







目录
Options for Storing Connected Data CHAPTER 2
Relational Databases Lack Relationships
NOSQL Databases Also Lack Relationships
O-Notation and Brute-Force Processing
Graph Databases Embrace Relationships
Options for Storing Connected Data CHAPTER 2
我们生活在一个相互联系的世界里。为了繁荣和进步,我们需要理解和影响我们周围的关系网。当今的技术如何应对连接数据的挑战?在本章中接下来我们来看看关系数据库和聚合NOSQL存储是如何管理图的并将它们与图形数据库的性能进行比较。为有兴趣探究NOSQL主题的读者,附录A描述了NOSQL数据库的四种主要类型。
Relational Databases Lack Relationships
几十年来,开发人员一直试图整合(调节)连接的、半连接的-关系数据库中的结构化数据集。但是关系数据库最初的设计是为了编纂纸质表格和表格结构当他们试图模拟特殊的、特殊的现实世界中突然出现的关系。讽刺的是,关系数据库处理关系能力并不友好。关系确实存在于关系数据库的本地语言中,但仅作为连接表格的一种手段,更糟糕的是,随着离群数据的成倍增加,整体数据集的结构变得越来越复杂,越来越不统一模型中会有大量的连接表、稀疏的行和大量空检查逻辑。在关系世界中,连接性的上升转化为增加的连接,这会妨碍性能并使我们很难发展现有数据库以响应不断变化的业务需求。
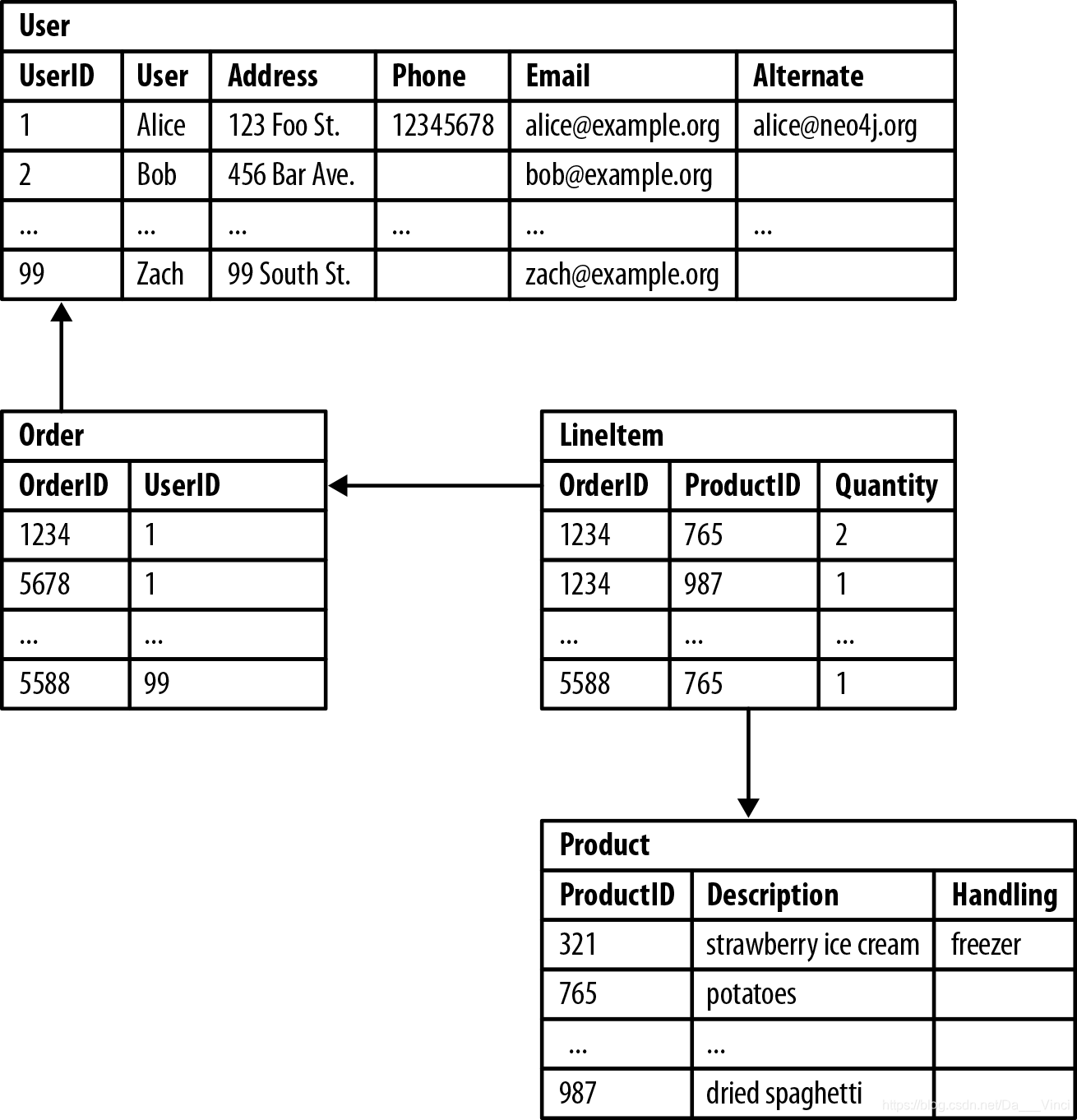
应用程序对该模式的设计产生了巨大的影响,使得一些查询非常容易,而其他查询则更加困难:
- 连接表增加了意外的复杂性;它们将业务数据与外键混合在一起。
- 外键限制增加了额外的开发和维护开销但只是为了让数据库正常工作。
- 具有可空列的稀疏表需要特殊的签入代码,尽管模式的存在。
