






原文地址:https://arxiv.org/abs/2203.08519
author={Zhaoyu Chen and Bo Li and Jianghe Xu and Shuang Wu and Shouhong Ding and Wenqiang Zhang}
title={Towards Practical Certifiable Patch Defense with Vision Transformer}
一、介绍
本文中专注于对补丁攻击的可认证防御,它允许对给定威胁模型的所有可能的攻击具有保证的鲁棒性。将ViT整合到DS中是一种潜在的可认证补丁防御。
我们提出了一个有效的可认证补丁防御与ViT,以提高准确性和推理效率。首先,我们引入一个渐进平滑的图像建模任务来训练ViT。具体地,训练目标是基于平滑的图像带逐渐恢复原始图像标记。通过逐步重构,基分类器可以显式地捕获图像的局部上下文,同时保留全局语义信息。因此,通过非常有限的图像信息(薄的平滑图像带)可以获得更具鉴别力的局部表示,这提高了基础分类器的性能。然后,我们将原ViT的全局自注意结构改造为孤立的带单元自注意结构。将输入图像划分为多个波段,分别计算每个波段单元的自注意力,为多波段的并行计算提供了可行性。最后,我们的方法在ImageNet上实现了78.58%的干净准确率,在2%面积补丁攻击下的有效推理中达到了41.70%的认证准确率。清洁精度非常接近正常的ResNet-101精度。
贡献:1.我们将ViT引入到可认证补丁防御中,并提出了一种渐进平滑的图像建模任务,该任务让模型在保留全局语义信息的同时捕获图像的更多可辨别的局部上下文。
2.我们将ViT的全局自注意结构更新为孤立的带单元自注意(isolated band-unit self-attention),从而大大加快了推理速度。
3.实验表明,我们的方法获得了最先进的清洁和认证的准确性,有效地推断CIFAR-10和ImageNet。此外,我们的方法在ImageNet上实现了78.58%的干净准确率,在2%面积补丁攻击下的有效推理中达到了41.70%的认证准确率。清洁精度非常接近正常的ResNet-101精度。
