







第二课
初识神经网络:
1、概念
激活--图中 a,指一个神经元向下游其他神经元发送的输出。

神经网络不需要手动设计特征,它可以自己学习选择合适的特征,我们只需要设计隐藏层数量和每层神经元数量。(重点理解!)
2、图片识别原理
训练一个神经网络,以图片所有像素的亮度值的特征向量作为输入,并得到输出

具体过程
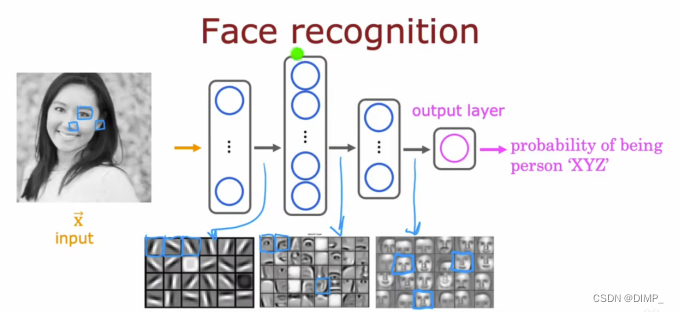
第一个隐藏层中,每个神经元在寻找图像中非常短的线条;第二个隐藏层中,每个神经元在学习把之前找到的短线条组合在一起,找到面部的一小块区域;第三个隐藏层中,每个神经元在聚合面部的不同部分,形成粗糙的面部形状。可以发现对应的原图像的区域越来越大。
3、神经网络各层相互作用的过程(重点掌握!)

4、向前传播
神经网络从左到右进行,且依次传播神经元的激活值。
这种最初有很多的隐藏单元,越靠近输出层,隐藏单元数量越少
代码表示

5、神经网络搭建
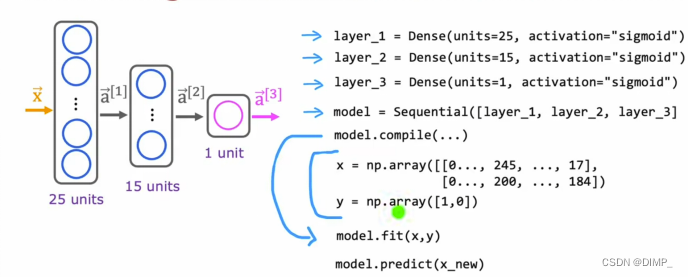

通过矩阵乘法,可以矢量化神经网络,效率提高

函数:
1、ReLU

2、选择激活函数
输出层:预测的标签 y 是什么
二分类问题,选择 sigmoid
y 可以取正值和负值的回归问题,选择线性激活函数
y只能取非负值的回归问题,选择 ReLu
隐藏层:一般选择ReLu,使用ReLu可以让梯度下降更快
3、Softmax
适用于多分类问题,即可能的输出为两个以上标签
公式
n = 2 时,softmax 回归化简为逻辑回归

4、回归代价函数

5、改进实现
舍入误差(理解!)
逻辑回归的改进实现
a 不作为中间项,而是使用展开的表达式, TensorFlow 想出一种在数值上更准确的方法来计算这个损失函数
改进代码能够将输出层的激活函数改成线性激活函数,TensorFlow 可以重新排列这个表达式中的项,使计算变得更准确

softmax回归的改进实现
神经网络输出变为z1——z10

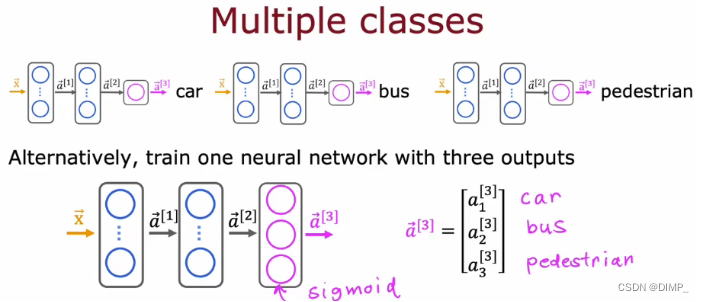
6、多输出分类
训练一个网络同时检测三种物体,相当于三个二分类问题
机器学习流程:
2、模型选择和训练/交叉验证
将数据集分为训练集、交叉验证集(验证集,用于检查不同模型的有效性和真实性)、测试集
选择合适模型:使用训练集拟合参数,使用交叉验证集选择模型,使用测试集估计泛化误差

