







上一篇遇到的达梦数据库宕库问题,最终分析的结论虽然是操作系统SWAP区耗尽导致,与达梦数据库无关,但是根本原因是什么,以及以后如何规避类似问题,是更为重要的问题。老白在昨晚调整了达梦数据库的健康模型以及操作系统空闲内存过少那个运维经验的触发条件,这些调整能否在今后系统运行的过程中发挥作用,规避类似宕库事件的再次发生吗?
带着这个问题,我们在一个测试环境中继续进行跟踪。我们选择了一个装了MYSQL,Oracle等多个数据库的环境中模拟SWAP耗尽的现象。
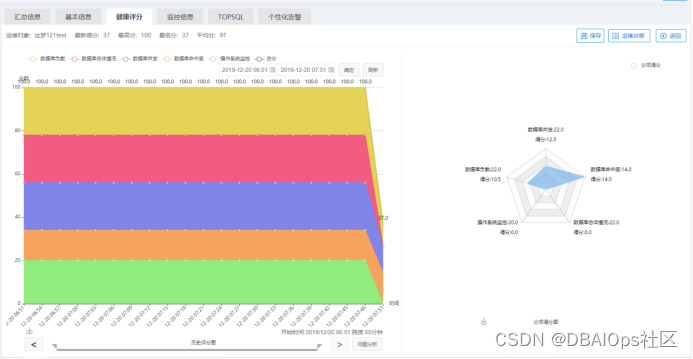
很快调整后的模型发挥了作用,当SWAP使用率很高的时候,达梦数据库的健康分明显下降,我们很快捕获到了这个问题。
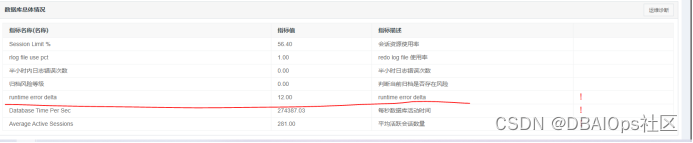
同时我们也看到达梦出现了runtime error的情况。这些现象都是和昨天下午的那个宕库现象是完全一致的。查看告警界面,内存不足告警的运维经验也发挥作用了,虽然内存不足报警的底线是200M,但是由于SWAP使用率超过了我们设定的85%的阈值,所以运维经验告警已经被推送到告警台上:

几分钟后,观察操作系统,发现SWAP已经耗尽了,但是free内存还有1.4G左右,AVAILABLE的内存有接近2G。

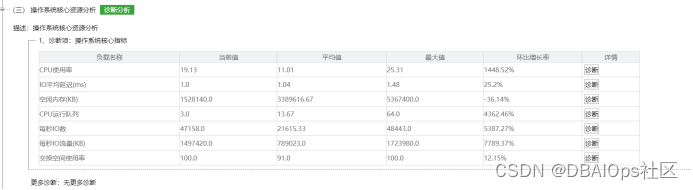
通过“核心操作系统资源”诊断工具,我们可以看出交换空间使用率达到100%。
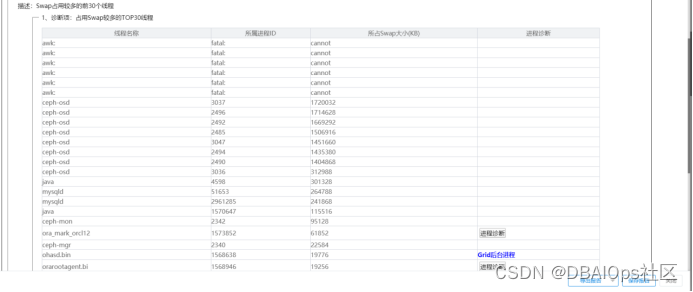
进一步下钻分析,发现ceph,JAVA,MYSQL等消耗了较多的SWAP空间。
正在分析的时候,我们发现达梦数据库出现了宕库现象。幸运的是,这回我们在message日志里看到了明确的信息,由于SWAP耗尽,oom killer主动杀死了达梦的服务进程dmserver。这就是达梦数据库宕库但是数据库日志中没有任何信息的原因。整个达梦服务进程被直接kill掉了。由于达梦是单进程多线程架构的,一旦服务进程被杀掉,连写日志的机会都没有(Oracle是多进程机制,总有一个进程会有机会写入一些告警信息)。
![]()
这次模拟完美的解释了昨天下午的那个宕库事故。LINUX操作系统是真正的幕后杀手。为什么LINUX oom killer会杀掉达梦,而不去杀系统中的ORACLE,MYSQL呢?我们首先需要了解oom killer是如何工作的,oom killer是LINUX 为了确保系统的内存资源不耗尽而设置的一个守护进程,当系统内存不足时,选择oom score分数最高,并且占用内存资源较多的进程,主动杀掉该进程,确保操作系统不会彻底死掉。在本系统中,Oracle由于是多进程模式的,空间使用比较分散,因此Oracle相关进程的oom score并不高,不存在被杀掉的可能。Mysql数据库上面没有什么负载,所以oom score一直在5-8之间徘徊。Dmserver在没有负载时oom score大约在12左右,但是当压测启动后,很快突破100,达到140+,成为本系统中oom score最高的进程。于是oom killer就会首选dmserver了。
搞清楚了oom killer杀人的机制,那么我们下一步就可以设计针对达梦的保护方案了。将dmserver的oom_score_adj设置为-1000后,dmserver的oom_score就永远是0了,于是达梦数据库就不会被杀掉了(对于早期一点的Linux版,将oom_adj设置为-17达到的是同样的效果,在7.4上面直接设置oom_adj为-17,系统自动会将oom_score_adj设置为-1000)。
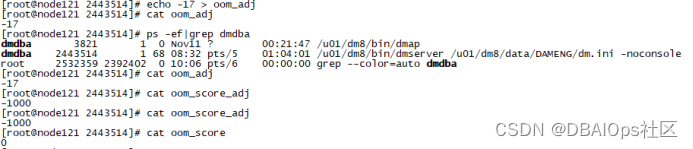
设置完参数后,我们继续加压,直到服务器连登录都十分缓慢,达梦数据库的性能已经下降了一半以上了,但是oom killer也没有杀掉dmserver,数据库再也不会宕机了。至此,此问题基本解决。

















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









