






原文链接:https://arxiv.org/abs/1608.04644
author={Nicholas Carlini and David Wagner},
title={Towards Evaluating The Robustness Of Neural Networks},
内容:在之前蒸馏防御可以很好的抵御各种攻击,但是这篇文章作者提出一个新的攻击算法使蒸馏攻击不会很有效的提高模型的鲁棒性。而且这种攻击具有很高的置信并且具有转移性。
提出了在不同范数下ℓ0,ℓ2,ℓ∞下生成adversarial samples的方法, 实验证明此类方法很有效.
提出了7个优化目标,并系统地评估了目标函数的选择,目标函数的选择可以显著地影响攻击的效果。
蒸馏网络:改进了Softmax函数(梯度屏蔽)
T意思是Temperature,就是一个在softmax操作前需要统一除以的小参数,这个小参数有这样的属性: 如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率 如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码 如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。
构建Adversarial samples指定类别:
Average Case: 在不正确的标签中随机选取类别;
Best Case: 对所有不正确的标签生成Adversariak samples, 并选择最容易成功(即骗过网络)的类别;
Worst Case:对所有不正确的标签生成Adversariak samples, 并选择最不容易成功的类别。
C&W是一种基于优化的攻击方式,它同时兼顾高攻击准去率和低对抗扰动的两个方面。首先对抗样本需要用优化的参数来表示,其次在优化的过程中,需要达到两个目标,目标一是对抗样本和对应的干净样本应该差距越小越好;目标二是对抗样本应该使得模型分类错,且错的那一类的概率越高越好。

其中D衡量x,x+δ之间的距离, 常常为ℓ0,ℓ2,ℓ∞,t表示想要targe label,C是分类器。 但是C (x + δ) =t这个条件离散, 这个问题很难直接求解, 作者给出的思路是构造一些函数f(x,t), 使得当且仅当f(x,t)≤0的时候此条件满足。

进一步

作者给出了7种符合此类条件的函数(作者尤为推荐第6种):

其中s是正确的分类,(e)+是max(e,0)的简写,softplus(x)= log(1 + exp(x)),s(x)是x的交叉熵损失。
其中 C>0 , 是一个适当选择的常数。公式中的第一项为距离表示可以换成范数的形式为:

盒约束: 关于像素值的上下界,原文将之命名为"box constraint",之所以存在上下界,是因为数字图像能表示的像素值范围是有限的,在经过归一化之后,像素值应该在[0,1]的范围内,即满足0 ≤x+δ≤ 1 。如果在攻击生成之后,直接把像素值裁剪到[0,1]的范围内,那显而易见,会破坏形成的攻击效果。那么如何在优化的过程中优雅地引入这个限制,又能保障攻击的效果呢? 答:对δ进行替换,由于tanh函数取值性质,从而保证x+δ符合盒约束。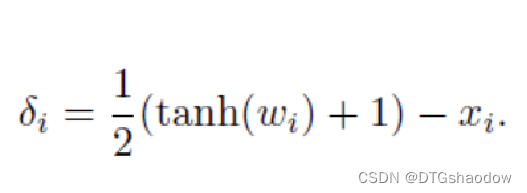
三种攻击:L0 attack
作者的方法是:一步步的找到那些对分类结果影响很小的像素点,然后固定这些像素点(因为改了它们也没有什么作用),直到无法再找到这样无影响的像素点了。 具体操作是,在每个迭代步中,基于L2 距离来生成攻击样本、计算损失函数值,获得扰动对应的梯度g=∇f(x+δ),随后基于梯度来找到对目标函数值影响最小的像素点,将该像素点排除在外,对其他像素进行梯度反传更新。不断迭代,直到获得一个最小的像素子集合(终止条件是L2的攻击方式无法再找到有效的攻击样本)。 在每一个迭代步中,基于L2的攻击方式是从原始图像开始来生成扰动的,为了加快攻击生成的速度,作者对该设置做了一定的修改,在每个迭代步中,攻击生成的初始图像为上一个迭代步的最终图像。之所以可以这样做,是因为修改k个像素与修改k+1个像素在生成对抗样本的方式上是非常接近的。
L2 attack: 为了解决梯度下降容易陷入“次优解”的问题,作者在原始图像的r领域(r对应已发现的扰动最小的攻击样本)里采样多个点作为初始图像,在多个初始图像的基础上进行攻击扰动的生成。c使用二分类搜索进行选择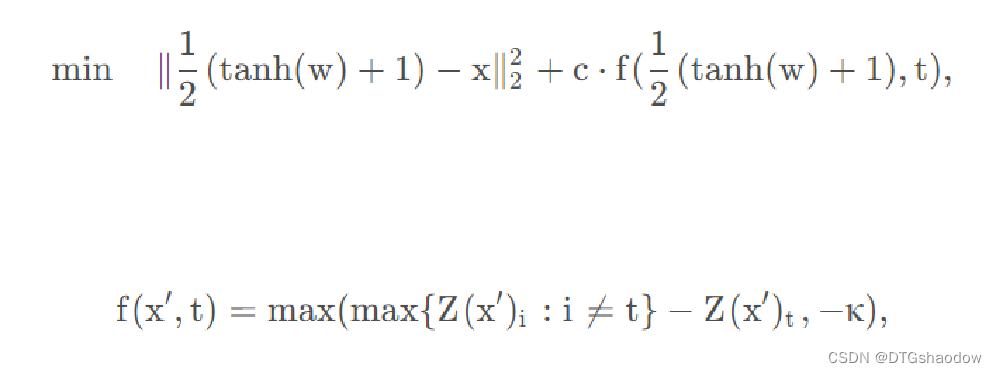
L∞ attack: 该攻击方法不是完全可微的,并且标准的梯度下降算法并不能达到非常好的效果,即采用如下策略时,会出现一个问题:无穷范数只惩罚最大的那个值。那么就可能出现这种情况:有两个像素点,分别是δi=0.5和δj=0.5-𝝴,那么L2正则化就会惩罚δi点,而正则化在点δj处的梯度将会是0,该点即便扰动量很大也不会被惩罚。因此,在后序迭代中,δj=0.5+𝝴可能会慢慢大于δi=0.5-𝝴,如此反复,两个点会在附近来回波动,不会有任何有效的更新。
为了解决这个问题,作者将后面正则化项更换为了一个迭代的攻击,即超过┱的项都会被惩罚。

┱的初始值为1,在每次迭代中减少0.9,这可以防止振荡,因为该损失项会同时惩罚所有较大的值。如果所有像素的像素值均小于┱,那么对┱衰减0.9。如果所有的像素值都大于┱,就停止攻击样本的搜索。
实验:MNIST和CIFAR-10分类任务训练了两个网络,并为ImageNet分类任务使用了一个预先训练的网络。
本文的方法不仅成功率极高,在扰动量方面也有很大的优势。作者还评估了运行时间方面的指标,发现这个方法很慢。
对防御性蒸馏的攻击

作者首先说明了为什么防御性蒸馏对之前的攻击方法都有效,因为温度T的存在,真实标签类别对应的logits值会是温度为1时的T倍,作者通过实验证实了这点。那么,其他类别的logits值将会非常非常小,对应的梯度同样非常小,事实上,在大部分情况下,梯度小到32-bit的数据无法表示,只能取0。这样攻击生成所能利用的梯度就几乎不存在,自然无法攻击成功,这就是防御性蒸馏生效的原因。 而本文的方法在攻击防御性蒸馏时,几乎取得了100%的成功率。此外,面对此前的攻击时,调高防御性蒸馏的温度会持续降低攻击的成功率,但这对于本文的方法来说依旧是无效的。
总结:使用强大的攻击(如本文中提出的攻击)来直接评估安全模型的鲁棒性。由于阻止我们的L2攻击的防御将阻止我们的其他攻击,防御者应该确保建立对L2距离度量的鲁棒性。 通过在不安全的模型上构建高置信度的对抗性示例,并证明它们无法转移到安全模型,来证明可转移性失败。















 5019
5019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