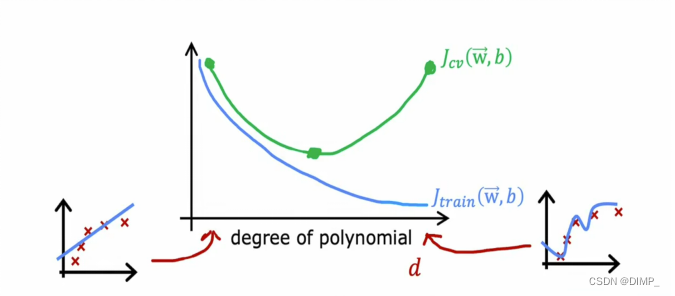
3、正则化和偏差/方差
多项式次数的增加,先欠拟合、后恰好拟合、最后过拟合,Jtrain 越来越低,Jcv 先降低后升高
计算不同 λ 值对应的 Jcv 值,选择最小的 Jcv 对应的 λ 值,将此时的 Jtest 作为泛化误差

神经网络可以摆脱了必须权衡偏差与方差的问题:
当神经网络足够大时,只要训练集不是太大,几乎总能适应训练集,唯一不足是会使速度减慢
高偏差问题需要使用更大的神经网络,直至在训练集上表现良好
高方差问题需获取更多的数据并重新训练
4、学习曲线
数据量增多,交叉验证误差下降,而训练误差会上升
当学习算法具有高偏差时,增加数据量不会降低训练误差
当学习算法具有高方差时,增加数据量会有帮助

5、错误分析
错误分析是一种诊断模型的方法,指手动查看出现错误的样例,并试图深入了解算法出错的地方(一般是按照共同的属性将他们分组)

6、迁移学习
迁移学习中,使用除输出层外的所有层的参数作为新神经网络参数的起点,然后运行优化算法,分为监督预训练和微调两步
训练神经网络参数的方法:
保持输出层以前的参数不变,只训练输出层参数(非常小的数据集)
以输出层以前的参数为起点,训练网络中的所有参数(稍大一些的数据集)
7、偏斜数据集的误差指标
偏斜数据集指的是正例和反例比例失衡的数据集
只用准确率来衡量算法是否有效通常是不可靠的
8、精准率和召回率的权衡
若使用逻辑回归算法,当提高阈值时,准确率提高,召回率降低;降低阈值时,准确率降低,召回率提高
根据不同的阈值我们可以画出精准率和召回率曲线
阈值选择方法:
手动选择阈值
可以定义一个指标,F1 分数*

决策树
1、模型
下图是一个二元分类任务,每个特征也只能取两个离散值

构造决策树是一个递归的过程

2、过程
在每个节点上选择合适特征进行拆分,尽量最大化纯度(重点理解!)
选择合适停止拆分:
分支只属于某一类
设定树的最大深度
拆分节点对纯度影响小
节点样本数低于某个阈值
2,3,4条确保树不会笨重,并且使它不太容易过拟合
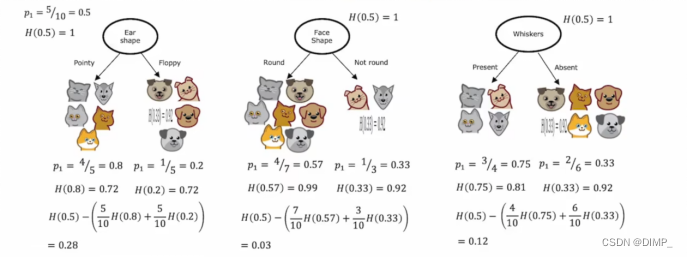
3、纯度
熵用来衡量数据的纯度,其公式如下
 此时的log以2为底
此时的log以2为底
熵是如何衡量纯度(重点理解!)
4、信息增益
熵的减少叫做信息增益。如果熵减少的太小,就要停止拆分,减少过拟合的风险
熵的计算
这里使用了加权平均,想一想为什么

