







Polardb是阿里这两年宣传的比较多的数据库产品。在阿里云上有RDS FOR POLARDB的产品,分为-X、-O和-PG三个引擎。虽然阿里没有怎么宣传这三种引擎的来源,不过根据其使用特性来看,-X是基于Mysql引擎的,-O、-PG是PostgreSQL引擎的。-O主打与Oracle语法的兼容性,-PG基本上和社区版PostgreSQL的语法完全兼容。目前PolarDB也提供线下的版本,可以脱离阿里云独立部署。部署架构如下:
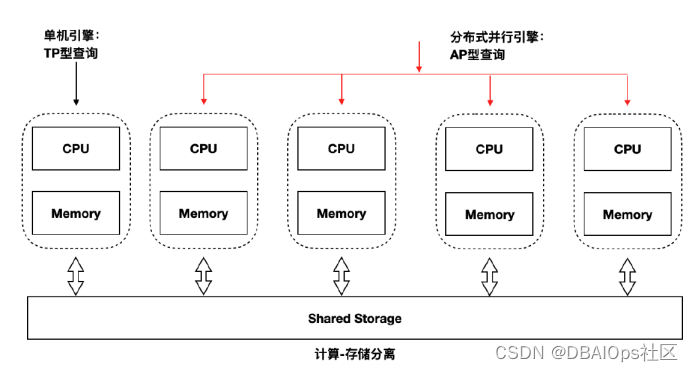
PolarDB是采用计算存储分离的模式,有点类似与Oracle的ASM,不过PolarDB的底层存储是自己的分布式文件系统PolarFS,计算节点与PolarFS分布式存储之间通过RDMA高速互联。今天我们关注的重点不是PolarDB的基础架构与基本原理,而是重点讨论一个PolarDB的比较有趣的功能,基于共享存储的读写分离技术。
现在很多开源与国产的数据库产品支持读写分离,不过这些数据库一般都是采用数据库复制技术来实现的,而PolarDB采用了一条特殊的技术路线,使用共享存储的读写分离技术,这个路线和十年前Sybase的共享存储集群技术类似。读写实例与只读实例共享同一套数据库文件,整个集群中只有一个读写实例,其他都是只读实例。如上图,左侧是一个独立的可读写的实例,右侧的几个只读实例组成一个共享存储的并行数据库集群。一个大型查询可以分布在多个实力上并行执行,从而满足一些HTAP类的应用需求。具体这个并行只读引擎的效果如何,没有测试过,并不清楚,从阿里自己宣传的资料来看效果还是不错的。
采用这种共享存储模式的读写分离数据库方案,我们常见的通过数据同步/准同步复制实现的读写分离还是有一定的优势的,那就是数据不需要复制,因此一切与数据复制相关的读写分离方案的缺陷都可以避免。不过这种方式也存在一定的问题,那就是必须对RDBMS的核心进行一定的改造,并且读写实例与只读实例之间仍然存在一定的串行化同步的问题,或多或少主实例还是会受到一些只读实例的影响。在一些客户的使用过程中,也遇到过一些只读实例导致主实例事务HANG住的问题。
PolarDB-O是基于PostgreSQL的,因此要让只读实例共享读写实例的数据文件,首先要解决的一个问题是要让PostgreSQL支持DIRECTIO,因为如果某个缓冲在数据库层面写盘了,而实际数据并没有被写入磁盘,还在主实例的内存中,那么只读实例从文件中读出的数据块就可能是老的。
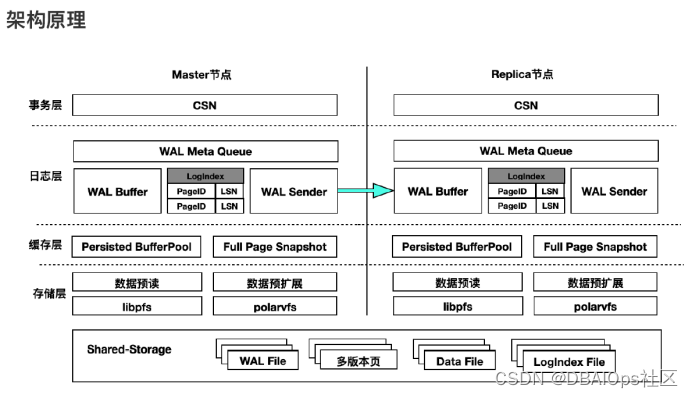
针对具有缓冲机制的多节点数据同步,大家可能很容易想到Oracle著名的Cache Fusion,缓冲区融合。通过缓冲区融合可以比较方便的实现多个实例之间数据一致性视图的问题。PolarDB并没有使用类似缓冲区融合的技术,而是使用了一个基于WAL重演的数据同步机制。其主要原理是在主实例上设置了一个WAL Sender服务进程,负责把WAL变化量的元数据发送到复制节点的Wal Buffer里。通过磁盘上的老数据加上WAL回放的方式来获得某个PAGE的最新状态。