- 为了发现客户购买了什么,需要几个昂贵的连接。
- 相互询问的成本更高。“顾客买了什么产品?“与“哪些顾客买了这个产品?“
在一个简单的社会网络数据库中,我们将难以估计在一个简单的社会网络中执行查询的成本。比如下面显示好友关系表
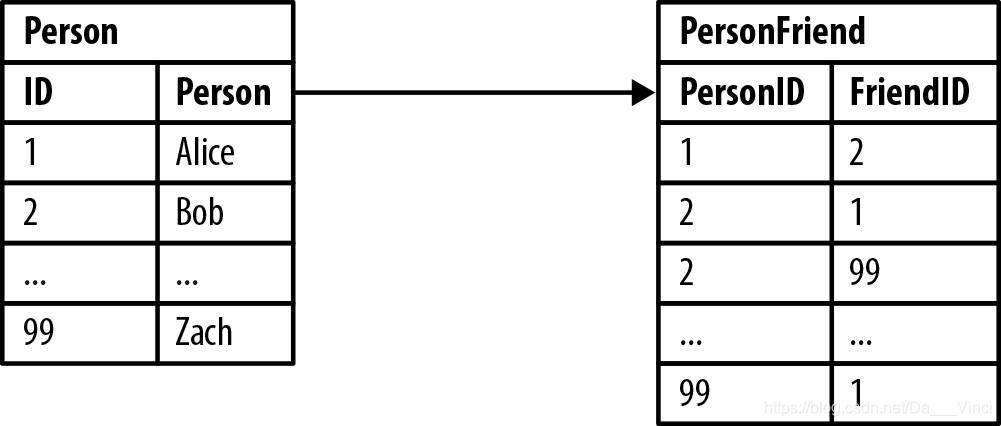
问“谁是鲍勃的朋友?“很容易

根据我们的样本数据,答案是爱丽丝和扎克。这不是一个特别昂贵或困难的查询,因为它使用filter WHERE来限制考虑中的行数

友谊并不总是一种反身关系,所以在例2-2中,我们询问对方的问题,即“谁是鲍勃的朋友?这个问题的答案是Alice;遗憾的是,Zach并不认为Bob是朋友。这个交互查询仍然很容易实现,但在数据库方面,它更昂贵因为数据库现在必须考虑PersonFriend表中的所有行。我们可以添加一个索引,但这仍然涉及一个昂贵的间接层。东西当我们问“谁是我朋友的朋友?”?”SQL中的层次结构使用递归连接,这使得查询在语法和com上假设更复杂,如例2-3所示。(一些关系数据库例如,甲骨文有一个CONNECT BY函数简化了查询,但不会降低潜在的计算复杂性。)

即使仅与Alice的朋友的朋友打交道,该查询在计算上也很复杂,并且不会深入到Alice的社交网络。我们进入网络越深入,事情就变得越复杂,越昂贵。虽然可以回答“谁是我的朋友的朋友?”这个问题的答案。在合理的时间内,由于递归联接表的计算和空间复杂性,扩展到四个,五个或六个友好度的查询会显着恶化。每当我们尝试在关系数据库中建模和查询连接性时,我们都会采取行动。除了上面概述的查询和计算复杂性外,我们还必须处理架构的双刃剑。 schema经常被证明既太僵硬又太脆。为了破坏其刚性,我们创建了具有许多可空列的稀疏填充表,并编写了代码来处理特殊情况-所有这些都是因为没有真正的“一刀切”的架构来容纳我们遇到的数据的多样性。这增加了耦合并且几乎破坏了任何内聚的表象。它的脆弱性表现为随着应用程序的发展从一种模式迁移到另一种模式所需的额外工作和精力。
NOSQL Databases Also Lack Relationships
