









前言
本文将解读论文 Learning Deep Bilinear Transformation for Fine-grained Image Representation,并将在后续文章中尝试基于pytorch复现DBTNet。
一、参考论文
Learning Deep Bilinear Transformation for Fine-grained Image Representation
二、论文解读
摘要
双线性特征变换在学习细粒度图像表征方面表现出了最先进的性能,但是缺点是计算成本过高。文章提出了一种可以嵌入CNN网络的DBT块,DBT块可以将输入通道划分为几个语义组,双线性变换可以计算每个组内的成对相互作,因此计算成本可以大大降低。每个DBT块的输出是 通过将组内双线性特征与整个输入特征的残差进行聚合 获得的。
1.简介
主要思路:在保持计算复杂度的同时,通过对一个区域最具区别性的特征通道双线性变换的计算,提高分类精度。
DBT由语义分组层和组双线性层组成。语义分组层根据输入通道的语义信息(例如,鸟的头、翅膀和脚)将输入通道映射为统一划分的组,因此,特定语义的最有区别的表示集中在一个组中。这种表示可以通过组双线性层的成对交互进一步增强,该层在每个语义组内进行双线性变换。由于双线性变换增加了每个组中的特征维数,我们通过进行组间聚合来获得组双线性层的输出,这可以显著提高输出通道的效率。为了在聚合过程中保留组顺序信息,采用组索引编码,并采用shortcut connection的方法对原始特征和双线性特征进行剩余学习。
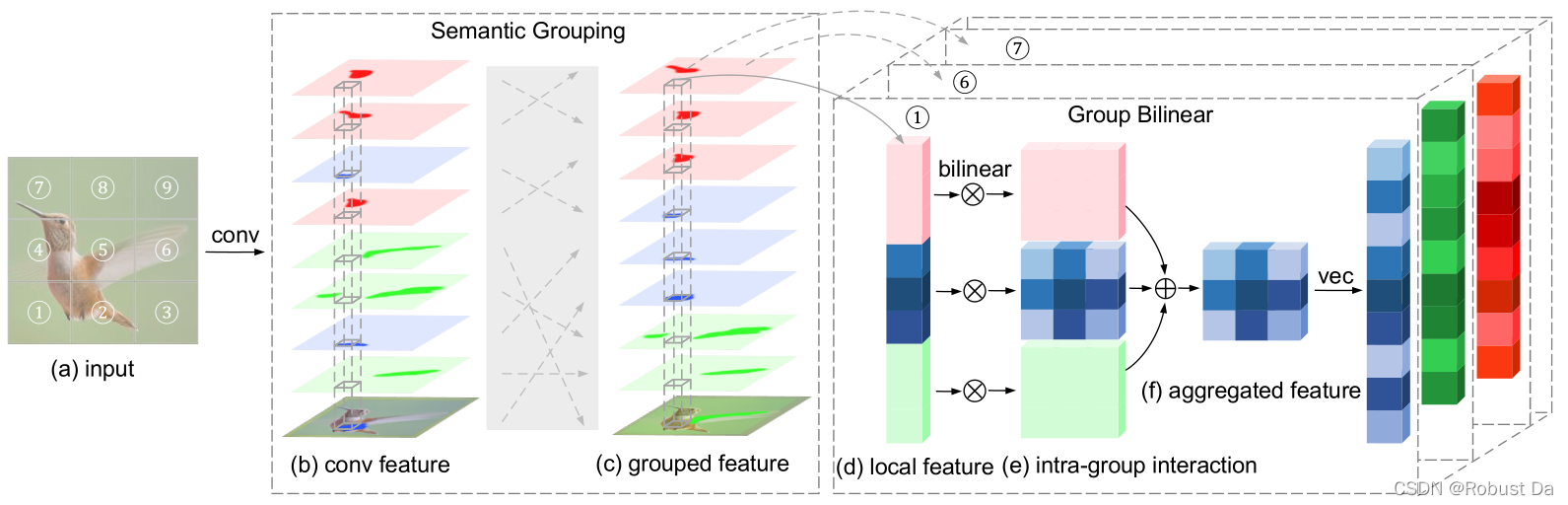
与传统的双线性变换相比,DBT通过分组和聚合大大降低了计算成本,确保了它可以深入集成到CNN中。
主要贡献:
1、提出DBT,可以集成到CNN中获得深度双线性变换网络DBTNet,在多个层中学习成对交互,以增强特征识别能力。
2、通过学习语义组和计算组内双线性变换,仅在图像位置\区域的最具辨别力的特征通道内获得成对交互。
2.相关工作