二、详细方法
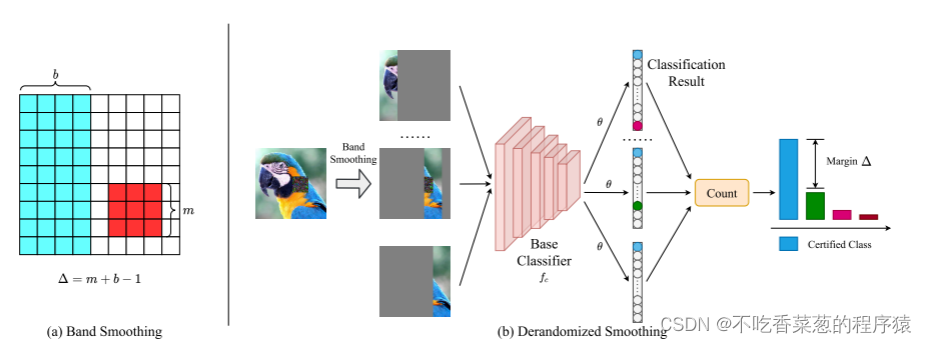
去随机平滑(DS)。红色斑块表示对抗斑块,蓝色条带表示(a)中条带平滑后保留的图像。(b)描述了DS的流水线。首先,DS在带平滑中对图像进行平滑,并从不同位置获得平滑图像。然后将平滑后的图像送入基分类器fc,通过阈值θ得到分类结果。最后,DS对结果进行计数,并应用公式2来判断图像是否经过认证。

(1)
去随机平滑中的平滑是指保留连续图像的一部分并平滑图像的其他部分。例如,带平滑意味着平滑除固定宽度b的带之外的整个图像,如图1(a)所示。DS用平滑的图像训练基本分类器。对于输入图像x ∈ Rc×h×w,令基分类器表示为fc(x,b,p,θ),其中x是输入图像,b是频带的宽度,p是保留频带的位置,θ是用于投票的阈值,c是类别标签。对于每个类c,如果类c的logits大于阈值θ,则fc(x,B,p,θ)为1,否则为0。为了计算认证的鲁棒性,DS计算基础分类器应用于每个类的波段数。
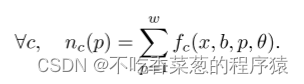
仅当最高类别(例如标签c)的统计量大于下一个最高类别c′的裕度(margin)时,图像才被认证。对抗补丁的形状应该是m × m。带和这个补丁之间的交叉点的数量最多为m+ b − 1。因此,当图像质量满足以下条件时,图像被认证:
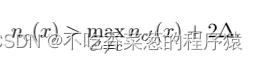
当阈值θ被确定时,最高类已被保证不受对抗补丁的影响。因此,我们将干净的准确性定义为投票后分类正确的准确性。经认证的准确度是分类是正确的并且在投票之后满足等式2的准确度。
(2)
我们需要基本分类器能够更好地捕获可区分的特征。受MLM的启发,我们提出了一个平滑的图像建模任务来训练ViT。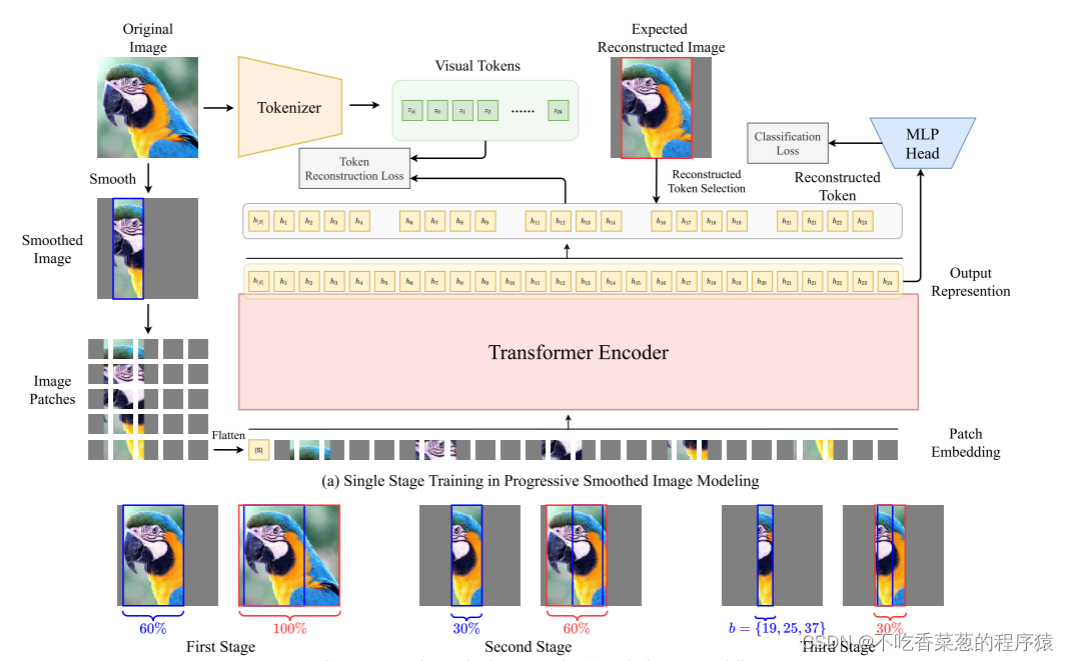