大多数NOSQL数据库-断开连接的文档/值/列的键值,文档或面向列的存储集。 这使得很难将它们用于连接的数据和图形。向此类商店添加关系的一种众所周知的策略是将聚合的标识符嵌入到属于另一个聚合的字段中,从而有效地引入外键。 但是,这需要在应用程序级别加入聚合,这很快变得非常昂贵。当我们查看聚合存储模型(例如图2-3中的模型)时,我们想象可以看到关系。 在记录起始用户:Alice中看到对order:1234的引用,我们推断出用户:Alice与order:1234之间的连接。 这给了我们错误的希望,那就是我们可以使用键和值来管理图形。
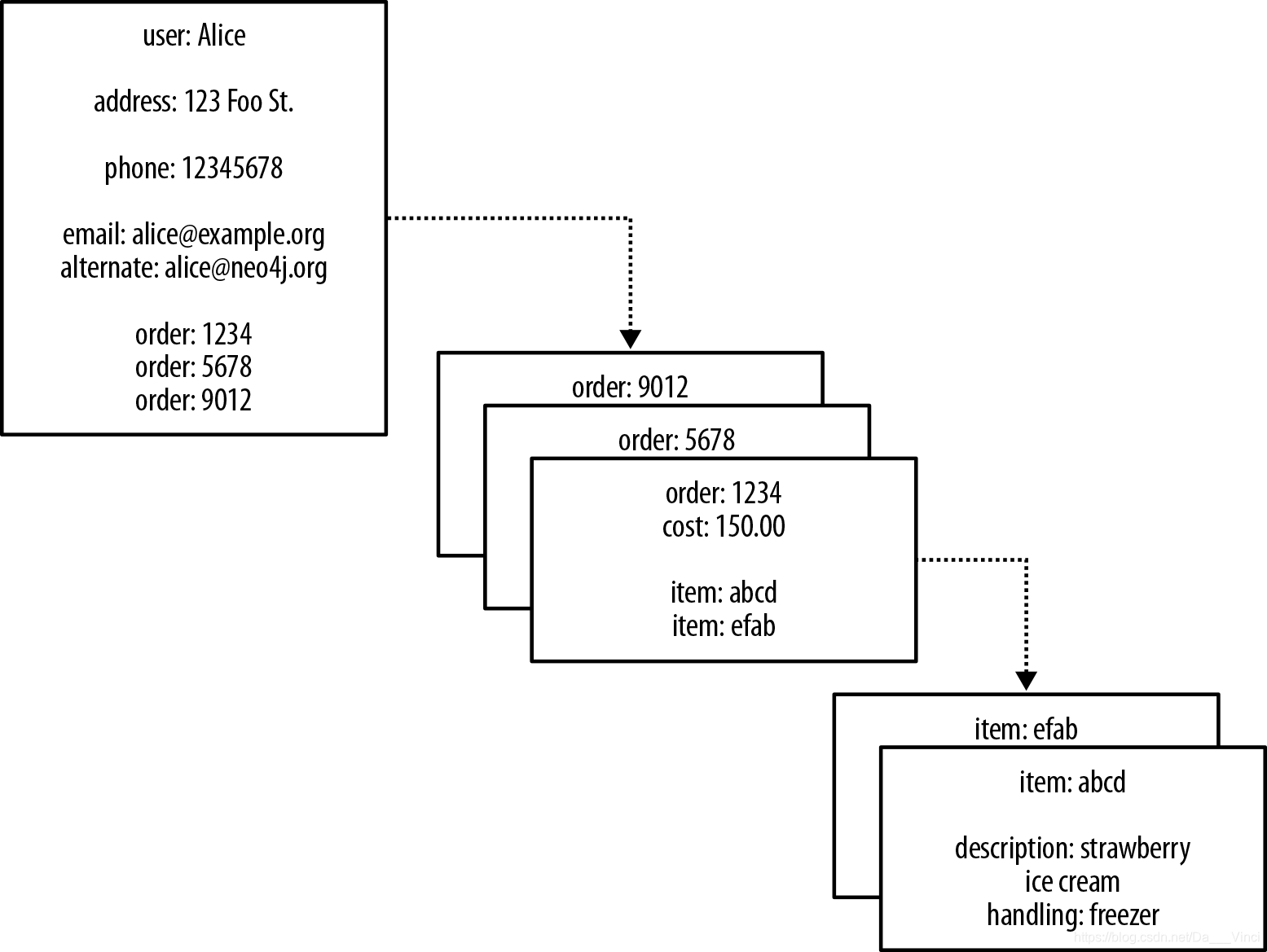
在图2-3中,我们推断某些属性值实际上是对数据库中其他位置的外部聚合的引用。 但是将这些推论转变为可导航的结构并不是免费的,因为聚合之间的关系并不是数据模型中的一等公民—大多数聚合存储仅以嵌套地图的形式提供具有结构的聚合内部。 取而代之的是,使用数据库的应用程序必须从这些平坦的,断开连接的数据结构中建立关系。 我们还必须确保应用程序与其余数据一起更新或删除这些外部集合引用。 如果这种情况没有发生,则商店将积累悬挂的参考,这会损害数据质量和查询性能。
Links and Walking
Riak键值存储允许使用链接元数据来扩充其每个存储的值。 每个链接都是单向的,从一个存储的值指向另一个。 Riak允许行走任意数量的这些链接(使用Riak术语),从而使模型有所关联。 但是,这种链接漫游是由map-reduce驱动的,它相对潜在。 与图形数据库不同,此链接仅适用于简单的图形结构编程,而不适用于常规图形算法。
该方案还有另一个弱点。因为没有“向后”指向的标识符(当然,外部聚合“链接”不是自反的),所以我们失去了在数据库上运行其他有趣查询的能力。例如,使用图2-3中所示的结构,询问数据库谁购买了特定产品(可能目的是基于客户资料提出建议)是一项昂贵的操作。如果我们想回答此类问题,我们可能最终会导出数据集并通过某些外部计算基础架构(例如Hadoop)对其进行处理,以蛮力计算结果。