Bilinear Pooling:Bilinear Pooling \ Low-rank Bilinear Pooling \ Compact Bilinear Pooling \ Second-order Pooling Convolutional Networks \ feature martrix normalization
Weakly-supervised Part Learning (Semantic part, a divide and conquer strategy): TLAN \ DVAN \ MA-CNN
Group Convolution: 减少卷积参数的有效方法,且性能更好。
3.Deep Bilinear Transform
双线性池化是通过外积来利用特征元素之间的成对交互。具有全连接层的双线性池化可以表示为: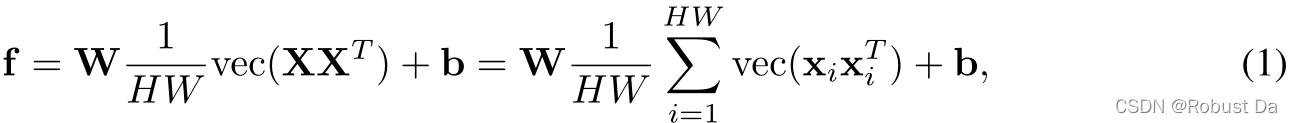
不足在于,二阶信息仅在最后一个卷积层中获得,特征维数比全局平均集合特征大N倍。
我们将语义信息集成到双线性特征中,提出的深度双线性变换(DBT)可以用卷积层堆叠。具有1×1卷积层的公式如下所示: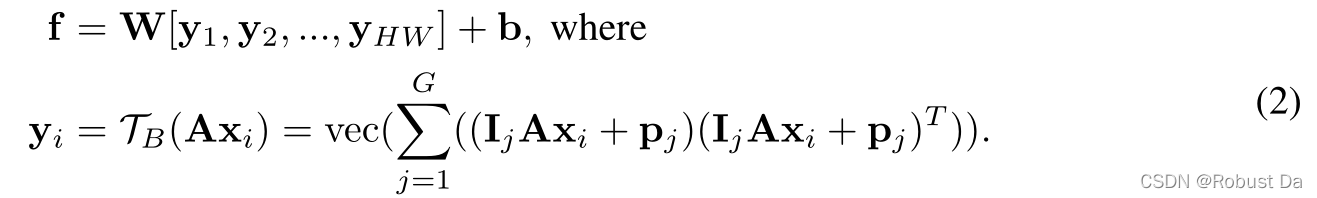
其中TB()为组双线性变换函数;Axi是语义分组特征;G是组数;pj是组索引码向量;Ij∈RN*N/G 是有G个块的矩阵,它的第j个块为单位矩阵,其他为0矩阵;A是语义映射矩阵,它会将代表相同语义的通道分组在一起。
3.1 Semantic Grouping Layer 语义分组层
高层的卷积通道往往能够对特定的语义形式做出反应,因此可以根据其语义信息将卷积通道分成G组。S(mi) ∈[1,G]是用于将卷积通道均匀分配到G个语义组的映射函数,满足的条件为 若⌊i/G⌋=⌊j/G⌋,则S(mi)=S(mj),其中⌊ ⌋ 为向下取整(⌈ ⌉为向上取整)。
为了获得语义部件的双线性特征, 首先按照语义组的顺序排列通道: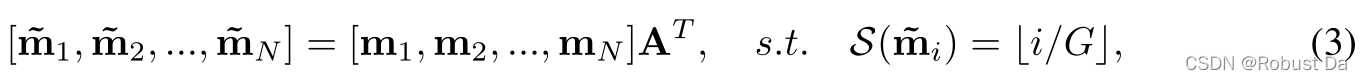
其中AT是语义映射矩阵,它需要被优化。