(a)描述了渐进平滑图像建模中的单阶段平滑训练。我们期望平滑图像被重建为期望的重建图像。(b)描述了多阶段训练中的重建比率。蓝色框表示平滑后的条带,红色框表示预期的重建条带。
通过逐步重建平滑的图像部分,基本分类器可以显式地捕获图像的局部上下文,同时保留全局语义信息。因此,通过非常有限的图像信息,可以获得更多的判别局部表示,这提高了基本分类器的性能。
图(a)首先介绍渐进平滑图像建模中的单阶段训练为了加速收敛,我们引入了一个标记器作为重建的监督。有两种类型的监督重建:VAE和蒸馏。对于VAE,我们使用预先训练的VAE [32]进行监督。对于蒸馏,我们使用预训练的ViT [9]的输出进行监督。给定平滑图像xs,我们将其分割成N个图像块{xs p i }N i=1,并获得N个视觉令牌{zi}N i=1。以xs的频带为中心,我们选择重建频带并生成期望的重建图像。根据期望的重建图像,我们有一个重建令牌(tokens)选择,以获得重建令牌。期望的重构图像中的带(band)产生对应于需要构造的块xp i的带掩饰 (mask){Mb i }N i=1。因此,重构的令牌和对应的视觉令牌被重新表述为:
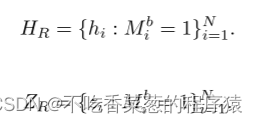
平滑训练的目标是同时最小化分类损失和令牌重建损失。对于VAE,总损失可以表示为:
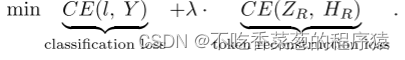
对于蒸馏,总损失可以表示为:
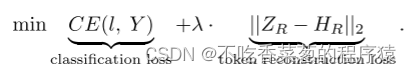
这里,l是通过MLP头后的输出logits,Y是x的标签。λ = 1000平衡了令牌重建损失和分类损失之间的梯度。
(B)展示出了在每个阶段内变化的重构比。蓝色框表示平滑后的条带,红色框表示预期的重建条带。在第一阶段,我们随机平滑大约40%的图像。剩下的60%的图像用于重建整个图像。在第二阶段,我们平滑掉70%的图像,并利用剩余的30%的波段,在以30%波段为中心的邻域内重建60%的补丁,包括30%波段。在最后一个阶段,只保留宽度为b的带,所有其他部分都被平滑。宽度为b的带用于重建以该带为中心的邻域中的30%的块。该方法通过渐进平滑的图像建模,大大缩小了DS模型和正常模型之间的精度差距,使得在实践中实现可认证的补丁防御成为可能。
