







1.Introduction
- Time series classification methods can be divided into three main categories (Xing et al. 2010): feature based, model based, and distance based methods.
- Until now, almost all research in distance based classification has been oriented to defining different types of distance measures and then exploiting them within k-NN classifiers.
- Due to the temporal (ordered) nature of the series, the high dimensionality, the noise, and the possible different lengths of the series in the database, the definition of a suitable distance measure is a key issue in distance based time series classification.
- One of the ways to categorize time series distance measures is shown in Fig. 1; Lock-step measures refer to those distances that compare the ith point of one series to the ith point of another (e.g., Euclidean distance), while elastic measures aim to create a non-linear mapping in order to align the series and allow comparison of one-to-many points [e.g., Dynamic Time Warping (Berndt and Clifford 1994)].
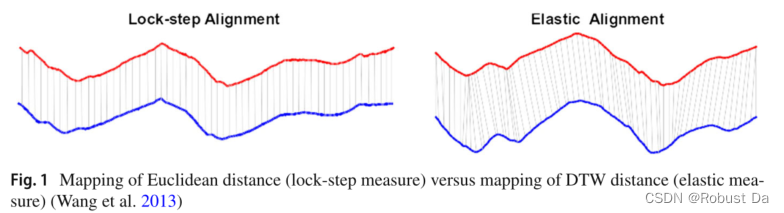
- The DTW distance seems to be particularly difficult to beat.
2.A taxonomy of distance based time series classification
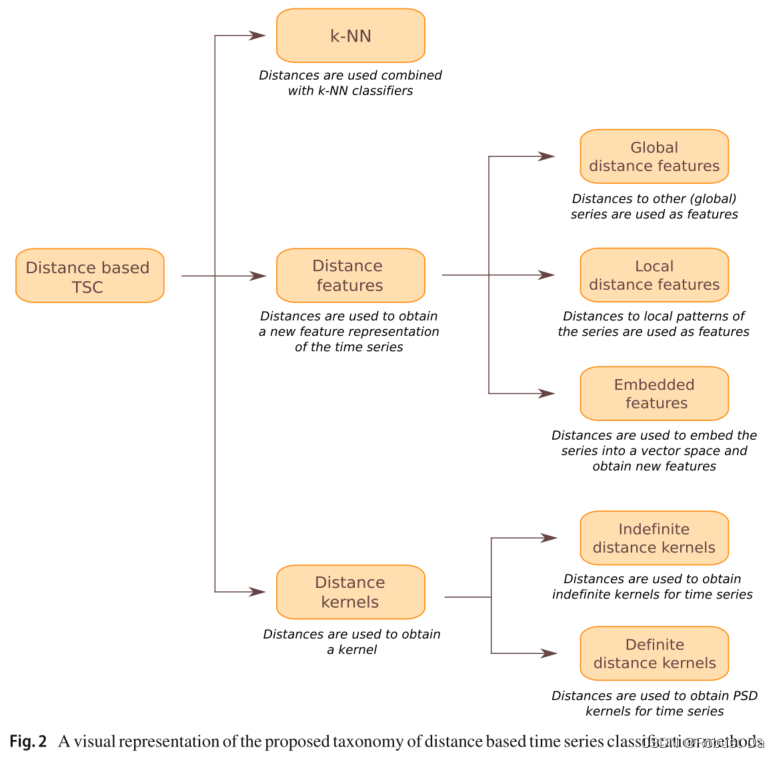
2.1 k-Nearest Neighbour
- Despite the simplicity of this rule, a strength of the 1-NN is that as the size of the training set increases, the 1-NN classifier guarantees an error lower than two times the Bayes error.
- Nevertheless, it is worth mentioning that it is very sensitive to noise in the training set, which is a common characteristic of time series datasets.
- This approach has been widely applied in time series classification, as it achieves, in conjunction with the DTW distance, the best accuracies achieved on many benchmark datasets.
2.2 Distance features
- In this manner, the series are transformed into feature vectors (order-free vectors), overcoming many specific requirements that are encountered in time series classification, such as dealing with ordered sequences or handling instances of different lengths.
- The main advantage of this approach is that it bridges the gap between time series classification and conventional classification, enabling the use of general classification algorithms designed for vectors, while taking advantage of the potential time series distances.
- Note that even if these methods also obtain some features from the series, they are not considered within feature based time series classification, but within distance based time series classification. The reason is that the methods in feature based time series classification obtain features that contain information about the series themselves, while distance features contain information relative to their relation with the other series.
2.2.1 Global distance features
-
The main idea behind the methods in this category is to convert the time series into feature vectors by employing the vector of distances to other series as the new representation.