由于不同的语义部分位于给定图像的不同区域,对应于卷积特征中的不同位置,我们可以使用这些空间信息进行语义分组。具体来说,相同语义组中的通道被优化,交叠的空间大而不相同语义组中的通道被优化,交叠的空间小,这被表述为语义分组损失Lg:
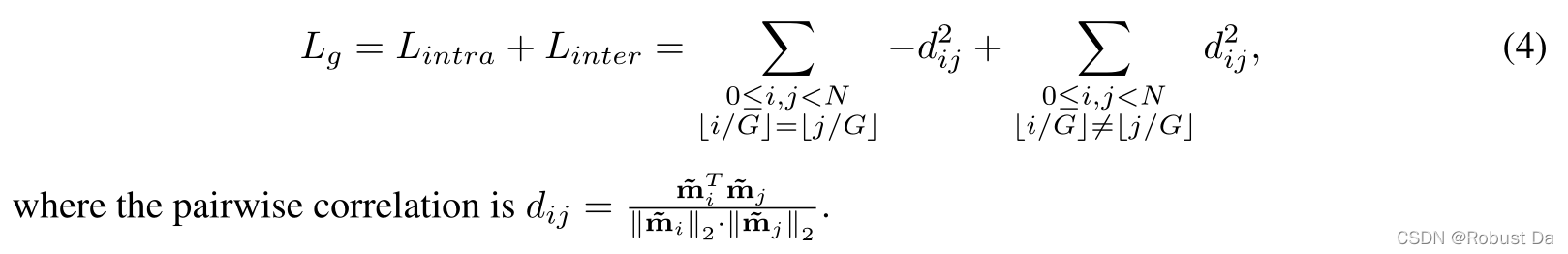
(我的理解为利用Lg去优化AT,进而实现语义分组,但是S(mi)映射函数的作用我就不懂了,有大佬懂的话求教!)
这种语义分组可以通过1×1卷积层来实现1,具体来说,卷积层可以表示为x=Wz,其中z∈ RM是输入特征,x∈ RM是输出特征,W∈ RN×M是权重矩阵。设U=AW,映射特征可由Ax=AWz=Uz获得,因此U是语义分组层的权重矩阵,输出特征x按语义分组。注意到U不仅用于语义分组,还用于卷积特征学习,因此我们可以将输出通道统一划分为预设数量的组,并在CNN训练过程中获得分组特征。
3.2 Group Bilinear Layer 组双线性层
Group Bilinear Layer的作用是根据按语义分好组的卷积特征,在不增加特征维度的情况下高效地获得双线性特征。
Group Bilinear Layer在组内进行通道间双线性变换的计算,这样可以通过成对交互增强相应语义的表示。 同时考虑到组内双线性变换增大了每组的特征维度,为了提高输出通道的效率,我们进一步聚合了这些特征:
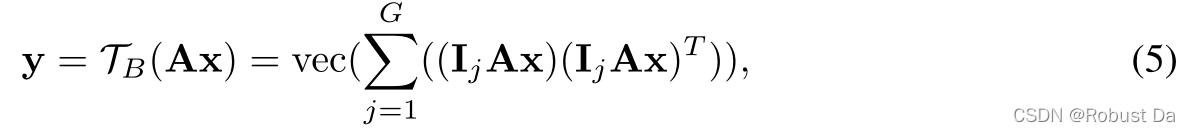
其中y∈R(N/G)2,G=
N
\sqrt{N}
N,N为通道数,这样做可以保证特征维度不变,进而DBT可以在不修改网络结构的情况下,很方便地融入CNNs。
在组上进行聚集可以将特征维数降低G倍,而在这样的过程中,组序信息会丢失。因此,我们在卷积信道表示中引入位置编码,并添加组索引编码项,以保留组顺序信息和改进对不同组中特征的区分:
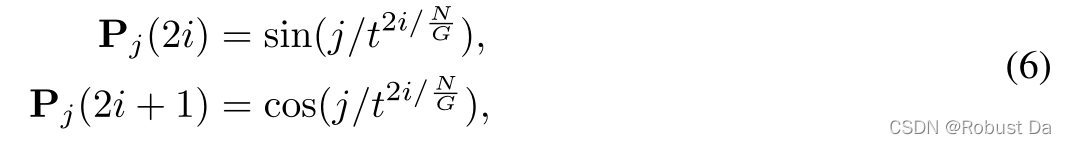
其中,t表示函数sin(·)的频率。在进行双线性变换之前,将这种组索引编码按元素添加到第j组特征中就可以得到公式(2):(IjAx+Pj)(IjAx+Pj)T,其中 Pj(IjAx)可以在聚合过程中保留组索引信息。