(3)
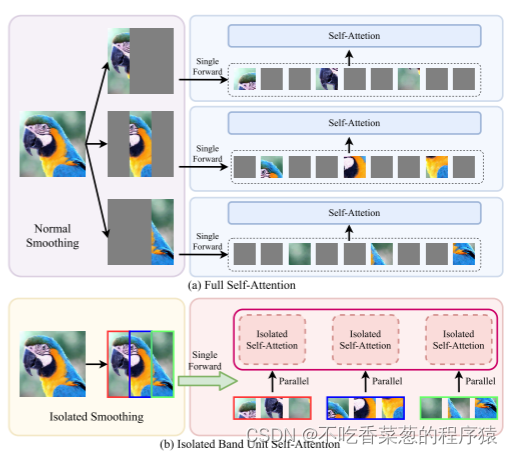
介绍了隔离带单元自注意(Isolated Band Unit Self-attention)。(a)描述了正常的训练,平滑部分是多余的,不需要计算。(b)引入了孤立的频带单元自注意力,即平滑部分被丢弃,并且自注意力仅在并行窗口内计算。
我们创新性地将原有ViT的全局自注意结构改造为孤立的波段单元自注意。具体地说,通过滑动窗口将输入图像划分为多个波段,并分别计算每个类波段单元中的自注意力,为多个波段的并行计算提供了可行性。如图3(B)所示,我们通过并行滑动窗口选择每个波段的补丁,并在一个前向计算中推断多个波段。在孤立带单元自注意中,窗口是一个带,孤立的自注意仅在窗口内计算。
与正常平滑相比,ViT将xs分割为hw/p2块,并且我们仅选择窗口内的N = hb/p2块进行微调和推断。自注意操作的整个图像输入的时间复杂度为O·N2 d + Nd 2,其中第一项是注意操作的复杂度,另一项是全连接操作的复杂度。与输入整幅图像相比,孤立的自我注意可以将计算量减少到前者的1 w/B。此外,它还具有同时进行推理的B个相邻窗口,其中窗口的形状为(h,b)。因此,我们将原来的正演计算由w次改为B(w B)次。因此,可以通过有效的推理在真实的系统中部署可认证的补丁防御。
三、实验
我们在CIFAR10 [20]和ImageNet [6]上进行了广泛的实验。我们选择不同的网络作为基本分类器,,例如ResNet 50 [13],ResNext 101 - 32 x8 d(ResNext 101)[41],ViT-S/16-224(ViT-S)和ViT-B/16-224(ViT-B)[9]。在平滑模型中,这些方法直接将相应的主干应用到DS中,并且都是从ImageNet预训练模型中进行微调的[38]。我们报告了ECViT与区间边界传播(IBP)[5],去随机化平滑(DS)[21],裁剪BagNet(CBN)[42],Patchguard [40](PG)和BagCert [30]的干净和认证准确性比较。