或者,我们可以回顾性地插入向后指向的外部聚合引用,然后查询结果。无论哪种方式,结果都是潜在的。人们很容易想到,聚合存储在功能上等同于图形数据库(对于连接的数据)。但这种情况并非如此。聚合存储不维护连接数据的一致性,也不支持所谓的无索引邻接,即元素包含指向其邻居的直接链接。结果,对于连接的数据问题,聚合存储必须使用固有的潜在方法来创建和查询数据模型外部的关系。让我们看看其中的一些局限性是如何表现出来的。图2-4显示了一个小型社交网络,该社交网络是使用聚合商店中的文档实现的。
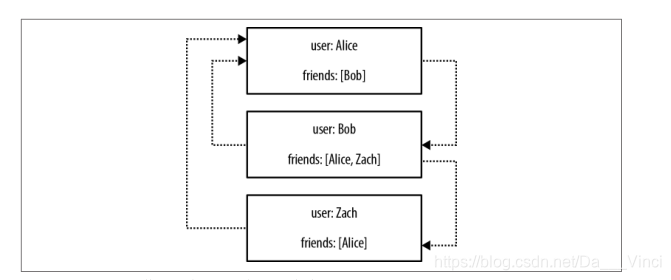
通过这种结构,很容易找到用户的直接好友,当然,该应用程序已经尽力确保存储在friends属性中的标识符与数据库中的其他记录ID一致。在这种情况下,我们只需按直系朋友的ID查找直属朋友,这需要大量索引查找(每个foreach朋友),而无需对整个数据集进行强力扫描。 这样做,例如,我们发现鲍勃认为爱丽丝和扎克是朋友。但是友谊并不总是对称的。 如果我们想问“谁和鲍勃是朋友?”该怎么办? 而不是“鲍勃的朋友是谁?” 这是一个较难回答的问题,在这种情况下,我们唯一的选择是对整个数据集进行暴力扫描,以查找包含Bob的朋友条目。
为了避免处理整个数据集,我们可以通过添加反向链接来对存储模型进行规范化。向每个用户添加第二个属性,也许称为friended_by,我们可以列出与该用户关联的传入友谊关系。但这不是免费的。对于初学者,我们必须支付增加的写延迟的初始和持续成本,以及用于存储其他元数据的增加的磁盘利用率。最重要的是,遍历链接仍然很昂贵,因为每个跃点都需要索引查找。这是因为聚合不具有局部性的概念,这与图形数据库不同,图形数据库自然通过真实(而不是固定的)关系提供无索引的邻接。通过在非本地商店上实现图结构,我们获得了部分连通性的一些好处,但是成本却很高。当涉及遍历深度超过一个跃点时,这种实质性成本会被放大。朋友很容易,但是想像一下要实时计算“朋友的朋友”或“朋友的朋友”。对于这种数据库,这是不切实际的,因为遍历假关系并不便宜。这不仅限制了您扩展社交网络的机会,还降低了可获利的建议,丢失了数据中心中的故障设备,并使欺诈性的购买活动通过网络流失了。许多系统都试图保持类似图形处理的外观,但是不可避免地要分批完成,并且不能提供用户所需的实时交互。