3.3 Deep Bilinear Transformation Network
Activation and shortcut connection
非线性激活函数可以增加模型的表征能力。tanh函数被广泛用于激活双线性特征,而不是ReLU,因为这样的函数能够抑制较大的二阶值。此外,受Residual Learning的启发,我们为语义组双线性功能添加了shortcut,以帮助优化: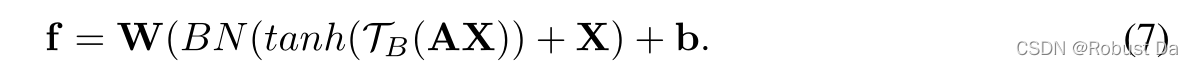
我们从原始特征开始进行网络研究,将 batch normalization layer 的“scale”参数初始化为零,这是一种有效的参数优化方法。
Deep bilinear transformation block

语义分组层是1×1卷积;3×3卷积层是CNN中特征提取的关键组件,可以将局部上下文信息集成到卷积通道中;组双线性层之后是3×3卷积,因此丰富的成对相互作用可以进一步集成,以获得细粒度表征。
Network architecture
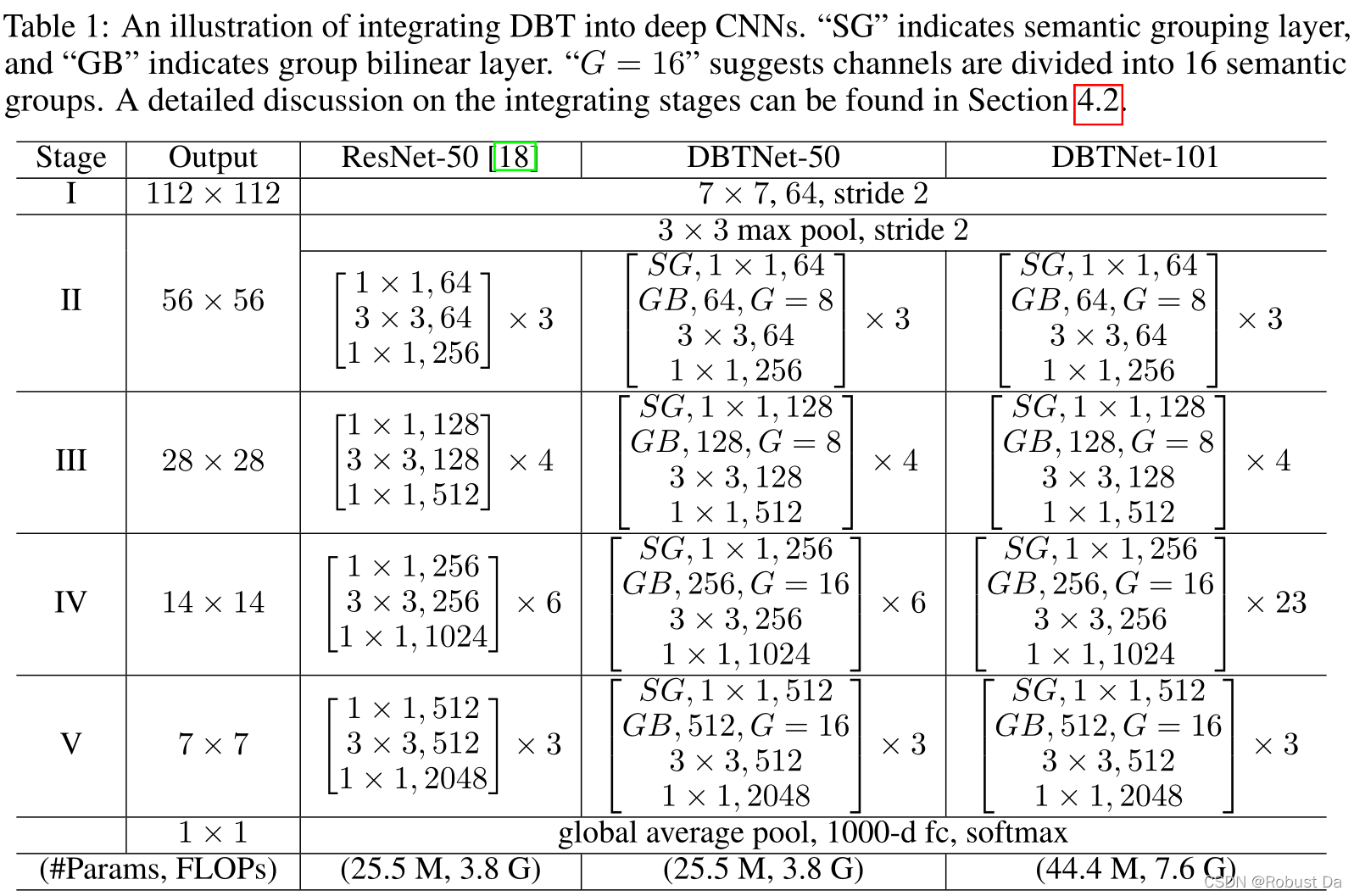
该模型的总损失L如下所示:

Lc是分类的softmax交叉熵损失,L(b)g是bth块上的语义分组损失,b是残差块的数量,λ是语义分组损失的权重。
3.4 讨论
通过计算组内双线性变换和进行组间聚合,提出的深度双线性变换可以在不增加特征维数的情况下生成细粒度表示。
Intra-group and inter-group pairwise interaction
我们在DBTNet-50的第3阶段为CUB-200-2011中的所有测试样本提取语义分组卷积特征,并可视化平均成对交互: 
共有16组256个通道,黄色表示大值,紫色表示小值。可以看出,组内的相互作用起着主导作用。 组内小的相互作用(例如,组#2)表明,这种语义特征的表征作用比其他小。
