







java11+neo4j4.3+gds1.6
https://download.csdn.net/download/Da___Vinci/19887360原文
https://neo4j.com/docs/graph-data-science/current/installation/译文
-------------------------------------------------------------------------------
安装
本章提供了 Neo4j Graph Data Science 库的安装和基本使用说明。
Neo4j Graph Data Science (GDS) 库作为 Neo4j Graph Database 的插件提供。该插件需要安装到数据库中并在 Neo4j 配置中列入白名单。有两种主要方法可以实现这一点,我们将在本章中详细介绍。
1. 支持的 Neo4j 版本
2. Neo4j 桌面
安装 GDS 库最方便的方法是通过名为 Neo4j Graph Data Science的Neo4j 桌面插件。该插件可以在数据库的“插件”选项卡中找到。
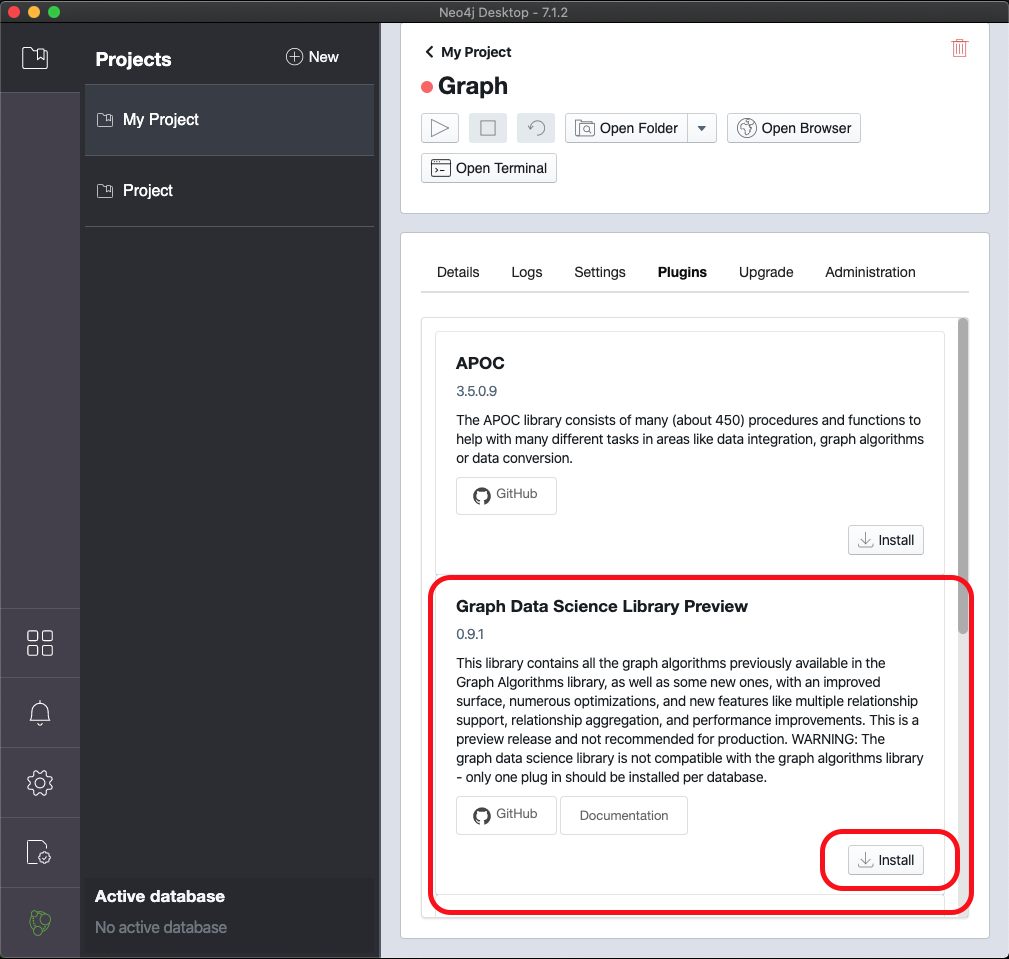
安装程序将下载 GDS 库并将其安装在数据库的“插件”目录中。它还会将以下条目添加到设置文件中:
dbms.security.procedures.unrestricted=gds.*此配置条目是必需的,因为 GDS 库访问 Neo4j 的低级组件以最大化性能。
如果配置了程序白名单,请确保还包括 GDS 库中的程序:
dbms.security.procedures.whitelist=gds.*3. Neo4j 服务器
GDS 库旨在用于独立的 Neo4j 服务器。
|
不支持在 Neo4j 因果集群中运行 GDS 库。了解更多关于如何结合使用GDS与Neo4j的因果集群部署下方。 |
在独立的 Neo4j 服务器上,需要手动安装和配置库。
-
下载
neo4j-graph-data-science-[version].jar从Neo4j的下载中心,并将其复制到$NEO4J_HOME/plugins目录中。 -
将以下内容添加到您的
$NEO4J_HOME/conf/neo4j.conf文件中:dbms.security.procedures.unrestricted=gds.*此配置条目是必需的,因为 GDS 库访问 Neo4j 的低级组件以最大化性能。
-
检查
$NEO4J_HOME/conf/neo4j.conf文件中是否启用了程序白名单,并在必要时添加 GDS 库:dbms.security.procedures.whitelist=gds.* -
重启 Neo4j
3.1. 验证安装
为了验证您的安装,可以通过在 Neo4j Desktop 中进入浏览器并调用gds.version()函数来打印库版本:
RETURN gds.version()要列出所有已安装的算法,请运行以下gds.list()过程:
CALL gds.list()4.企业版配置
