







 本文介绍了回归模型中自相关性的两种检验方法——画图检验法(包括残差图和et-1图)和DW检验法,并提供了相应的DW值判断标准。针对自相关性问题,提出了迭代法和差分法作为解决方案,提供了Python代码示例来演示这两种方法的应用。
本文介绍了回归模型中自相关性的两种检验方法——画图检验法(包括残差图和et-1图)和DW检验法,并提供了相应的DW值判断标准。针对自相关性问题,提出了迭代法和差分法作为解决方案,提供了Python代码示例来演示这两种方法的应用。
提示:本文是回归模型的自相关性分析和如何解决这个问题
目录
一、自相关性检验方法
方法一:画图检验法
1、残差图法
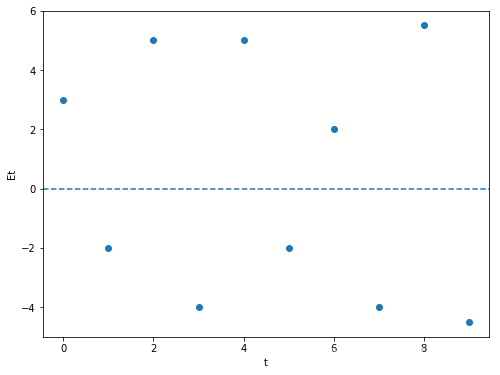
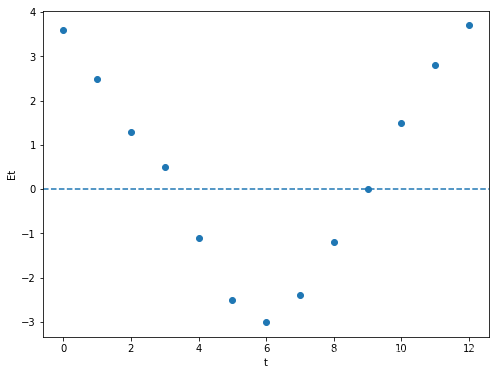
图一 图二
图一所示,出现不断正负交替的残差图,我们认为是存在自相关性,而且为负的自相关性。图二所示,出现向上或者乡下开口类似的曲线形状的,我们就认为存在自相关性,而且为正的自相关性。一般情况下,是比较难通过残差图去直观的看出有没有自相关性,而是通过DW法去准确的判断。
2、et和et-1图
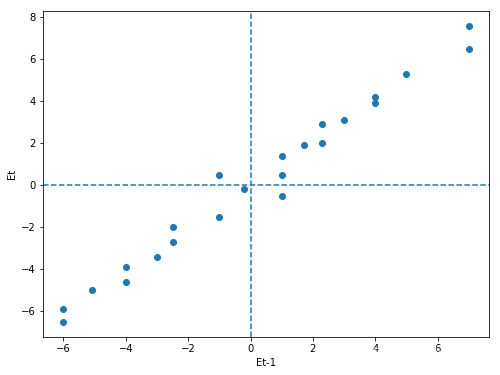
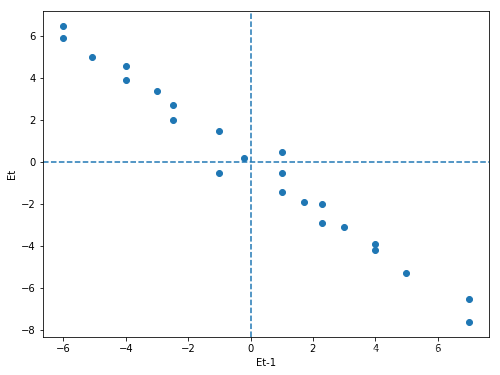
图一 图二