考虑来自不同语义组的两个卷积通道,即mi,mj∈ RHW,S(mi)≠S(mj)。因为不同的语义部分位于不同的位置,所以我们可以得到mi◦ mj=0,其中◦ 表示按元素乘积,0∈ RHW。简言之,不同语义组通道之间的双线性特征是零向量,这在不提供区分信息的情况下扩大了双线性特征维数。我们提出的DBT通过在组内的通道上执行外积来解决这个问题,而以前的低维双线性变体无法解决这个问题。
4、实验
4.1 实验环境
Datasets:CUB-200-2011、Stanford-Car、FGVC-Aircraft、iNatualist-2017
Implementation:
代码是基于MXNet的:https://github.com/researchmm/DBTNet
遵循细粒度任务中最常用的训练方法,在输入大小为224×224的ImageNet上预训练模型,并在输入大小为448×448的细粒度数据集上进行微调。
Learning Rate Scheduler: consine learning rate schedule
Optimizer :SGD
Batch size:48 per GPU
λ=3e-4(pre-training stage) / 1e-5(fine-tune stage)
4.2 消融研究 & 4.3 比较
略
结论
提出了一种可以融入DNN新颖的DBT块和可以达到sota的模型——DBTNet,其中DBT利用语义信息,通过计算语义组内的成对相互作用,可以有效地获得双线性特征。
由于语义信息只能在高层特征中获得,我们将在未来研究对低层特征进行深度双线性变换。此外,我们将探索以有效的方式将矩阵规范化集成到DBT中,以进一步利用双线性表征。
总结
本文给出了自己对 Learning Deep Bilinear Transformation for Fine-grained Image Representation 这篇论文的理解,其中有我的疑问,也可能会有错误,欢迎大家交流指正。接下来,我将尝试基于pytorch复现DBTNet。
















 1855
1855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