如果当前的共享存储中的某个PAGE不是最新的,也就是说是我们需要的PAGE的过去页面,那么根据内存中Wal Buffer中存储的元数据,我们就可以让这个PAGE的数据重演,得到应用所需的时间点的页面。为了具备这种重演能力,就需要在内存中保存变更页面的修改链的全部数据,如果某个PAGE很长时间都没有被写盘,那么大了的WAL METADATA数据就不能丢弃,因此WAL BUFFER有不够用的可能,因此阿里设计了LogIndex File,用于持久化WAL Buffer的数据。
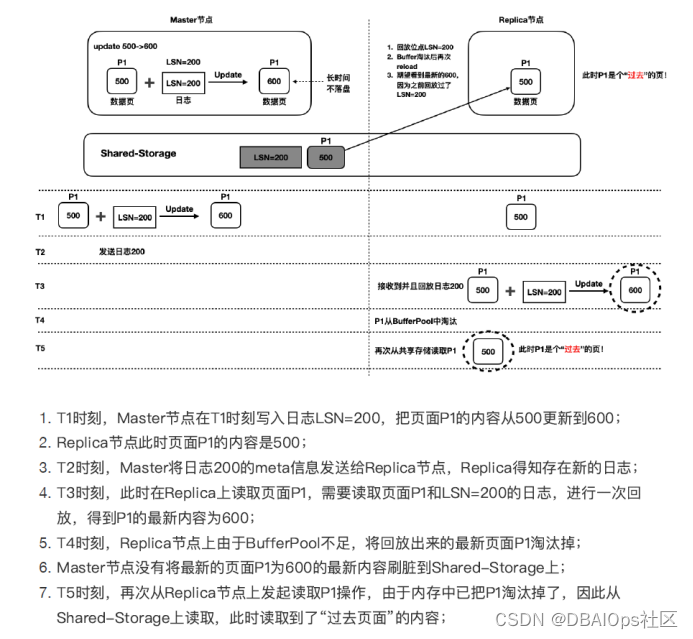
上面的例子就是一个页面回放的案例。除了共享存储上有过老的页面的问题,还有一种可能性是页面过新的问题。
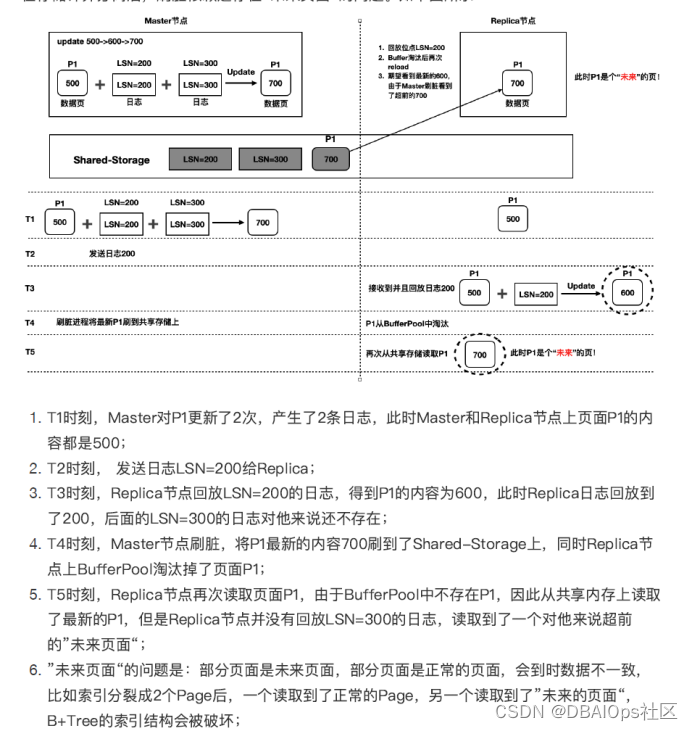
如果Replica还没有回放到某个日志的位置的时候,某个PAGE先被写回了共享存储,那么我们从共享存储中读到的数据是超出当前Replica已经回放的范围的,因此会出现数据逻辑错误。PolarDB为了解决这个问题,引入了PAGE的版本机制,当出现此类情况的时候,通过保存多个PAGE的版本来解决这个问题。
从上面的情况看,PolarDB在复制回放的问题上确实解决了具有BUFFER CACHE的环境下的两个重要的一致性问题。不过从资料上我们还是看出PolarDB在实现读写分离上,依然是从Master-Replica的角度来考虑问题的。虽然采用了共享存储机制,不过依然将读写分离机制设计为一个逻辑上的主从复制结构,这也导致了共享存储只是被作为数据块的基准数据,而不是当成数据库本身,而只读库本身要依赖于主库和LogIndex以及数据页的版本库,在逻辑上是分离的。
在这种架构下,只读实例中的所有数据都是需要经过在从库中重演才对应用可见的。在某些高负载中,这种重演会带来巨大的浪费,也会导致某些大并发数据变更的情况下,主库与从库之间的差异过大。比如说某个数据被大量修改过,不过读业务并不马上就需要这个数据,在T+100的时候才需要这个数据,那么前面的99次重演对于这个应用来说是没有用的,不过为了确保数据的一致性,重演不能跳过这些不需要的变更。这种重演算法存在的缺陷,也会导致某些特征的应用常见下,PolarDB的读写分离机制可能会导致因复制重演而产生的性能问题出现,甚至是主库在某些场景下也可能因为从库重演中遇到的一些性能问题而出现性能问题。
这种重演的思路是从以前的share nothing结构中学来的,而实际上share everything的架构中,完全可以采用一种不同的思路。我觉得在这种架构中,缓冲区融合的效率要高得多。我们先来看看这种结构可能存在的一些问题(不是产品的开发人员,某些实现算法只是猜测,因此总结的这些问题可能不准确):1)为了便于从库的重演,需要主库的bgwriter等在脏块写入算法上做调整,可能会影响主库checkpoint的性能;2)页面版本库与LogIndex带来的额外开销;3)从库可能出现较大的延迟;4)多个从库可能重演速度不一致,导致多个从库做分布式并行查询时候,还要判断各个从库重演的延时问题。
