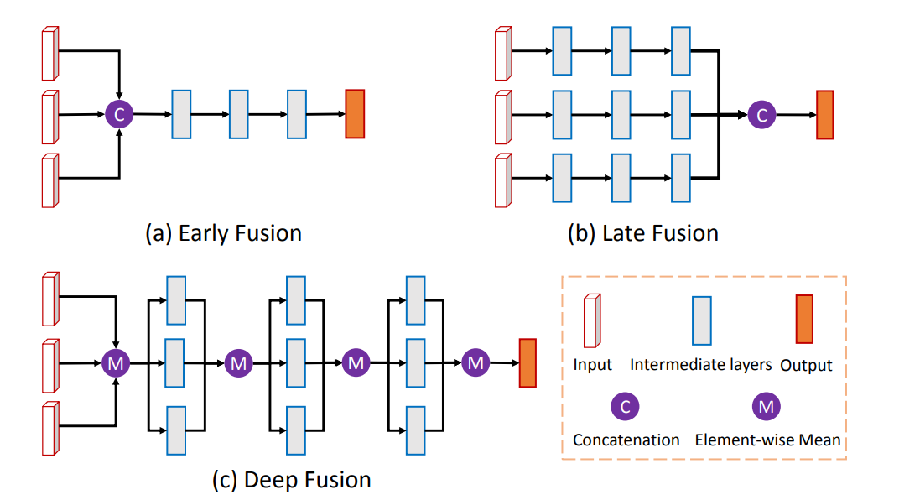
本文中作者选择了Deep Fusion。融合的特征用作
- 分类任务(人/车/…)
- 更精细化的3D Box回归(包含对物体朝向的估计)
这两个任务的输入。
至此,MV3D的网络结构解析就完毕了。
有关损失函数的解析,本文用到了交叉熵用于分类任务,smooth L1用于回归任务,比较简单,就不展开来说。
4. 正负样本的设置
MV3D是双阶段的目标检测方法,有两个分类任务(RPN的前景、BEV、照片的proposal和偏执分类,以及网络最后的类别分类)和两个回归任务。
这里很多解析类文章都没有注意到一点的是,作者在正负样本的设置上还有点技巧。
在RPN中Anchor的正负性设置来说,作者提到
During training, we compute the IoU overlap between anchors and ground truth bird’s eye view boxes. An anchor is considered to be positive if its overlap is above 0.7, and negative if the overlap is below 0.5. Anchors with overlap in between are ignored.
也就是从俯视角度看,IOU大于0.7的Anchor被视为positive,低于0.5视为negative;Anchor的正负性用来决定该Anchor是否参与RPN回归任务损失函数的计算。
在网络最后回归层中3D proposal 的正负性设置来说,作者提到
During training, the positive/negative ROIs are determined based on the IoU overlap of brid’s eye view boxes. A 3D proposal is considered to be positive if the bird’s eye view IoU overlap is above 0.5, and negative otherwise.
也就是从俯视角度看,IOU大于0.5的3D proposal 被视为positive,低于0.5视为negative;3D proposal的正负性用来决定该3D proposal是否参与网络最后回归任务损失函数的计算。















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