这类方法背后的主要思想是通过使用到其他序列的距离向量作为新的表示,将时间序列转换为特征向量。 -
Firstly, the distance matrix is built by calculating the distances between each pair of samples, as shown in Fig. 3. Then, each row of the distance matrix is used as a feature vector describing a time series, i.e., as input for the classifier. It is worth mentioning that this is a general approach (not specific for time series) but becomes specific when a time series distance measure is used.
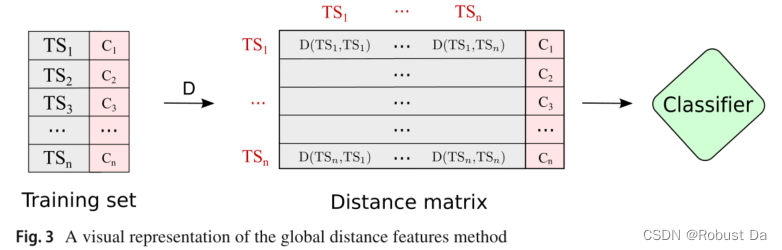
- It is worthmentioning that this is a general approach (not specific for time series) but becomes specific when a time series distance measure is used.
2.2.2 Local distance features
- An example of three shapelets belonging to different time series can be seen in Fig. 4. An important advantage of working with shapelets is their interpretability, since an expert may understand the meaning of the obtained shapelets.
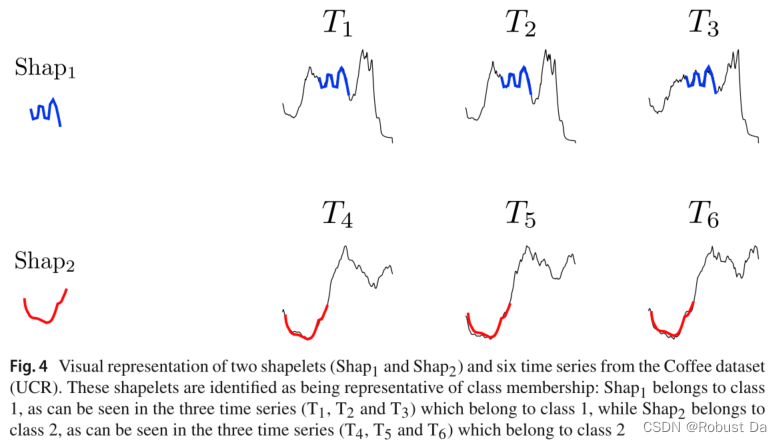
- Most of the work related to shapelets has focused on speeding up the shapelet discovery process or on proposing new shapelet learning methods.
- Building on the achievements of shapelets in classification, Lines et al.(2012) introduced the concept of Shapelet Transform (ST). First , the k most discriminative (over the classes) shapelets are found using one of the methods referenced above. Then, the distances from each series to the shapelets are computed and the shapelet distance matrix shown in Fig. 5 is constructed. Finally, the vectors of distances are used as input to the classifier.
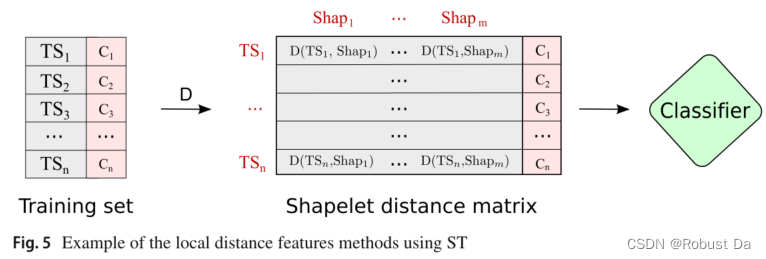
- In Lines et al. (2012), the distance between a shapelet of length l and a time series is defined as the minimum Euclidean distance between the shapelet and all the subsequences of the series of length l.