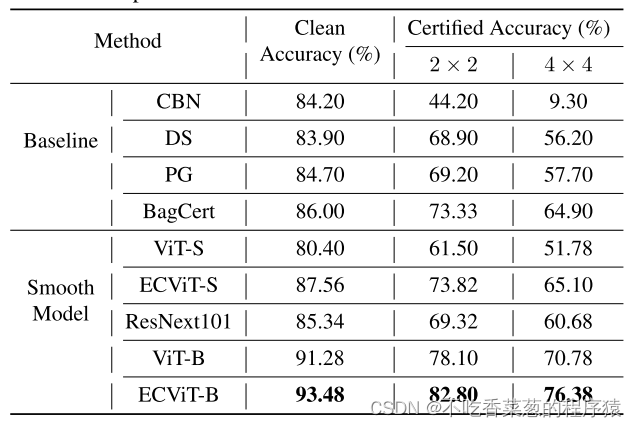
我们在CIFAR 10验证集的5,000张图像上评估了干净和认证的准确性。ECViT能有效地提高平滑ViT的精度,达到最新水平。
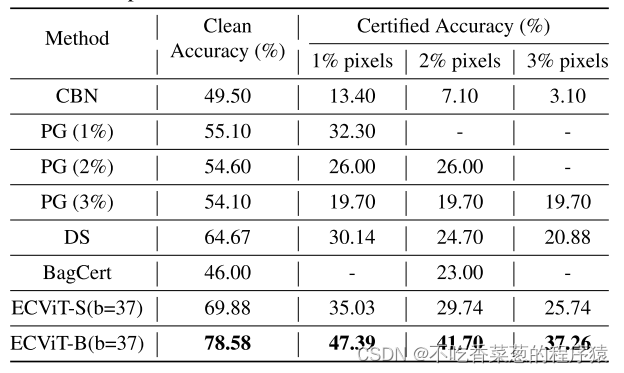
我们在ILSVRC 2012验证集上评估了我们提出的ECViT [33]。显示了ILSVRC 2012上最先进方法的清洁和认证准确度比较。ECViT-B比BagCert的清洁和认证精度高出7.48%和9.47%,与之前的最先进方法相比,达到了最先进的清洁和认证精度。
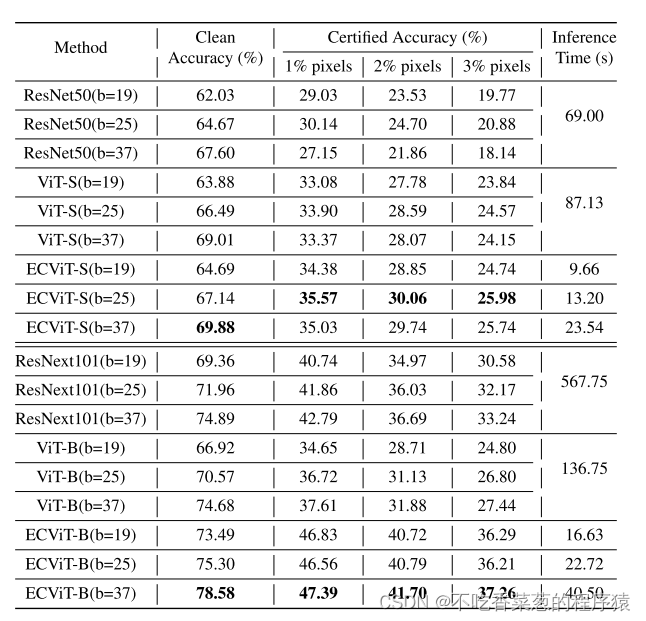
显示了与ILSVRC 2012上的其他平滑模型相比的干净和经认证的准确度。与ECViT以外的其他模型相比,平滑模型基于DS中的不同主干。我们的方法在ILSVRC 2012上获得了最先进的认证,同时保持了78.58%的清洁准确率,非常接近正常的ResNet-101。
四、消融研究
关注研究阶段数量、不同补丁大小和标记器对干净和认证准确性的影响。
(1)阶段数量
以两阶段为例,两阶段表示在前两阶段的渐进平滑图像建模之后的直接微调。其中,总训练时期是相同的。一个阶段和三个阶段的含义与两个阶段相似。
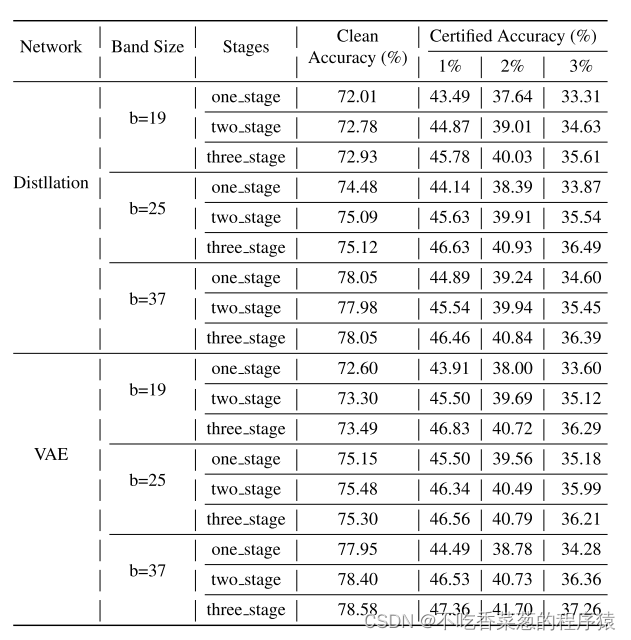
显示了ECViT-B的ILSVRC 2012验证集上不同阶段和标记器的训练。
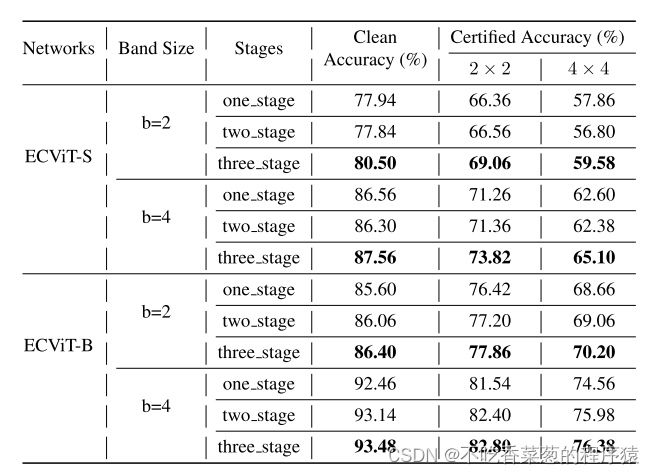
反映了CIFAR 10上消融实验的不同阶段。清洁和认证的准确性基本上随着训练阶段的增加而增加。实验表明,渐进平滑图像建模任务允许基分类器显式地捕获图像的局部上下文,同时保留全局语义信息。因此,可以通过非常有限的图像信息(平滑的薄图像带)获得更具鉴别力的局部表示,这提高了基础分类器的性能。