这种方法就是画出残差Et为y轴和残差Et-1为x轴的二维平面图,然后观察图形的趋势,如果出现图一的,散点主要分布在第一和第三象限且呈现递增趋势的,就认为存在正相关性;图二散点主要分布在第二和第四象限且呈现递增趋势的,就认为存在负相关性;这种方法就比较直观的可以看出来数据呈现出自相关性。
方法二:DW检验法
这种方法就是最常用的方法,通过查表数据的对比就能直观看出自相关性。
构造DW统计量进行验证,如下:
然后推到便得到DW的最终式子,如下:
通过下面的表格就可以判断出是否具有自相关性:
| DW | 自相关性 | |
| -1 | 4 | 完全负自相关性 |
| (-1,0) | (2,4) | 负自相关性 |
| 0 | 2 | 无自相关性 |
| (0,1) | (0,2) | 正自相关性 |
| 1 | 0 | 完全正自相关性 |
根据这两个值进行判断,代码如下:
#建模
result = smf.ols('y~x',data = df)
#DW检验
DW = sm.stats.durbin_watson(result.resid)
rho = 1-0.5*DW
print('DW值:',DW)
print('ρ的值:',rho)或者可以根据数据的条数和因变量的个数(包含常数项)查表,确定dL和dU的值,然后再判断,如下表:
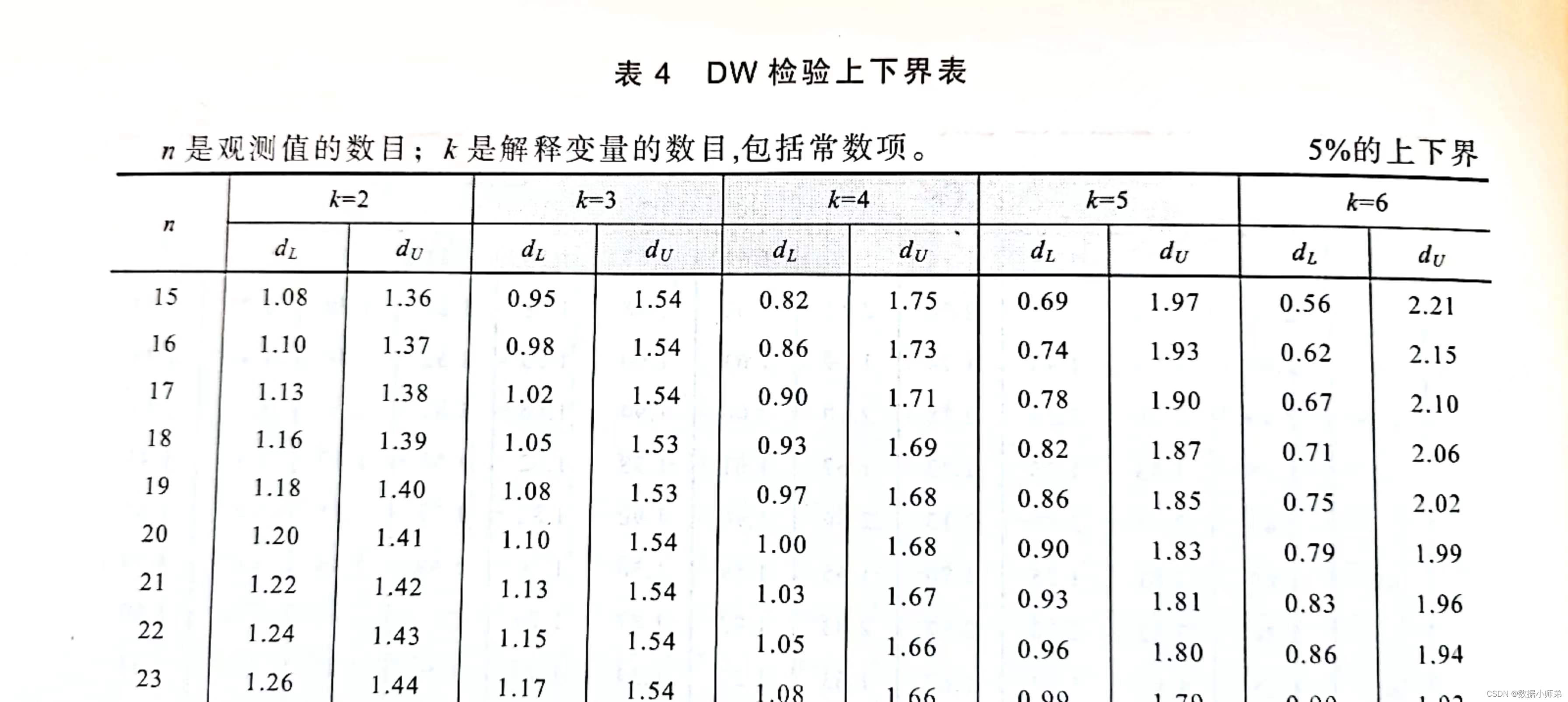
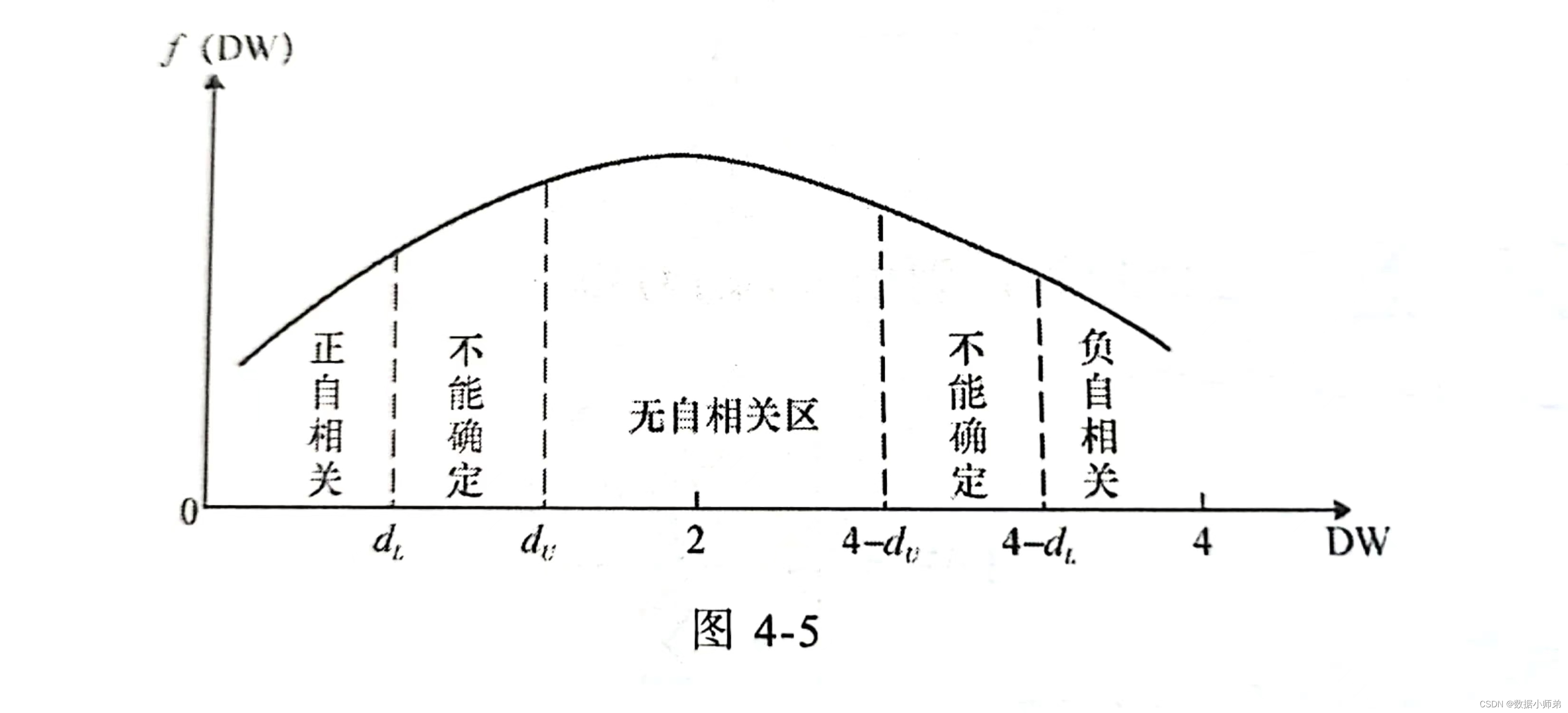
然后根据dL和dU,结合DW的值判断,通过下图:
二、解决方法
方法一:迭代法
直接上代码进行讲解
df = pd.read_csv("data.csv")
#迭代法解决自相关性
dfnew = (df-rho*df.shift(1)).dropna() #迭代公式
resultnew = smf.ols('y~x',data=dfnew).fit() #重新建模
print(resultnew.summary()) # 打印出模型的结果代码中的shift(1)是数据表中从第几行开始进行迭代,一般格式为shift(n),这里的n是数据从第几条开始迭代,注意Python是从0开始计数的。dropna() 函数主要用于过滤去除缺失数据的列或者行,因为我们是从第二条数据开始迭代的,第一条数据就会变为空,就直接赋予空值,不再计算。
方法二:差分法
df = pd.read_csv("data.csv")
#差分法解决自相关性
dfnew2 = (df-df.shift(1)).dropna()
print(dfnew2)
resultnew2 = smf.ols('y~x-1',data=dfnew2).fit()
print(resultnew2.summary())注意差分法的使用,它是不需要截距项的。这里使用的函数是相同的,可看前面的讲解。
总结:
以上就是本文的内容了,有错误的地方和疑问在评论区交流交流,一起学习和进步。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