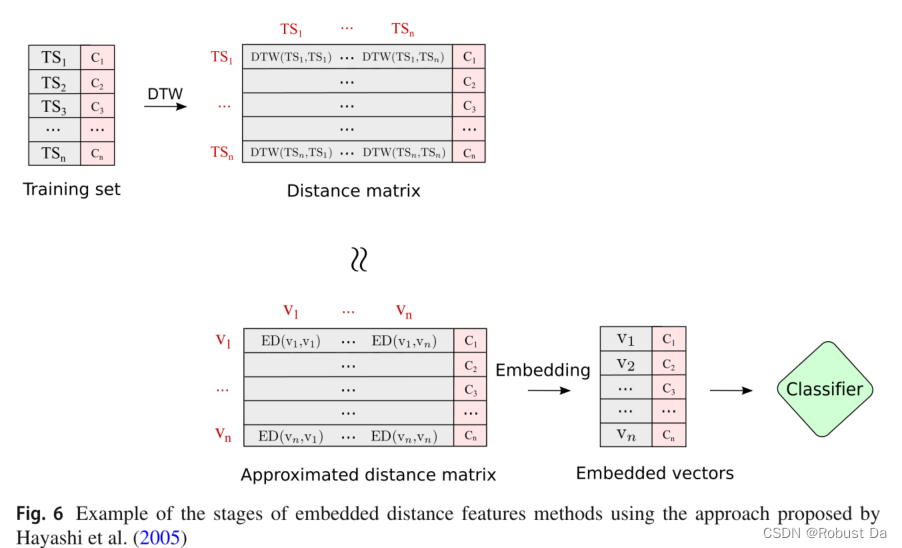
2.2.3 Embedded features
- The methods using Embedded features do not employ the distances directly as the new representation. Instead, they make use of them to obtain a new representation. In particular, the distances are used to isometrically(等度规地) embed the series into some Euclidean space while preserving the distances.
2.3 Distance kernels
- The methods within this category use the existing time series distances to obtain a kernel for time series.
2.3.1 An introduction to kernels
- Many machine learning algorithms require the data to be in feature vector form, while kernel methods require only a similarity function (known as kernel) expressing the similarity over pairs of input objects (Shawe-Taylor and Cristianini 2004).
- The main advantage of this approach is that one can handle any kind of data including vectors, matrices, or structured objects, such as sequences or graphs, by defining a suitable kernel which is able to capture the similarity between any two pairs of inputs.
- The idea behind a kernel is that if two inputs are similar, their output on the kernel will be similar, too.
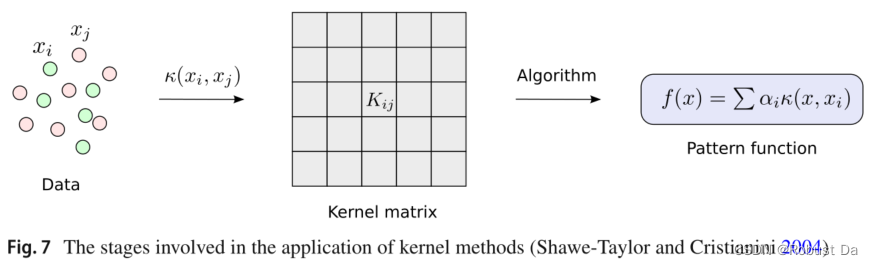
- Figure 7 shows the usage of the kernel function within a kernel method and the stages involved in the process. First, the kernel function is applied to the input objects in order to obtain a kernel matrix (also called Gram matrix), which is a similarity matrix with entries Kij = κ(xi, xj) for each input pair xi, xj. Then, this kernel matrix is used by the kernel method algorithm in order to produce a pattern function that is used to process unseen instances.
- Refer to a PSD kernel(Positive semi-definite kernel) as a definite kernel.
- However, a severe drawback of this approach is that the analysis is only performed for a particular set of instances, and it cannot be generalized.
2.3.2 Indefinite distance kernels
- The main goal of the methods in this category is to convert a time series distance measure into a kernel.
- The main drawback of learning with indefinite kernels is that the mathematical foundations of the kernel methods are not guaranteed (Ong et al. 2004).
- For time series classification, most of the work focuses on employing the distance kernels proposed by Haasdonk and Bahlmann (2004). They propose to replace the Euclidean distance in traditional kernel functions by the problem specific distance measure. They called these kernels distance substitution kernels.
- Within the methods employing indefinite kernels, there are different approaches, and for time series classification have been distinguished to three main directions (shown in Fig. 8).

2.3.3 Definite distance kernels
- Two main approaches: in the first, the concept of the alignment between series is exploited, while in the second, the direct construction of PSD kernels departing from a given distance measure is addressed.
3 Computational cost
- One of the most significant differences between distance based and non-distance based classification methods (from the point of view of the computational cost) is the time complexity of the prediction phase.
- In non-distance based methods, normally, the learning phase depends on the size of the training dataset but, once the model is learnt, the prediction of unlabeled instances does not depend on this dataset and is usually independent from the size of the dataset.
- In distance based classification, both the learning and the prediction stages computationally depend on the size of the dataset and on the chosen distance measure, so they must both be taken into account.
- In the shapelet based approaches, there are some preprocessing steps in order to obtain the features before the application of the classifier. In the learning phase, first, a shapelet discovery stage is carried out in which the best shapelets are learnt and, then, the pairwise distances between the series in the dataset and the obtained shapelets are computed.
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