(2)不同补丁大小
对抗补丁的大小将极大地影响认证。
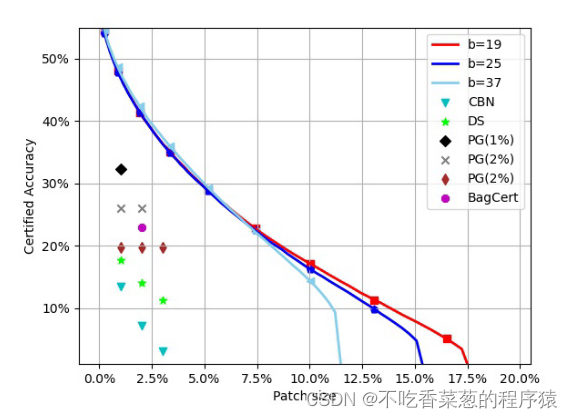
反映了ECViT-B在ImageNet上的认证精度变化。
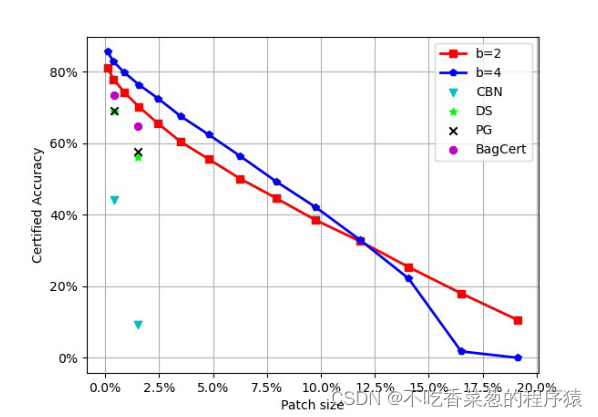
反映了ECViT-B在CIFAR 10上的认证精度变化。认证的准确性随着补丁大小变得更大而降低。当补丁大小达到10%时,ECViT-B在ImageNet和CIFAR 10上的认证准确率仍然为17.00%和39.00%。
(3)标记器
验证渐进平滑图像建模对其他标记器也有效。
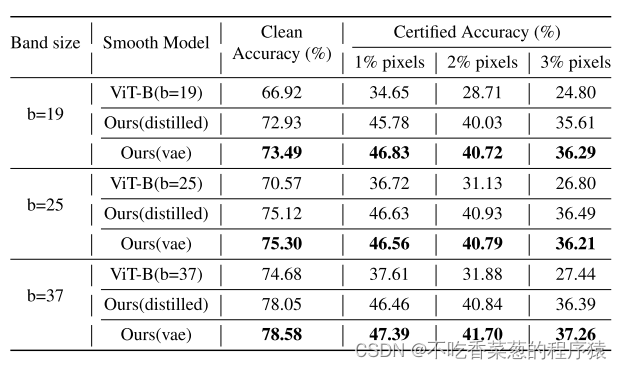
不同令牌化器和其他网络架构的比较。我们可以看到,与ViT-B相比,蒸馏分词器有明显的改进,但仍然低于VAE分词器。这也验证了我们的方法可以适用于不同的标记器。
五、结论
可认证的补丁防御可以保证针对给定威胁模型的所有可能攻击的鲁棒性。现有的可认证补丁防御牺牲了分类器的干净准确性,并且仅在玩具数据集上获得较低的认证准确性,这限制了它们在实践中的应用。为了实现实用的可认证补丁防御,我们引入了虚拟入侵检测到DS的框架。通过渐进平滑图像建模和孤立波段单元自注意,我们的ECViT在CIFAR-10和ImageNet上获得了最先进的准确性和高效的推理效率。在我们的工作中,我们希望提供一个新的角度来看,一个合适的网络架构,可以提高补丁防御在实践中的上层认证。
限制和更广泛的影响。尽管假设对抗补丁是正方形而不是矩形或不规则形状的限制,我们认为ECViT引入了一个实用的可认证补丁防御,以帮助物理系统减轻补丁攻击的威胁。















 1488
1488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