5、编码方式
One-hot编码
特征离散取值为k个(大于两个),则可以创建k个二进制代替该分类的特征
适用于决策树,神经网络(使用 0、1 对特征进行编码,以便作为输入)

连续值特征
选择信息增益最大的阈值,根据阈值对数据进行分类
通常选择阈值的方法是,根据特征值大小对所有样例排序,取排序表中每两个连续点的中点值作为一种阈值选择。比如:当有 10 个样例时,会测试 9 个不同的阈值。

6、回归树
前面的决策树都用了进行分类,而决策树中的回归树是构造了一个回归问题,它的每个节点(不一定是叶子节点)都会得一个预测值。比如:根据耳朵形状、面部形状、胡须来预测体重的回归问题。
过程:预测新样例时,从根节点开始根据样例特征进行决策,直至输出该叶节点动物的权重的平均值,也就是8.35,9.2,17.7,9.9其中的一个值
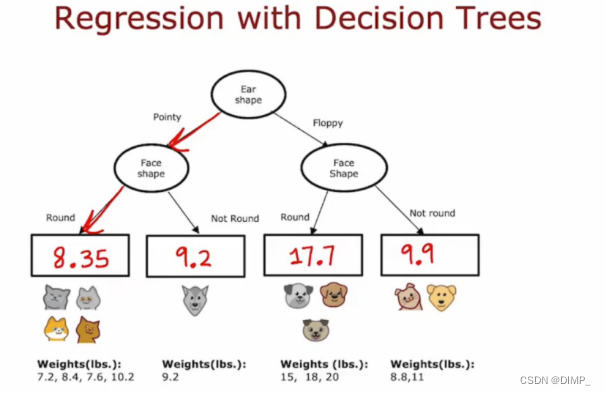
如何构造回归树
方差最小,方差的减少最大(类比熵)

7、多个决策树
单决策树的决策对数据中的微小变化高度敏感(重点理解!),而使算法不那么敏感的解决方案是构建树集合,让它们投票选择最终输出

抽样放回
比如:原始训练集中有 10 个动物,我们做 10 次有放回抽样,得到一个新的训练集。抽样放回对于构建树集合有关键作用
8、随机森林
它是一种分类算法,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。
每棵树都选择部分样本及部分特征,一定程度上避免过拟合
过程:
从样本集中有放回随机采样选出n个样本;
从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树(一般是CART,也可是别的或混合);
重复以上两步m次,即生成m棵决策树,形成随机森林;
对于新数据,经过每棵树决策,最后投票确认分到哪一类。
9、XGBoost
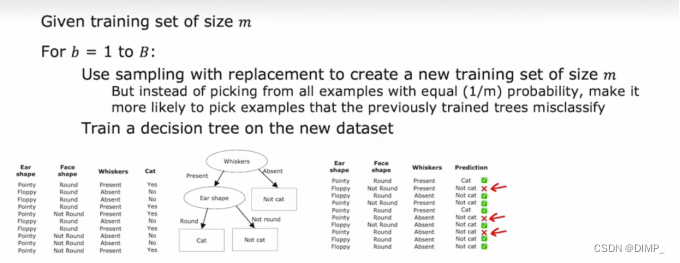
对生成树集合的算法进行了改进,除了第一次取样以外,每次优先选择在之前的随机树中预测错误的例子,也被称为刻意练习。
上述内容仅作框架整理















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