O-Notation and Brute-Force Processing
我们使用O表示法来描述算法的性能如何随数据集的大小而变化。 O(1)算法表现出恒定的时间性能;也就是说,无论
数据集的大小。
O(n)算法表现出线性性能;当数据集加倍时,执行算法所需的时间加倍。 O(log n)算法表现出对数性能;当数据集增加一倍时,执行算法所需的时间将增加固定量。
当数据集处于初期阶段时,相对性能的提高似乎代价很高,但随着数据集变得更大,它会迅速消失。 O(m log n)算法是本书中考虑的最昂贵的算法。使用O(m log n)算法,当数据集增加一倍时,执行时间将增加一倍,并增加与数据集中元素数量成正比的一些额外量。
由于必须考虑数据存储中的所有聚集,因此就复杂性而言,用蛮力计算整个数据集为O(n)。对于大多数合理大小的数据集来说,这太昂贵了,我们更喜欢O(log n)算法,该算法效率很高,因为它在每次迭代时都会丢弃一半的潜在工作负载,甚至更好。
相反,图数据库为同一查询提供恒定顺序的查询。在这种情况下,我们只需在图中找到代表Bob的节点,然后遵循所有传入的朋友关系即可;这些关系导致结点代表代表认为Bob是他们的朋友的人。
这比暴力破解结果便宜得多,因为它认为网络的成员要少得多。也就是说,它仅考虑连接到Bob的那些。当然,如果每个人都是Bob的朋友,我们仍然会考虑整个数据集。
Graph Databases Embrace Relationships
前面的示例处理了隐式连接的数据。 作为用户,我们可以推断实体之间的语义依赖性,但是数据模型以及数据库本身对这些连接是看不见的。 为了弥补这一损失,我们的应用程序必须从平坦的,断开连接的数据中创建一个网络,然后处理出现在非规范化存储中的所有慢速查询和潜在写入。