如果要用缓冲区融合的思路重新设计PolarDB的主从一致性问题,Wal Buffer的思路是不错的,用于缓冲区融合也十分好,主实例实时将Wal Buffer发送到Replica实例,如果Replica实例的Cache中这个PAGE在DB CACHE中,那么,就只需要标注一下这个Page有更新的版本就可以了。如果这个Page根本不在DB Cache中,那么我们就不用管这个元数据变更了,此时数据可以丢弃,也可以暂时放在缓冲区中,此时也不需要做任何的重演。
当某个应用需要访问这个PAGE的时候,如果这个PAGE在缓冲区中存在,并且被标注为不是最新的,那么我们只需要通过一个服务去主实例的DB CACHE中拿就行了,如果主实例的DB CACHE中已经么有了,那么说明此数据已经写盘,那么再从共享存储中读取就可以了。如果这个PAGE在Replica的CACHE中没有,那么也先去主实例申请,如果申请不到,再读盘。
可能有朋友会说,这种方式会影响主实例,实际上,在现在的硬件条件下,主实例增加这点负载是完全没有任何问题的。减少了Replica重演对主实例CHECKPOINT放的一些束缚,可能完全可以抵消这些开销,甚至获得更好的性能。当然,我并不是PolarDB的研发人员,这种缓冲区融合算法是否适合目前的PolarDB,并不是很确定,因为这和数据库的底层实现,包括PolarDB是否已经真正实现了DirectIO,都有很大的关系,如果PolarDB并没有实现真正的DirectIO,那么缓冲区融合的算法会更复杂一些。
实际上数据库的研发比起普通的应用系统要复杂的多,主要是我们的研发团队可能不知道今后会面对什么样的应用场景,因此在我们设计底层架构的时候,往往无法针对更多的场景去做相关的考虑。我上大学的时候,陈道蓄先生就说过:“这世界上的所有好事都是有代价的,适用性与专用性是一对天生的冤家”。因此我们在设计某一种极致系统的时候,可能会忘掉它对另外一个极致的有效支撑。某个数据库会在哪些地方出现支持不佳的问题,有时候从其总体架构上就可以看出来了。
记得有一个金融级分布式数据库号称是一种HTAP的数据库。当时我就十分不解,其存储架构是LSM-TREE,这种存储结构对高并发的交易支持是很好的,但是对于复杂的海量数据查询的性能并不好,它如何很厚的支持HTAP场景呢?最近我的客户的几个测试中,我的疑问被证实了,最后数据库厂商也承认在这个数据库中写SQL要注意,不要针对大表写太复杂的多表查询语句。
















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