解锁 Neo4j Graph Data Science 库的企业版需要有效的许可证密钥。要注册许可证,请通过https://neo4j.com/contact-us/?ref=graph-analytics联系 Neo4j 。
许可证以许可证密钥文件的形式发放,需要放在Neo4j服务器可以访问的目录中。您可以通过gds.enterprise.license_file在neo4j.confNeo4j 安装的配置文件中设置选项来配置许可证密钥文件的位置。必须使用绝对路径指定位置。首次配置许可证密钥时以及每次更改许可证密钥时,例如添加新的许可证密钥或密钥文件的位置更改时,都需要重新启动数据库。
许可证密钥文件的示例配置:
gds.enterprise.license_file=/path/to/my/license/keyfile如果该gds.enterprise.license_file设置设置为非空值,Neo4j Graph Data Science 库将验证许可证密钥文件是否可访问并包含有效的许可证密钥。配置有效的许可证密钥后,所有企业版功能都将解锁。如果出现问题,例如,当许可证密钥文件不可访问、许可证已过期或由于任何其他原因无效时,所有对 Neo4j 图形数据科学库的调用都将导致错误,说明许可证密钥有问题.
5. Neo4j Docker
Neo4j Graph Data Science 库可用作 Docker 上 Neo4j 的插件。Docker 的插件指南可在操作手册中找到。
要运行具有可用 GDS 的 Neo4j 容器,您可以运行
docker run -it --rm \
--publish=7474:7474 --publish=7687:7687 \
--user="$(id -u):$(id -g)" \
-e NEO4J_AUTH=none \
--env NEO4JLABS_PLUGINS='["graph-data-science"]' \
neo4j:4.26. Neo4j 因果集群
Neo4j 因果集群由多台机器组成,这些机器共同支持一个高可用的数据库管理系统。GDS 库使用单台机器上的主内存来托管图形目录中的图形和基于这些的计算算法。这两种架构不兼容,不应结合使用。GDS 工作负载会在运行时尝试消耗机器的大部分系统资源,这可能会使机器长时间无响应。由于这些原因,我们强烈建议不要在集群中运行 GDS,因为这可能会导致数据损坏或集群中断。
要在 Neo4j 因果集群部署托管的图形上使用 GDS,这些图形应该与正在运行的集群分离。这可以通过多种方式实现,包括:
-
转储 Neo4j 存储的快照并将其导入单独的独立 Neo4j 服务器中。
-
将只读副本添加到 Neo4j 因果集群,然后将其分离以在与 Neo4j 因果集群分离的快照上安全地操作 GDS。
-
将只读副本添加到 Neo4j 因果集群并为 GDS 工作负载配置它。请注意,由于只读副本的更新,内存图和底层数据库最终将变得不同步。由于 GDS 可以消耗所有可用资源,因此只读副本的响应速度可能会降低,并且其状态可能会落后于集群。在这种情况下使用 GDS 需要:
-
在只读副本上安装 GDS
-
使用 mutate 或流调用模式
-
通过 Cypher 直接使用 GDS 工作负载的结果(请参阅实用程序函数)
-
不使用 GDS 回写功能(写入会触发许多大型事务并可能终止集群)
-
在分离的机器上完成 GDS 工作负载后(对于案例 1. 和 2.),它现在包含从 Neo4j 因果集群写入其复制图版本的不同步结果。要将这些结果集成回集群,需要自定义程序。
7. 附加配置选项
8. 系统要求
8.1. 主存储器
GDS 库在 Neo4j 实例中运行,因此受制于一般Neo4j 内存配置。
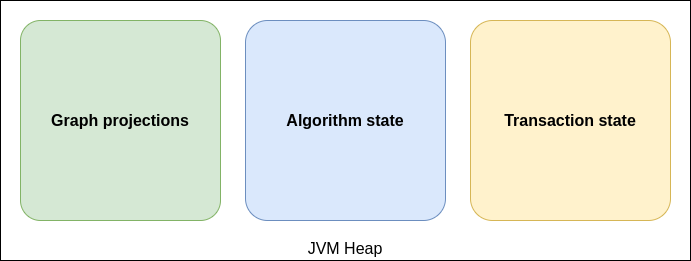
8.1.1. 堆大小
堆空间用于存储图目录和算法状态中的图投影。将算法结果写回 Neo4j 时,堆空间也用于处理事务状态(参见dbms.tx_state.memory_allocation)。对于纯分析工作负载,一般建议将堆空间设置为可用主内存的 90% 左右。这可以通过dbms.memory.heap.initial_size和dbms.memory.heap.max_size来完成。
为了更好地估计创建内存图和运行算法所需的堆空间,请考虑内存估计功能。该功能使用来自 Neo4j 计数存储的节点数量和关系的信息来估计所有涉及的数据结构的内存消耗。
8.1.2. 页面缓存
页面缓存用于缓存 Neo4j 数据,有助于避免代价高昂的磁盘访问。
对于使用本机投影的纯分析工作负载,建议减少dbms.memory.pagecache.size以支持增加堆大小。但是,在创建内存图时,设置最小页面缓存大小仍然很重要:
但是,如果需要将算法结果写回 Neo4j,则写入性能高度依赖于存储碎片以及要写入的属性和关系的数量。我们建议从大致的页面缓存大小开始,250MB * writeConcurrency评估写入性能并相应地进行调整。理想情况下,如果内存估计功能已用于找到合适的堆大小,则剩余内存可用于页面缓存和操作系统。
|
如果 Neo4j 实例同时运行操作和分析工作负载,则不建议减少页面缓存大小以支持堆大小。有关页面缓存大小的一般信息,请参阅Neo4j 内存配置。 |
8.2. 中央处理器
该库使用多个 CPU 内核进行图形投影、算法计算和结果写入。配置工作负载以充分利用系统中可用的 CPU 内核对于实现最高性能非常重要。用于投影、计算和写入阶段的并发是按算法执行配置的,请参阅通用配置参数
可以使用的最大并发数取决于使用库的许可证:
-
Neo4j 社区版
-
库中的最大并发数为 4。
-
-
Neo4j 企业版
-
库中的最大并发数为 4。
-
-
Neo4j 图数据科学库 - 企业版
-
库中的并发是无限的。要注册许可证,请通过https://neo4j.com/contact-us/?ref=graph-analytics联系 Neo4j 。
-


















 5667
5667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