我们真正想要的是整体的凝聚力图景,包括元素之间的联系。 与我们刚刚看过的商店相反,在图表世界中,关联数据存储为关联数据。 域中存在连接的地方,数据中也存在连接。 例如,考虑图2-5中所示的社交网络。
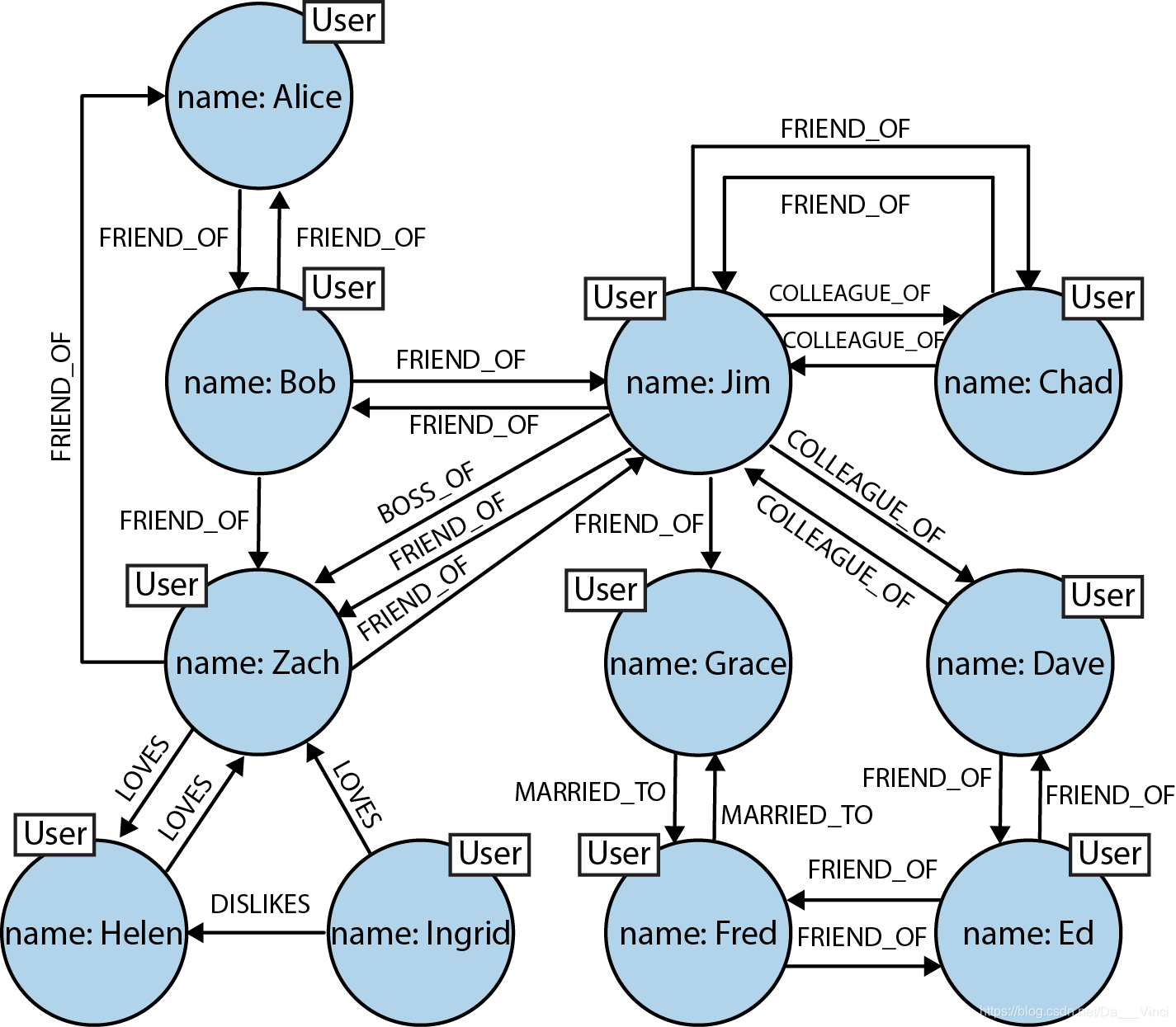
在这种社交网络中,就像在现实世界中连接数据的许多情况下一样,实体之间的连接在整个域中并没有表现出统一性-域是可变结构的。社交网络是紧密连接,可变结构的网络的流行示例,该网络拒绝被一种一刀切的全能模式捕获或方便地拆分为多个断开的聚合体。我们简单的朋友网络的规模不断扩大(现在,潜在的朋友可以达到6度),富有表现力。图模型的灵活性使我们能够添加新节点和新关系,而不会损害现有网络或迁移数据-原始数据及其意图保持不变。
该图提供了更丰富的网络图。我们可以看到谁爱谁(以及这种爱是否得到回报)。我们可以看到谁是COLLEAGUE_OF谁,谁是BOSS_OF。我们可以看到谁在市场之外,因为他们是MARRIED_TO其他人;我们甚至可以看到以DISLIKES关系为代表的社会网络中的反社会元素。有了这个图形,我们现在可以查看图形数据库在处理连接数据时的性能优势。
图中的关系自然形成路径。 查询(或遍历)图形涉及以下路径。 由于数据模型从根本上讲是面向路径的,因此大多数基于路径的图形数据库操作都与数据的布局方式高度一致,从而使其极为高效。 Partner和Vukotic在他们的《行动中的Neo4j》一书中使用关系商店和Neo4j进行了实验。 比较表明,图数据库(在本例中为Neo4j及其Traversal Framework)对于关联数据而言比关系存储要快得多。
合作伙伴和Vukotic的实验旨在在社交网络中找到朋友的朋友,最大深度为5。 对于包含1,000,000人且每个人约有50个朋友的社交网络,结果强烈表明,图数据库是连接数据的最佳选择,如表2-1所示。
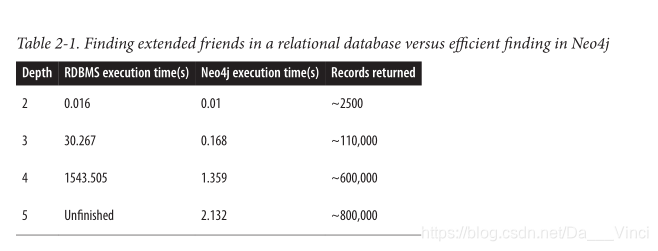
在第二层(朋友的朋友),关系数据库和图形数据库的性能都足够好,我们可以考虑在在线系统中使用它们。尽管Neo4j查询的运行时间是关系查询的三分之二,但最终用户几乎不会注意到两者之间的毫秒差。但是,到了深度三(朋友的朋友)时,很明显,关系数据库不再能够在合理的时间范围内处理查询:完成这30秒将完全在线系统无法接受。相比之下,Neo4j的响应时间却相对平稳:执行查询只需几分之一秒,对于在线系统而言绝对足够快。
在深度四处,关系数据库表现出严重的延迟,这使其对于在线系统几乎没有用。 Neo4j的时间安排也略有恶化,但此处的延迟处于响应型在线系统可接受的范围之内。最后,在深度五处,关系数据库仅花费很长时间才能完成查询。相反,Neo4j在大约两秒钟内返回结果。在深度5,事实证明几乎整个网络都是我们的朋友。因此,对于许多实际使用案例,我们可能会调整结果,从而减少时间
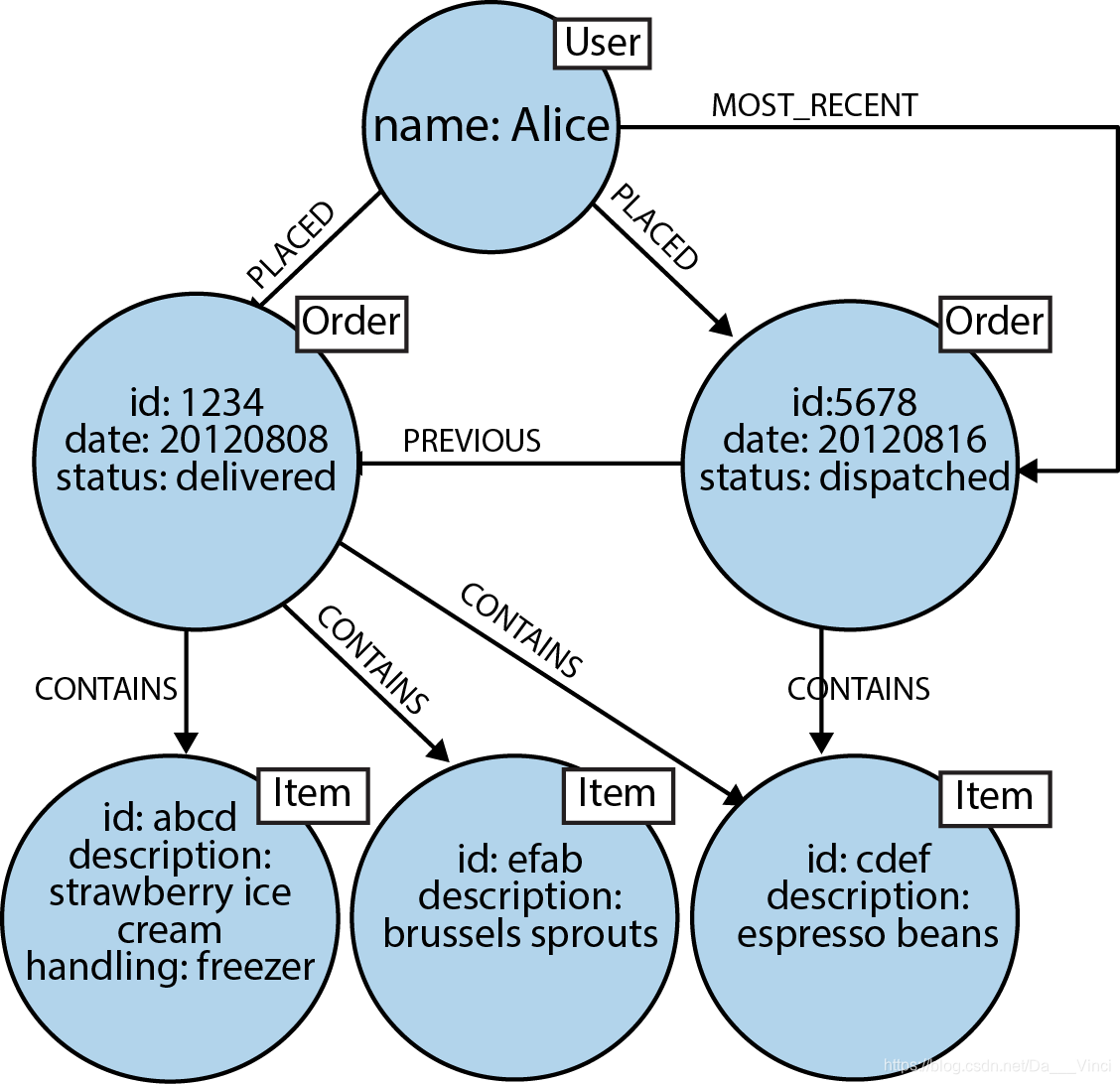
社交网络示例有助于说明不同的技术如何处理连接的数据,但这是有效的用例吗?我们真的需要找到这样的远程“朋友”吗?也许不是。但是,用其他任何域替换社交网络,您都会看到我们在性能,建模和维护方面都享有类似的好处。无论是音乐或数据中心管理,生物信息学或足球统计数据,网络传感器还是行业时间序列,图表都可以为我们的数据提供强大的洞察力。然后,让我们看一下图表的另一种当代应用:根据用户的购买历史以及他的朋友,邻居和其他类似他的历史来推荐产品。在此示例中,我们将用户生活方式的几个独立方面放在一起,以提出准确且有利可图的建议。我们首先将用户的购买历史建模为关联数据。在图形中,这就像将用户链接到她的订单,然后将订单链接在一起以提供购买历史记录一样简单,如图2-6所示。
图2-6中显示的图形提供了对客户行为的大量洞察。我们可以看到用户已下订单的所有订单,并且我们可以轻松推断每个订单包含哪些内容。然后,在此核心域数据结构中,我们添加了对几种众所周知的访问模式的支持。例如,用户经常想查看他们的订单历史记录,因此我们在图表中添加了一个链接列表结构,该结构使我们能够通过遵循传出的MOST_RECENT关系来查找用户的最新订单。然后,我们可以通过跟踪每个PREVI OUS关系来遍历列表,以进一步追溯到过去。如果我们想及时前进,我们可以沿相反的方向遵循每个上一个关系,或者添加一个互惠的下一个关系。现在我们可以开始提出建议了。如果我们发现许多购买草莓冰淇淋的用户也购买了特浓咖啡,我们可以开始向通常只购买冰淇淋的用户推荐这些咖啡豆。但这只是一个一维的建议:我们可以做得更好。为了增加图表的功能,我们可以将其加入其他域的图表。由于图自然是多维结构,因此可以轻松询问更复杂的数据问题,以访问经过微调的细分市场。例如,我们可以要求该图为我们找到“那些喜欢浓咖啡但不喜欢抱子甘蓝的人,并且居住在特定社区的人们喜欢的所有冰淇淋口味。”
为了解释数据,我们可以考虑某人重复购买某种产品的程度来表明他们是否喜欢该产品。 但是我们如何定义“住在附近”呢? 好吧,事实证明,地理空间坐标非常方便地建模为图形。 用于表示地理空间坐标的最受欢迎的结构之一称为R树。 RTree是一种类似图的索引,它描述了地理周围的有界框。 使用这种结构,我们可以描述重叠的位置层次结构。 例如,我们可以表示一个事实,即伦敦位于英国,而邮政编码SW11 1BD位于巴特西,后者是伦敦的一个地区,位于英国的东南部,而英格兰又位于英国的东南部。 而且由于英国邮政编码是细粒度的,因此我们可以使用该边界来定位具有相似品味的人群。
我们可以使用示例图向用户提出建议,但也可以使用它使卖方受益。 例如,给定特定的购买模式(产品,典型订单的成本等),我们可以确定特定交易是否具有欺诈性。 可以轻松地在图形中检测出给定用户超出规范的模式,然后将其标记出来以供进一步关注(使用图形数据挖掘文献中的众所周知的相似性度量),从而降低了卖方的风险。
从数据从业者的角度来看,很明显,图形数据库是处理复杂,可变结构,紧密连接的数据的最佳技术,即,数据集非常复杂,以图形以外的任何形式处理时都不方便。
Summary
在本章中,我们已经了解了关系数据库和NOSQL数据存储中的连接性如何要求开发人员在应用程序层中实现数据处理,并与图数据库进行了对比,在图数据库中,连接性是一等公民。 关于图形建模的更多详细信息。


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











